 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Against Indirect Prompt Injection Attacks With Spotlighting
Mar 20, 2024Large Language Models (LLMs), while powerful, are built and trained to process a single text input. In common applications, multiple inputs can be processed by concatenating them together into a single stream of text. However, the LLM is unable to distinguish which sections of prompt belong to various input sources. Indirect prompt injection attacks take advantage of this vulnerability by embedding adversarial instructions into untrusted data being processed alongside user commands. Often, the LLM will mistake the adversarial instructions as user commands to be followed, creating a security vulnerability in the larger system. We introduce spotlighting, a family of prompt engineering techniques that can be used to improve LLMs' ability to distinguish among multiple sources of input. The key insight is to utilize transformations of an input to provide a reliable and continuous signal of its provenance. We evaluate spotlighting as a defense against indirect prompt injection attacks, and find that it is a robust defense that has minimal detrimental impact to underlying NLP tasks. Using GPT-family models, we find that spotlighting reduces the attack success rate from greater than {50}\% to below {2}\% in our experiments with minimal impact on task efficacy.
Rule By Example: Harnessing Logical Rules for Explainable Hate Speech Detection
Jul 24, 2023Classic approaches to content moderation typically apply a rule-based heuristic approach to flag content. While rules are easily customizable and intuitive for humans to interpret, they are inherently fragile and lack the flexibility or robustness needed to moderate the vast amount of undesirable content found online today. Recent advances in deep learning have demonstrated the promise of using highly effective deep neural models to overcome these challenges. However, despite the improved performance, these data-driven models lack transparency and explainability, often leading to mistrust from everyday users and a lack of adoption by many platforms. In this paper, we present Rule By Example (RBE): a novel exemplar-based contrastive learning approach for learning from logical rules for the task of textual content moderation. RBE is capable of providing rule-grounded predictions, allowing for more explainable and customizable predictions compared to typical deep learning-based approaches. We demonstrate that our approach is capable of learning rich rule embedding representations using only a few data examples. Experimental results on 3 popular hate speech classification datasets show that RBE is able to outperform state-of-the-art deep learning classifiers as well as the use of rules in both supervised and unsupervised settings while providing explainable model predictions via rule-grounding.
Chronic pain detection from resting-state raw EEG signals using improved feature selection
