 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEFT-U: Parameter-Efficient Fine-Tuning for User Personalization
Jul 25, 2024The recent emergence of Large Language Models (LLMs) has heralded a new era of human-AI interaction. These sophisticated models, exemplified by Chat-GPT and its successors, have exhibited remarkable capabilities in language understanding. However, as these LLMs have undergone exponential growth, a crucial dimension that remains understudied is the personalization of these models. Large foundation models such as GPT-3 etc. focus on creating a universal model that serves a broad range of tasks and users. This approach emphasizes the model's generalization capabilities, treating users as a collective rather than as distinct individuals. While practical for many common applications, this one-size-fits-all approach often fails to address the rich tapestry of human diversity and individual needs. To explore this issue we introduce the PEFT-U Benchmark: a new dataset for building and evaluating NLP models for user personalization. \datasetname{} consists of a series of user-centered tasks containing diverse and individualized expressions where the preferences of users can potentially differ for the same input. Using PEFT-U, we explore the challenge of efficiently personalizing LLMs to accommodate user-specific preferences in the context of diverse user-centered tasks.
Unveiling the Spectrum of Data Contamination in Language Models: A Survey from Detection to Remediation
Jun 20, 2024

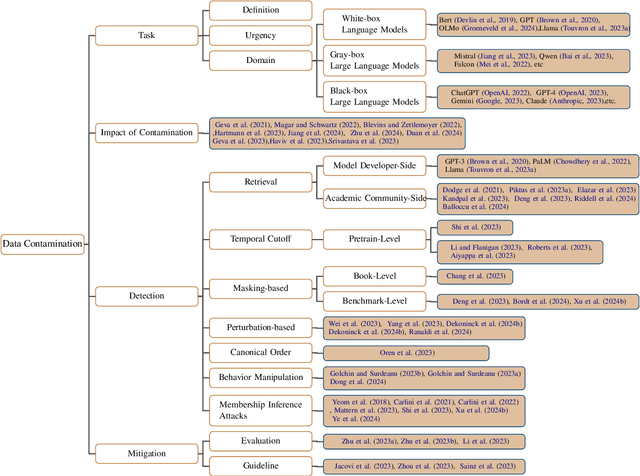
Data contamination has garnered increased attention in the era of large language models (LLMs) due to the reliance on extensive internet-derived training corpora. The issue of training corpus overlap with evaluation benchmarks--referred to as contamination--has been the focus of significant recent research. This body of work aims to identify contamination, understand its impacts, and explore mitigation strategies from diverse perspectives. However, comprehensive studies that provide a clear pathway from foundational concepts to advanced insights are lacking in this nascent field. Therefore, we present a comprehensive survey in the field of data contamination, laying out the key issues, methodologies, and findings to date, and highlighting areas in need of further research and development. In particular, we begin by examining the effects of data contamination across various stages and forms. We then provide a detailed analysis of current contamination detection methods, categorizing them to highlight their focus, assumptions, strengths, and limitations. We also discuss mitigation strategies, offering a clear guide for future research. This survey serves as a succinct overview of the most recent advancements in data contamination research, providing a straightforward guide for the benefit of future research endeavors.
ProgGen: Generating Named Entity Recognition Datasets Step-by-step with Self-Reflexive Large Language Models
Mar 17, 2024Although Large Language Models (LLMs) exhibit remarkable adaptability across domains, these models often fall short in structured knowledge extraction tasks such as named entity recognition (NER). This paper explores an innovative, cost-efficient strategy to harness LLMs with modest NER capabilities for producing superior NER datasets. Our approach diverges from the basic class-conditional prompts by instructing LLMs to self-reflect on the specific domain, thereby generating domain-relevant attributes (such as category and emotions for movie reviews), which are utilized for creating attribute-rich training data. Furthermore, we preemptively generate entity terms and then develop NER context data around these entities, effectively bypassing the LLMs' challenges with complex structures. Our experiments across both general and niche domains reveal significant performance enhancements over conventional data generation methods while being more cost-effective than existing alternatives.
Label Agnostic Pre-training for Zero-shot Text Classification
May 25, 2023
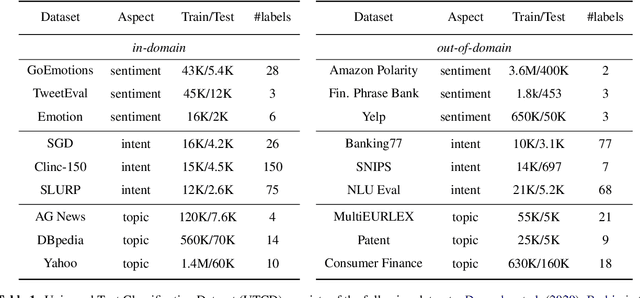

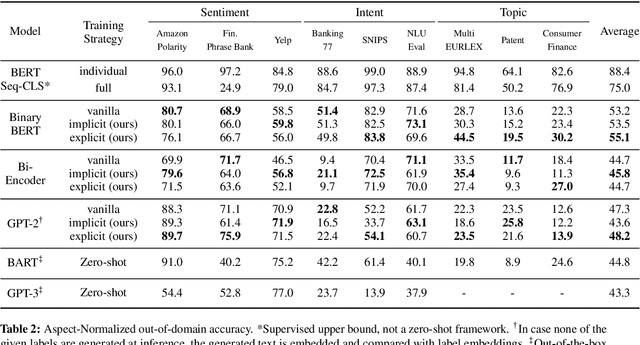
Conventional approaches to text classification typically assume the existence of a fixed set of predefined labels to which a given text can be classified. However, in real-world applications, there exists an infinite label space for describing a given text. In addition, depending on the aspect (sentiment, topic, etc.) and domain of the text (finance, legal, etc.), the interpretation of the label can vary greatly. This makes the task of text classification, particularly in the zero-shot scenario, extremely challenging. In this paper, we investigate the task of zero-shot text classification with the aim of improving the ability of pre-trained language models (PLMs) to generalize to both seen and unseen data across varying aspects and domains. To solve this we introduce two new simple yet effective pre-training strategies, Implicit and Explicit pre-training. These methods inject aspect-level understanding into the model at train time with the goal of conditioning the model to build task-level understanding. To evaluate this, we construct and release UTCD, a new benchmark dataset for evaluating text classification in zero-shot settings. Experimental results on UTCD show that our approach achieves improved zero-shot generalization on a suite of challenging datasets across an array of zero-shot formalizations.