 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Speech Tokenizers with Diffusion Autoencoders
Feb 06, 2026Speech tokenizers are foundational to speech language models, yet existing approaches face two major challenges: (1) balancing trade-offs between encoding semantics for understanding and acoustics for reconstruction, and (2) achieving low bit rates and low token rates. We propose Speech Diffusion Tokenizer (SiTok), a diffusion autoencoder that jointly learns semantic-rich representations through supervised learning and enables high-fidelity audio reconstruction with diffusion. We scale SiTok to 1.6B parameters and train it on 2 million hours of speech. Experiments show that SiTok outperforms strong baselines on understanding, reconstruction and generation tasks, at an extremely low token rate of $12.5$ Hz and a bit-rate of 200 bits-per-second.
ReViP: Reducing False Completion in Vision-Language-Action Models with Vision-Proprioception Rebalance
Jan 23, 2026Vision-Language-Action (VLA) models have advanced robotic manipulation by combining vision, language, and proprioception to predict actions. However, previous methods fuse proprioceptive signals directly with VLM-encoded vision-language features, resulting in state-dominant bias and false completions despite visible execution failures. We attribute this to modality imbalance, where policies over-rely on internal state while underusing visual evidence. To address this, we present ReViP, a novel VLA framework with Vision-Proprioception Rebalance to enhance visual grounding and robustness under perturbations. The key insight is to introduce auxiliary task-aware environment priors to adaptively modulate the coupling between semantic perception and proprioceptive dynamics. Specifically, we use an external VLM as a task-stage observer to extract real-time task-centric visual cues from visual observations, which drive a Vision-Proprioception Feature-wise Linear Modulation to enhance environmental awareness and reduce state-driven errors. Moreover, to evaluate false completion, we propose the first False-Completion Benchmark Suite built on LIBERO with controlled settings such as Object-Drop. Extensive experiments show that ReViP effectively reduces false-completion rates and improves success rates over strong VLA baselines on our suite, with gains extending to LIBERO, RoboTwin 2.0, and real-world evaluations.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
MSQA: Benchmarking LLMs on Graduate-Level Materials Science Reasoning and Knowledge
May 29, 2025



Despite recent advances in large language models (LLMs) for materials science, there is a lack of benchmarks for evaluating their domain-specific knowledge and complex reasoning abilities. To bridge this gap, we introduce MSQA, a comprehensive evaluation benchmark of 1,757 graduate-level materials science questions in two formats: detailed explanatory responses and binary True/False assessments. MSQA distinctively challenges LLMs by requiring both precise factual knowledge and multi-step reasoning across seven materials science sub-fields, such as structure-property relationships, synthesis processes, and computational modeling. Through experiments with 10 state-of-the-art LLMs, we identify significant gaps in current LLM performance. While API-based proprietary LLMs achieve up to 84.5% accuracy, open-source (OSS) LLMs peak around 60.5%, and domain-specific LLMs often underperform significantly due to overfitting and distributional shifts. MSQA represents the first benchmark to jointly evaluate the factual and reasoning capabilities of LLMs crucial for LLMs in advanced materials science.
MLE-Dojo: Interactive Environments for Empowering LLM Agents in Machine Learning Engineering
May 12, 2025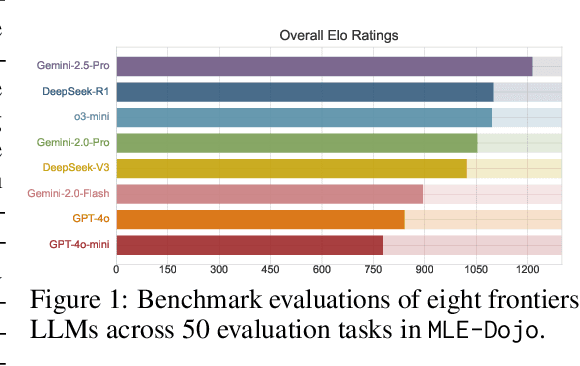



We introduce MLE-Dojo, a Gym-style framework for systematically reinforcement learning, evaluating, and improving autonomous large language model (LLM) agents in iterative machine learning engineering (MLE) workflows. Unlike existing benchmarks that primarily rely on static datasets or single-attempt evaluations, MLE-Dojo provides an interactive environment enabling agents to iteratively experiment, debug, and refine solutions through structured feedback loops. Built upon 200+ real-world Kaggle challenges, MLE-Dojo covers diverse, open-ended MLE tasks carefully curated to reflect realistic engineering scenarios such as data processing, architecture search, hyperparameter tuning, and code debugging. Its fully executable environment supports comprehensive agent training via both supervised fine-tuning and reinforcement learning, facilitating iterative experimentation, realistic data sampling, and real-time outcome verification. Extensive evaluations of eight frontier LLMs reveal that while current models achieve meaningful iterative improvements, they still exhibit significant limitations in autonomously generating long-horizon solutions and efficiently resolving complex errors. Furthermore, MLE-Dojo's flexible and extensible architecture seamlessly integrates diverse data sources, tools, and evaluation protocols, uniquely enabling model-based agent tuning and promoting interoperability, scalability, and reproducibility. We open-source our framework and benchmarks to foster community-driven innovation towards next-generation MLE agents.