Jun 27, 2023We present an automatic approach that works on resting-state raw EEG data for chronic pain detection. A new feature selection algorithm - modified Sequential Floating Forward Selection (mSFFS) - is proposed. The improved feature selection scheme is rather compact but displays better class separability as indicated by the Bhattacharyya distance measures and better visualization results. It also outperforms selections generated by other benchmark methods, boosting the test accuracy to 97.5% and yielding a test accuracy of 81.4% on an external dataset that contains different types of chronic pain
Rethinking Multimodal Content Moderation from an Asymmetric Angle with Mixed-modality
May 17, 2023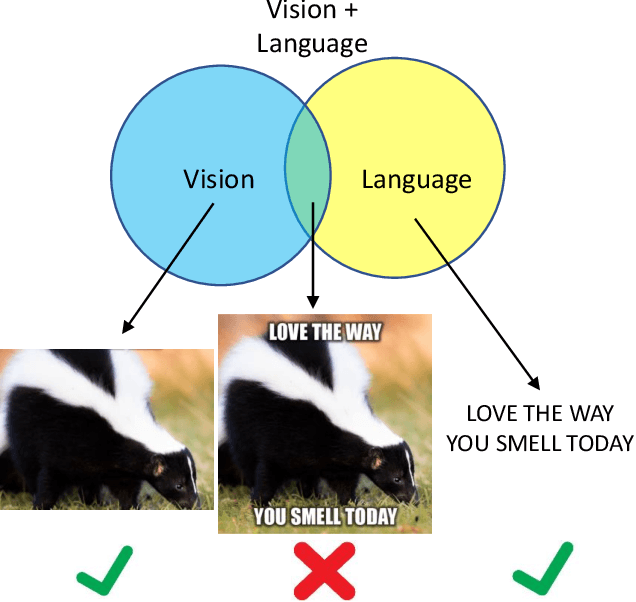
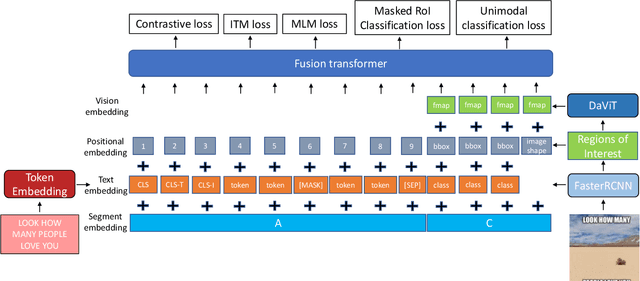
There is a rapidly growing need for multimodal content moderation (CM) as more and more content on social media is multimodal in nature. Existing unimodal CM systems may fail to catch harmful content that crosses modalities (e.g., memes or videos), which may lead to severe consequences. In this paper, we present a novel CM model, Asymmetric Mixed-Modal Moderation (AM3), to target multimodal and unimodal CM tasks. Specifically, to address the asymmetry in semantics between vision and language, AM3 has a novel asymmetric fusion architecture that is designed to not only fuse the common knowledge in both modalities but also to exploit the unique information in each modality. Unlike previous works that focus on fusing the two modalities while overlooking the intrinsic difference between the information conveyed in multimodality and in unimodality (asymmetry in modalities), we propose a novel cross-modality contrastive loss to learn the unique knowledge that only appears in multimodality. This is critical as some harmful intent may only be conveyed through the intersection of both modalities. With extensive experiments, we show that AM3 outperforms all existing state-of-the-art methods on both multimodal and unimodal CM benchmarks.
Contextual Bandit Applications in Customer Support Bot
Dec 06, 2021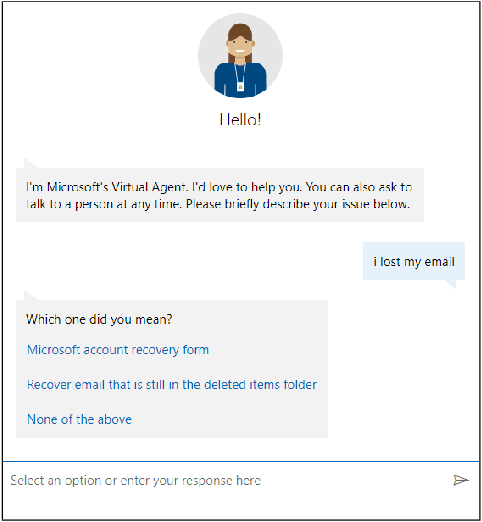
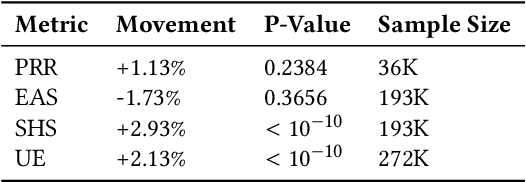
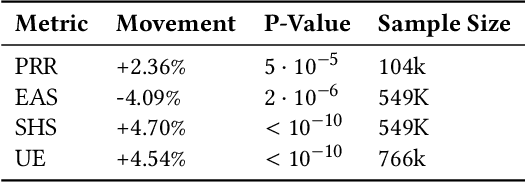
Virtual support agents have grown in popularity as a way for businesses to provide better and more accessible customer service. Some challenges in this domain include ambiguous user queries as well as changing support topics and user behavior (non-stationarity). We do, however, have access to partial feedback provided by the user (clicks, surveys, and other events) which can be leveraged to improve the user experience. Adaptable learning techniques, like contextual bandits, are a natural fit for this problem setting. In this paper, we discuss real-world implementations of contextual bandits (CB) for the Microsoft virtual agent. It includes intent disambiguation based on neural-linear bandits (NLB) and contextual recommendations based on a collection of multi-armed bandits (MAB). Our solutions have been deployed to production and have improved key business metrics of the Microsoft virtual agent, as confirmed by A/B experiments. Results include a relative increase of over 12% in problem resolution rate and relative decrease of over 4% in escalations to a human operator. While our current use cases focus on intent disambiguation and contextual recommendation for support bots, we believe our methods can be extended to other domains.
