 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLMEval: Entropy-Based Calibration for Human-Aligned Evaluation of Large Language Models
May 21, 2025
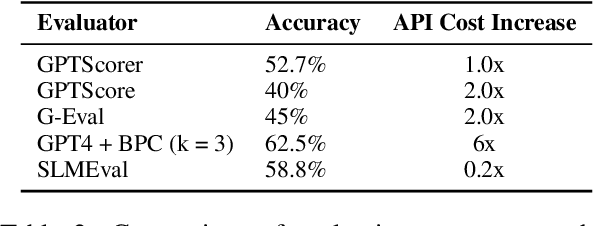
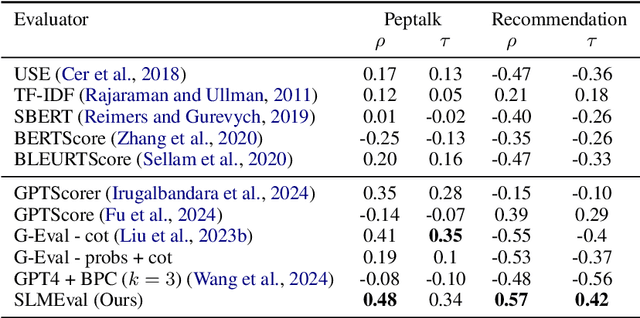
The LLM-as-a-Judge paradigm offers a scalable, reference-free approach for evaluating language models. Although several calibration techniques have been proposed to better align these evaluators with human judgment, prior studies focus primarily on narrow, well-structured benchmarks. As a result, it remains unclear whether such calibrations generalize to real-world, open-ended tasks. In this work, we show that SOTA calibrated evaluators often fail in these settings, exhibiting weak or even negative correlation with human judgments. To address this, we propose SLMEval, a novel and efficient calibration method based on entropy maximization over a small amount of human preference data. By estimating a latent distribution over model quality and reweighting evaluator scores accordingly, SLMEval achieves strong correlation with human evaluations across two real-world production use cases and the public benchmark. For example, on one such task, SLMEval achieves a Spearman correlation of 0.57 with human judgments, while G-Eval yields a negative correlation. In addition, SLMEval reduces evaluation costs by 5-30x compared to GPT-4-based calibrated evaluators such as G-eval.
A Graph-Based Approach for Conversational AI-Driven Personal Memory Capture and Retrieval in a Real-world Application
Dec 06, 2024TOBU is a novel mobile application that captures and retrieves `personal memories' (pictures/videos together with stories and context around those moments) in a user-engaging AI-guided conversational approach. Our initial prototype showed that existing retrieval techniques such as retrieval-augmented generation (RAG) systems fall short due to their limitations in understanding memory relationships, causing low recall, hallucination, and unsatisfactory user experience. We design TOBUGraph, a novel graph-based retrieval approach. During capturing, TOBUGraph leverages large language models (LLMs) to automatically create a dynamic knowledge graph of memories, establishing context and relationships of those memories. During retrieval, TOBUGraph combines LLMs with the memory graph to achieve comprehensive recall through graph traversal. Our evaluation using real user data demonstrates that TOBUGraph outperforms multiple RAG implementations in both precision and recall, significantly improving user experience through improved retrieval accuracy and reduced hallucination.
Ranking Unraveled: Recipes for LLM Rankings in Head-to-Head AI Combat
Nov 19, 2024



