 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLMEval: Entropy-Based Calibration for Human-Aligned Evaluation of Large Language Models
May 21, 2025
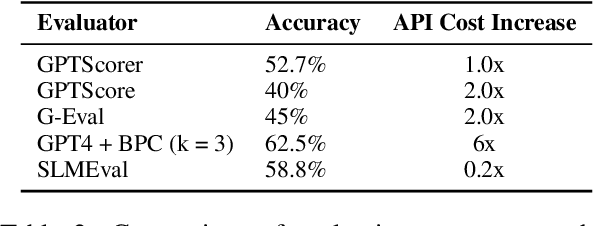
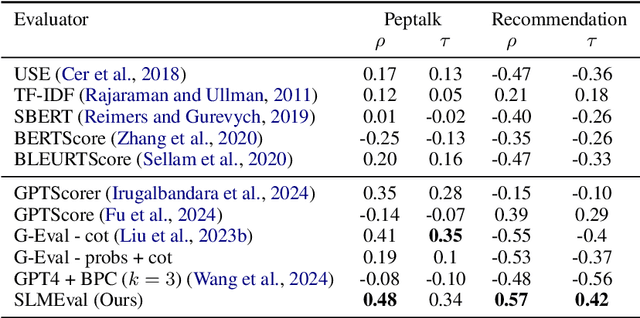
The LLM-as-a-Judge paradigm offers a scalable, reference-free approach for evaluating language models. Although several calibration techniques have been proposed to better align these evaluators with human judgment, prior studies focus primarily on narrow, well-structured benchmarks. As a result, it remains unclear whether such calibrations generalize to real-world, open-ended tasks. In this work, we show that SOTA calibrated evaluators often fail in these settings, exhibiting weak or even negative correlation with human judgments. To address this, we propose SLMEval, a novel and efficient calibration method based on entropy maximization over a small amount of human preference data. By estimating a latent distribution over model quality and reweighting evaluator scores accordingly, SLMEval achieves strong correlation with human evaluations across two real-world production use cases and the public benchmark. For example, on one such task, SLMEval achieves a Spearman correlation of 0.57 with human judgments, while G-Eval yields a negative correlation. In addition, SLMEval reduces evaluation costs by 5-30x compared to GPT-4-based calibrated evaluators such as G-eval.
A Graph-Based Approach for Conversational AI-Driven Personal Memory Capture and Retrieval in a Real-world Application
Dec 06, 2024TOBU is a novel mobile application that captures and retrieves `personal memories' (pictures/videos together with stories and context around those moments) in a user-engaging AI-guided conversational approach. Our initial prototype showed that existing retrieval techniques such as retrieval-augmented generation (RAG) systems fall short due to their limitations in understanding memory relationships, causing low recall, hallucination, and unsatisfactory user experience. We design TOBUGraph, a novel graph-based retrieval approach. During capturing, TOBUGraph leverages large language models (LLMs) to automatically create a dynamic knowledge graph of memories, establishing context and relationships of those memories. During retrieval, TOBUGraph combines LLMs with the memory graph to achieve comprehensive recall through graph traversal. Our evaluation using real user data demonstrates that TOBUGraph outperforms multiple RAG implementations in both precision and recall, significantly improving user experience through improved retrieval accuracy and reduced hallucination.
Ranking Unraveled: Recipes for LLM Rankings in Head-to-Head AI Combat
Nov 19, 2024



Deciding which large language model (LLM) to use is a complex challenge. Pairwise ranking has emerged as a new method for evaluating human preferences for LLMs. This approach entails humans evaluating pairs of model outputs based on a predefined criterion. By collecting these comparisons, a ranking can be constructed using methods such as Elo. However, applying these algorithms as constructed in the context of LLM evaluation introduces several challenges. In this paper, we explore the effectiveness of ranking systems for head-to-head comparisons of LLMs. We formally define a set of fundamental principles for effective ranking and conduct a series of extensive evaluations on the robustness of several ranking algorithms in the context of LLMs. Our analysis uncovers key insights into the factors that affect ranking accuracy and efficiency, offering guidelines for selecting the most appropriate methods based on specific evaluation contexts and resource constraints.