* in KDD 2021
Detecting East Asian Prejudice on Social Media
May 08, 2020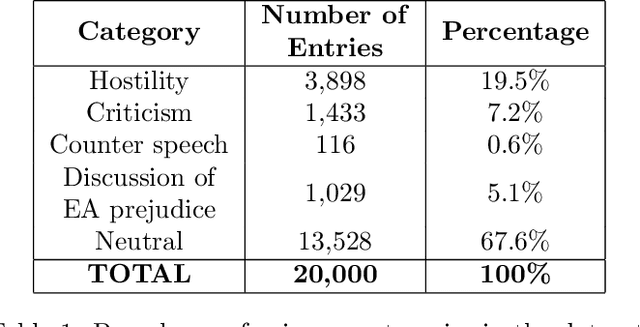
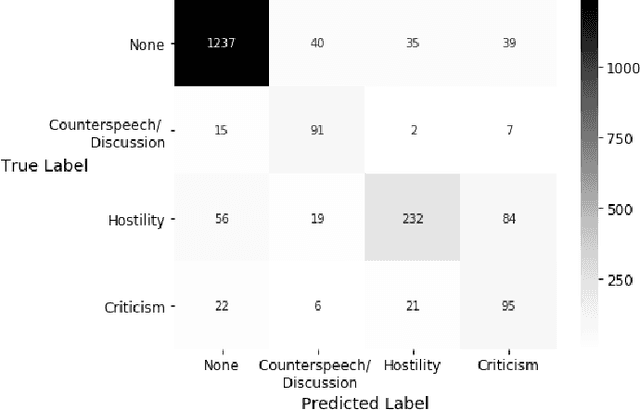
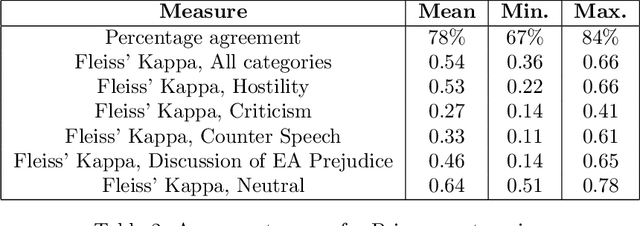
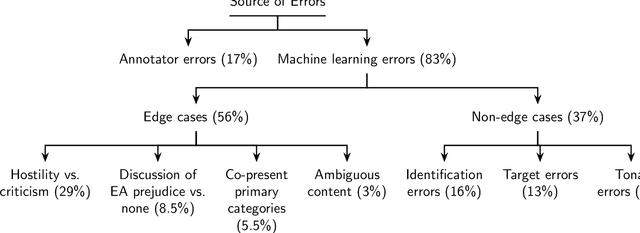
The outbreak of COVID-19 has transformed societies across the world as governments tackle the health, economic and social costs of the pandemic. It has also raised concerns about the spread of hateful language and prejudice online, especially hostility directed against East Asia. In this paper we report on the creation of a classifier that detects and categorizes social media posts from Twitter into four classes: Hostility against East Asia, Criticism of East Asia, Meta-discussions of East Asian prejudice and a neutral class. The classifier achieves an F1 score of 0.83 across all four classes. We provide our final model (coded in Python), as well as a new 20,000 tweet training dataset used to make the classifier, two analyses of hashtags associated with East Asian prejudice and the annotation codebook. The classifier can be implemented by other researchers, assisting with both online content moderation processes and further research into the dynamics, prevalence and impact of East Asian prejudice online during this global pandemic.