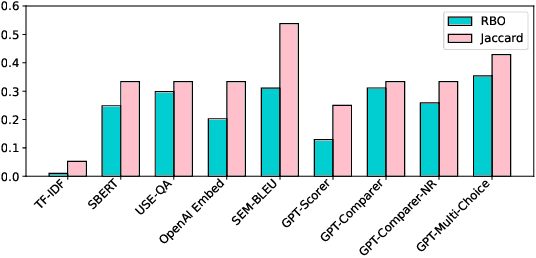
Deciding which large language model (LLM) to use is a complex challenge. Pairwise ranking has emerged as a new method for evaluating human preferences for LLMs. This approach entails humans evaluating pairs of model outputs based on a predefined criterion. By collecting these comparisons, a ranking can be constructed using methods such as Elo. However, applying these algorithms as constructed in the context of LLM evaluation introduces several challenges. In this paper, we explore the effectiveness of ranking systems for head-to-head comparisons of LLMs. We formally define a set of fundamental principles for effective ranking and conduct a series of extensive evaluations on the robustness of several ranking algorithms in the context of LLMs. Our analysis uncovers key insights into the factors that affect ranking accuracy and efficiency, offering guidelines for selecting the most appropriate methods based on specific evaluation contexts and resource constraints.
A Trade-off Analysis of Replacing Proprietary LLMs with Open Source SLMs in Production
Jan 15, 2024
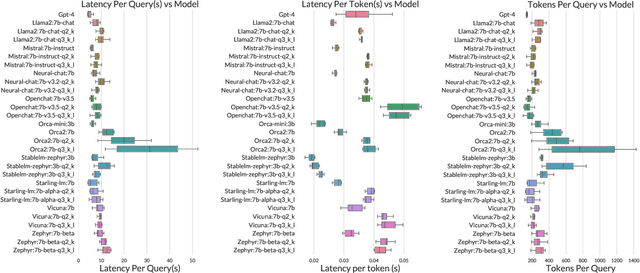
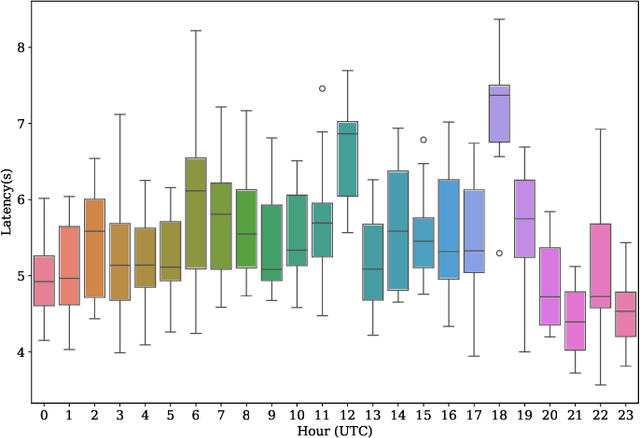
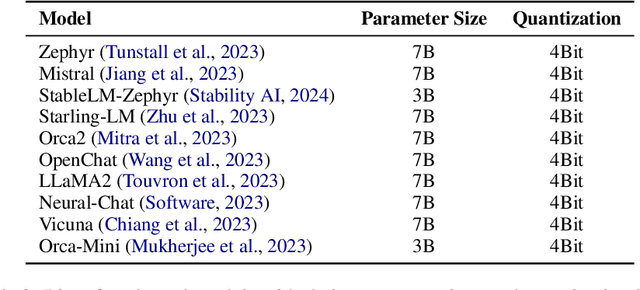
Many companies rely on APIs of managed AI models such as OpenAI's GPT-4 to create AI-enabled experiences in their products. Along with the benefits of ease of use and shortened time to production, this reliance on proprietary APIs has downsides in terms of model control, performance reliability, up-time predictability, and cost. At the same time, there has been a flurry of open source small language models (SLMs) that have been made available for commercial use. However, their readiness to replace existing capabilities remains unclear, and a systematic approach to test these models is not readily available. In this paper, we present a systematic evaluation methodology for, and characterization of, modern open source SLMs and their trade-offs when replacing a proprietary LLM APIs for a real-world product feature. We have designed SLaM, an automated analysis tool that enables the quantitative and qualitative testing of product features utilizing arbitrary SLMs. Using SLaM, we examine both the quality and the performance characteristics of modern SLMs relative to an existing customer-facing OpenAI-based implementation. We find that across 9 SLMs and 29 variants, we observe competitive quality-of-results for our use case, significant performance consistency improvement, and a cost reduction of 5x-29x when compared to OpenAI GPT-4.
Label Agnostic Pre-training for Zero-shot Text Classification
May 25, 2023
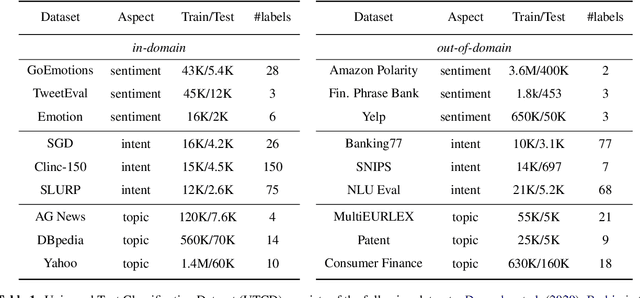

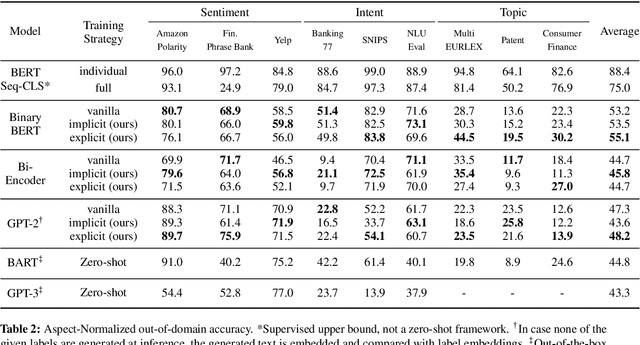
Conventional approaches to text classification typically assume the existence of a fixed set of predefined labels to which a given text can be classified. However, in real-world applications, there exists an infinite label space for describing a given text. In addition, depending on the aspect (sentiment, topic, etc.) and domain of the text (finance, legal, etc.), the interpretation of the label can vary greatly. This makes the task of text classification, particularly in the zero-shot scenario, extremely challenging. In this paper, we investigate the task of zero-shot text classification with the aim of improving the ability of pre-trained language models (PLMs) to generalize to both seen and unseen data across varying aspects and domains. To solve this we introduce two new simple yet effective pre-training strategies, Implicit and Explicit pre-training. These methods inject aspect-level understanding into the model at train time with the goal of conditioning the model to build task-level understanding. To evaluate this, we construct and release UTCD, a new benchmark dataset for evaluating text classification in zero-shot settings. Experimental results on UTCD show that our approach achieves improved zero-shot generalization on a suite of challenging datasets across an array of zero-shot formalizations.
The Jaseci Programming Paradigm and Runtime Stack: Building Scale-out Production Applications Easy and Fast
May 17, 2023



Today's production scale-out applications include many sub-application components, such as storage backends, logging infrastructure and AI models. These components have drastically different characteristics, are required to work in collaboration, and interface with each other as microservices. This leads to increasingly high complexity in developing, optimizing, configuring, and deploying scale-out applications, raising the barrier to entry for most individuals and small teams. We developed a novel co-designed runtime system, Jaseci, and programming language, Jac, which aims to reduce this complexity. The key design principle throughout Jaseci's design is to raise the level of abstraction by moving as much of the scale-out data management, microservice componentization, and live update complexity into the runtime stack to be automated and optimized automatically. We use real-world AI applications to demonstrate Jaseci's benefit for application performance and developer productivity.