PEFT-U: Parameter-Efficient Fine-Tuning for User Personalization
Jul 25, 2024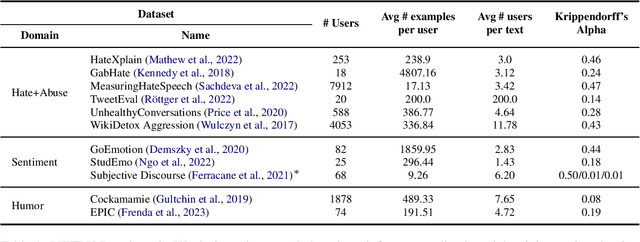
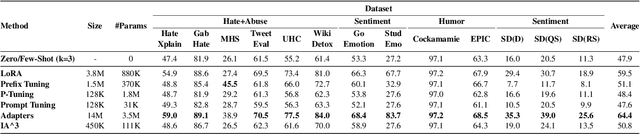
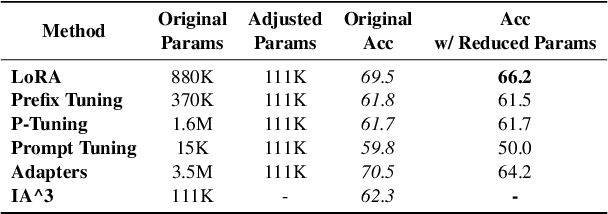
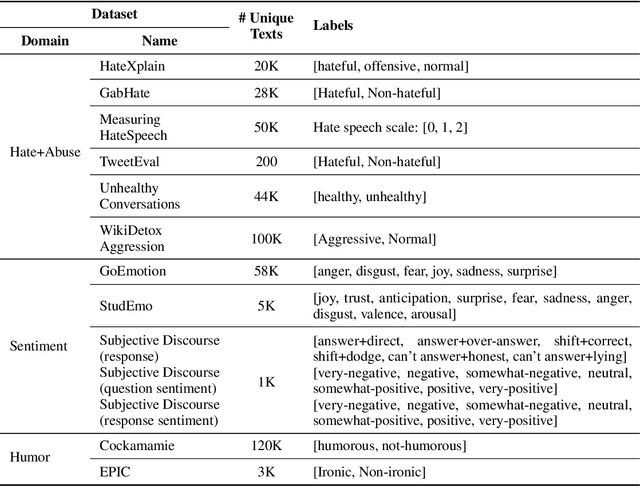
The recent emergence of Large Language Models (LLMs) has heralded a new era of human-AI interaction. These sophisticated models, exemplified by Chat-GPT and its successors, have exhibited remarkable capabilities in language understanding. However, as these LLMs have undergone exponential growth, a crucial dimension that remains understudied is the personalization of these models. Large foundation models such as GPT-3 etc. focus on creating a universal model that serves a broad range of tasks and users. This approach emphasizes the model's generalization capabilities, treating users as a collective rather than as distinct individuals. While practical for many common applications, this one-size-fits-all approach often fails to address the rich tapestry of human diversity and individual needs. To explore this issue we introduce the PEFT-U Benchmark: a new dataset for building and evaluating NLP models for user personalization. \datasetname{} consists of a series of user-centered tasks containing diverse and individualized expressions where the preferences of users can potentially differ for the same input. Using PEFT-U, we explore the challenge of efficiently personalizing LLMs to accommodate user-specific preferences in the context of diverse user-centered tasks.
LLMs are Meaning-Typed Code Constructs
May 14, 2024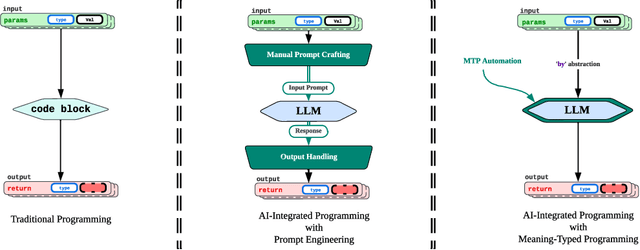
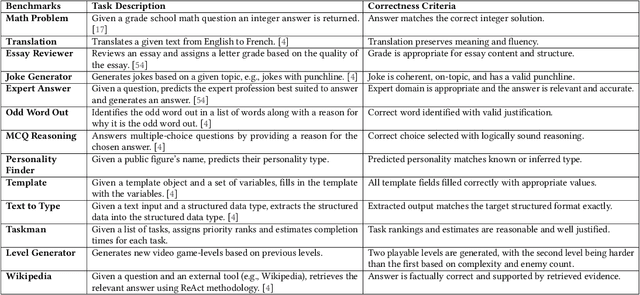

Programming with Generative AI (GenAI) models is a type of Neurosymbolic programming and has seen tremendous adoption across many domains. However, leveraging GenAI models in code today can be complex, counter-intuitive and often require specialized frameworks, leading to increased complexity. This is because it is currently unclear as to the right abstractions through which we should marry GenAI models with the nature of traditional programming code constructs. In this paper, we introduce a set of novel abstractions to help bridge the gap between Neuro- and symbolic programming. We introduce Meaning, a new specialized type that represents the underlying semantic value of traditional types (e.g., string). We make the case that GenAI models, LLMs in particular, should be reasoned as a meaning-type wrapped code construct at the language level. We formulate the problem of translation between meaning and traditional types and propose Automatic Meaning-Type Transformation (A-MTT), a runtime feature that abstracts this translation away from the developers by automatically converting between M eaning and types at the interface of LLM invocation. Leveraging this new set of code constructs and OTT, we demonstrate example implementation of neurosymbolic programs that seamlessly utilizes LLMs to solve problems in place of potentially complex traditional programming logic.