A Cumulative Multi-Niching Genetic Algorithm for Multimodal Function Optimization
Mar 03, 2013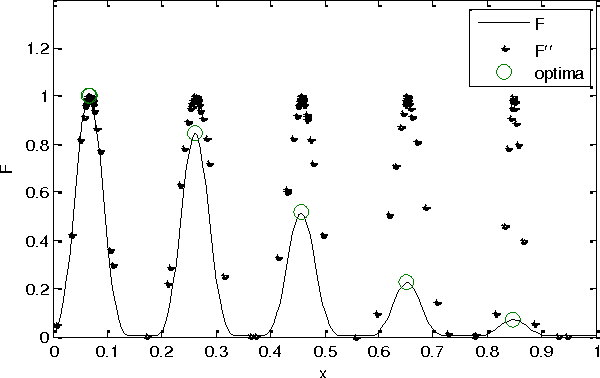
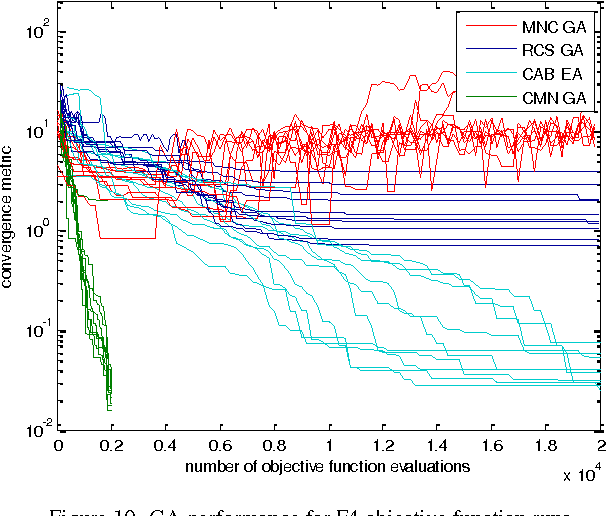
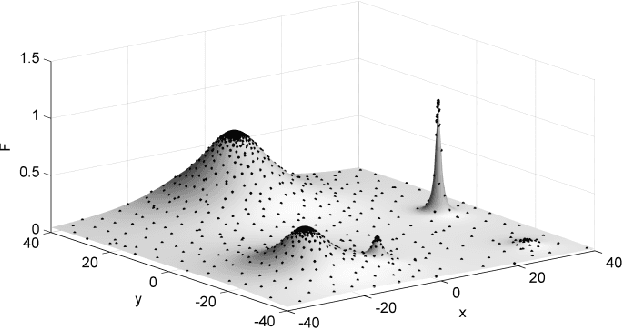
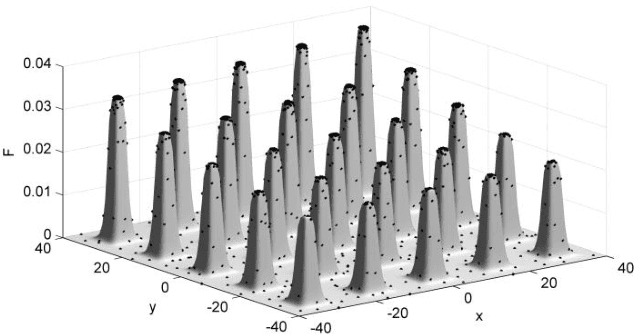
This paper presents a cumulative multi-niching genetic algorithm (CMN GA), designed to expedite optimization problems that have computationally-expensive multimodal objective functions. By never discarding individuals from the population, the CMN GA makes use of the information from every objective function evaluation as it explores the design space. A fitness-related population density control over the design space reduces unnecessary objective function evaluations. The algorithm's novel arrangement of genetic operations provides fast and robust convergence to multiple local optima. Benchmark tests alongside three other multi-niching algorithms show that the CMN GA has a greater convergence ability and provides an order-of-magnitude reduction in the number of objective function evaluations required to achieve a given level of convergence.