Language Model Uncertainty Quantification with Attention Chain
Mar 24, 2025Accurately quantifying a large language model's (LLM) predictive uncertainty is crucial for judging the reliability of its answers. While most existing research focuses on short, directly answerable questions with closed-form outputs (e.g., multiple-choice), involving intermediate reasoning steps in LLM responses is increasingly important. This added complexity complicates uncertainty quantification (UQ) because the probabilities assigned to answer tokens are conditioned on a vast space of preceding reasoning tokens. Direct marginalization is infeasible, and the dependency inflates probability estimates, causing overconfidence in UQ. To address this, we propose UQAC, an efficient method that narrows the reasoning space to a tractable size for marginalization. UQAC iteratively constructs an "attention chain" of tokens deemed "semantically crucial" to the final answer via a backtracking procedure. Starting from the answer tokens, it uses attention weights to identify the most influential predecessors, then iterates this process until reaching the input tokens. Similarity filtering and probability thresholding further refine the resulting chain, allowing us to approximate the marginal probabilities of the answer tokens, which serve as the LLM's confidence. We validate UQAC on multiple reasoning benchmarks with advanced open-source LLMs, demonstrating that it consistently delivers reliable UQ estimates with high computational efficiency.
Extrapolation Merging: Keep Improving With Extrapolation and Merging
Mar 05, 2025Large Language Models (LLMs) require instruction fine-tuning to perform different downstream tasks. However, the instruction fine-tuning phase still demands significant computational resources and labeled data, lacking a paradigm that can improve model performance without additional computational power and data. Model merging aims to enhance performance by combining the parameters of different models, but the lack of a clear optimization direction during the merging process does not always guarantee improved performance. In this paper, we attempt to provide a clear optimization direction for model merging. We first validate the effectiveness of the model extrapolation method during the instruction fine-tuning phase. Then, we propose Extrapolation Merging, a paradigm that can continue improving model performance without requiring extra computational resources or data. Using the extrapolation method, we provide a clear direction for model merging, achieving local optimization search, and consequently enhancing the merged model's performance. We conduct experiments on seven different tasks, and the results show that our method can consistently improve the model's performance after fine-tuning.
SRA-MCTS: Self-driven Reasoning Augmentation with Monte Carlo Tree Search for Code Generation
Nov 21, 2024Large language models demonstrate exceptional performance in simple code generation tasks but still face challenges in tackling complex problems. These challenges may stem from insufficient reasoning and problem decomposition capabilities. To address this issue, we propose a reasoning-augmented data generation process, SRA-MCTS, which guides the model to autonomously generate high-quality intermediate reasoning paths. This creates a positive feedback loop, enabling continuous improvement. Our method operates entirely through the model itself without requiring additional supervision. By synthesizing natural language reasoning paths and translating them into executable code, the approach ensures analytical accuracy and enhances the success rate in solving complex tasks. Experimental results show that, even without additional supervisory signals, our method achieves performance improvements across different model scales, demonstrating the significant potential of self-improvement in small models. Furthermore, the method remains robust when traditional Chain-of-Thought (CoT) approaches exhibit performance degradation, with notable improvements observed in diversity metrics such as pass@10. We encourage further exploration of reasoning processes within training data to enhance the ability of language models to address complex problems.
Word Matters: What Influences Domain Adaptation in Summarization?
Jun 21, 2024Domain adaptation aims to enable Large Language Models (LLMs) to generalize domain datasets unseen effectively during the training phase. However, factors such as the size of the model parameters and the scale of training data are general influencers and do not reflect the nuances of domain adaptation performance. This paper investigates the fine-grained factors affecting domain adaptation performance, analyzing the specific impact of `words' in training data on summarization tasks. We propose quantifying dataset learning difficulty as the learning difficulty of generative summarization, which is determined by two indicators: word-based compression rate and abstraction level. Our experiments conclude that, when considering dataset learning difficulty, the cross-domain overlap and the performance gain in summarization tasks exhibit an approximate linear relationship, which is not directly related to the number of words. Based on this finding, predicting a model's performance on unknown domain datasets is possible without undergoing training.
How Far Can In-Context Alignment Go? Exploring the State of In-Context Alignment
Jun 17, 2024Recent studies have demonstrated that In-Context Learning (ICL), through the use of specific demonstrations, can align Large Language Models (LLMs) with human preferences known as In-Context Alignment (ICA), indicating that models can comprehend human instructions without requiring parameter adjustments. However, the exploration of the mechanism and applicability of ICA remains limited. In this paper, we begin by dividing the context text used in ICA into three categories: format, system prompt, and example. Through ablation experiments, we investigate the effectiveness of each part in enabling ICA to function effectively. We then examine how variants in these parts impact the model's alignment performance. Our findings indicate that the example part is crucial for enhancing the model's alignment capabilities, with changes in examples significantly affecting alignment performance. We also conduct a comprehensive evaluation of ICA's zero-shot capabilities in various alignment tasks. The results indicate that compared to parameter fine-tuning methods, ICA demonstrates superior performance in knowledge-based tasks and tool-use tasks. However, it still exhibits certain limitations in areas such as multi-turn dialogues and instruction following.