Guylingo: The Republic of Guyana Creole Corpora
May 06, 2024



While major languages often enjoy substantial attention and resources, the linguistic diversity across the globe encompasses a multitude of smaller, indigenous, and regional languages that lack the same level of computational support. One such region is the Caribbean. While commonly labeled as "English speaking", the ex-British Caribbean region consists of a myriad of Creole languages thriving alongside English. In this paper, we present Guylingo: a comprehensive corpus designed for advancing NLP research in the domain of Creolese (Guyanese English-lexicon Creole), the most widely spoken language in the culturally rich nation of Guyana. We first outline our framework for gathering and digitizing this diverse corpus, inclusive of colloquial expressions, idioms, and regional variations in a low-resource language. We then demonstrate the challenges of training and evaluating NLP models for machine translation in Creole. Lastly, we discuss the unique opportunities presented by recent NLP advancements for accelerating the formal adoption of Creole languages as official languages in the Caribbean.
A Trade-off Analysis of Replacing Proprietary LLMs with Open Source SLMs in Production
Jan 15, 2024
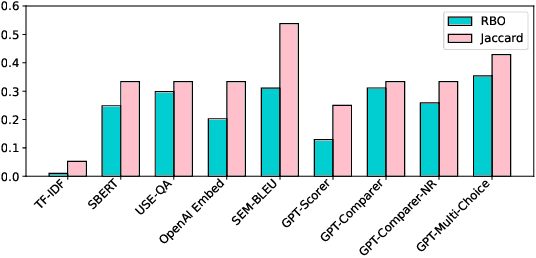
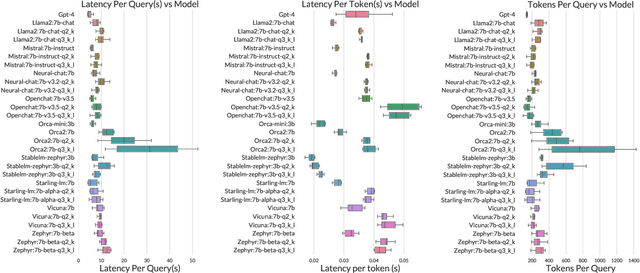
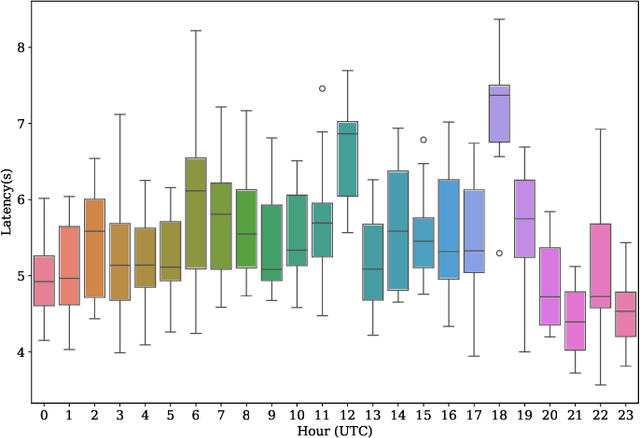
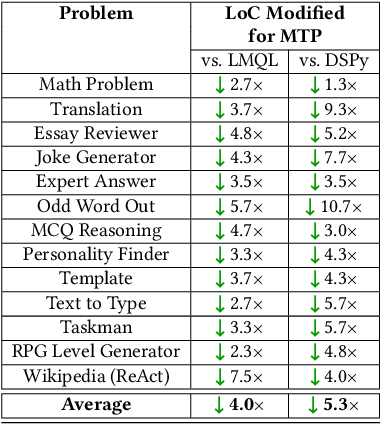
Many companies rely on APIs of managed AI models such as OpenAI's GPT-4 to create AI-enabled experiences in their products. Along with the benefits of ease of use and shortened time to production, this reliance on proprietary APIs has downsides in terms of model control, performance reliability, up-time predictability, and cost. At the same time, there has been a flurry of open source small language models (SLMs) that have been made available for commercial use. However, their readiness to replace existing capabilities remains unclear, and a systematic approach to test these models is not readily available. In this paper, we present a systematic evaluation methodology for, and characterization of, modern open source SLMs and their trade-offs when replacing a proprietary LLM APIs for a real-world product feature. We have designed SLaM, an automated analysis tool that enables the quantitative and qualitative testing of product features utilizing arbitrary SLMs. Using SLaM, we examine both the quality and the performance characteristics of modern SLMs relative to an existing customer-facing OpenAI-based implementation. We find that across 9 SLMs and 29 variants, we observe competitive quality-of-results for our use case, significant performance consistency improvement, and a cost reduction of 5x-29x when compared to OpenAI GPT-4.
One Agent Too Many: User Perspectives on Approaches to Multi-agent Conversational AI
Jan 13, 2024Conversational agents have been gaining increasing popularity in recent years. Influenced by the widespread adoption of task-oriented agents such as Apple Siri and Amazon Alexa, these agents are being deployed into various applications to enhance user experience. Although these agents promote "ask me anything" functionality, they are typically built to focus on a single or finite set of expertise. Given that complex tasks often require more than one expertise, this results in the users needing to learn and adopt multiple agents. One approach to alleviate this is to abstract the orchestration of agents in the background. However, this removes the option of choice and flexibility, potentially harming the ability to complete tasks. In this paper, we explore these different interaction experiences (one agent for all) vs (user choice of agents) for conversational AI. We design prototypes for each, systematically evaluating their ability to facilitate task completion. Through a series of conducted user studies, we show that users have a significant preference for abstracting agent orchestration in both system usability and system performance. Additionally, we demonstrate that this mode of interaction is able to provide quality responses that are rated within 1% of human-selected answers.
Rule By Example: Harnessing Logical Rules for Explainable Hate Speech Detection
Jul 24, 2023Classic approaches to content moderation typically apply a rule-based heuristic approach to flag content. While rules are easily customizable and intuitive for humans to interpret, they are inherently fragile and lack the flexibility or robustness needed to moderate the vast amount of undesirable content found online today. Recent advances in deep learning have demonstrated the promise of using highly effective deep neural models to overcome these challenges. However, despite the improved performance, these data-driven models lack transparency and explainability, often leading to mistrust from everyday users and a lack of adoption by many platforms. In this paper, we present Rule By Example (RBE): a novel exemplar-based contrastive learning approach for learning from logical rules for the task of textual content moderation. RBE is capable of providing rule-grounded predictions, allowing for more explainable and customizable predictions compared to typical deep learning-based approaches. We demonstrate that our approach is capable of learning rich rule embedding representations using only a few data examples. Experimental results on 3 popular hate speech classification datasets show that RBE is able to outperform state-of-the-art deep learning classifiers as well as the use of rules in both supervised and unsupervised settings while providing explainable model predictions via rule-grounding.
Label Agnostic Pre-training for Zero-shot Text Classification
May 25, 2023
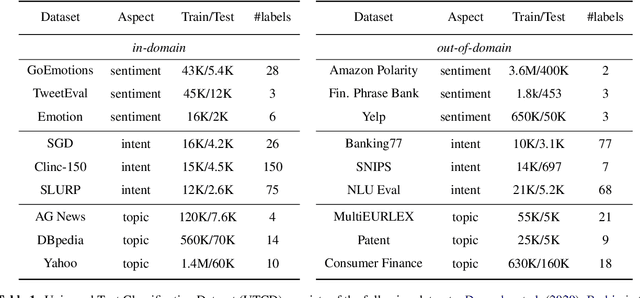

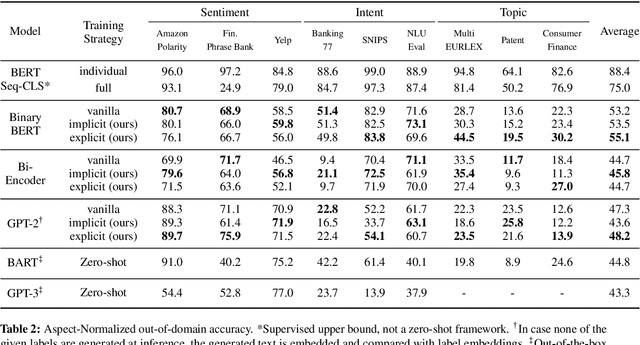
Conventional approaches to text classification typically assume the existence of a fixed set of predefined labels to which a given text can be classified. However, in real-world applications, there exists an infinite label space for describing a given text. In addition, depending on the aspect (sentiment, topic, etc.) and domain of the text (finance, legal, etc.), the interpretation of the label can vary greatly. This makes the task of text classification, particularly in the zero-shot scenario, extremely challenging. In this paper, we investigate the task of zero-shot text classification with the aim of improving the ability of pre-trained language models (PLMs) to generalize to both seen and unseen data across varying aspects and domains. To solve this we introduce two new simple yet effective pre-training strategies, Implicit and Explicit pre-training. These methods inject aspect-level understanding into the model at train time with the goal of conditioning the model to build task-level understanding. To evaluate this, we construct and release UTCD, a new benchmark dataset for evaluating text classification in zero-shot settings. Experimental results on UTCD show that our approach achieves improved zero-shot generalization on a suite of challenging datasets across an array of zero-shot formalizations.