 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trigger in the Haystack: Extracting and Reconstructing LLM Backdoor Triggers
Feb 03, 2026Detecting whether a model has been poisoned is a longstanding problem in AI security. In this work, we present a practical scanner for identifying sleeper agent-style backdoors in causal language models. Our approach relies on two key findings: first, sleeper agents tend to memorize poisoning data, making it possible to leak backdoor examples using memory extraction techniques. Second, poisoned LLMs exhibit distinctive patterns in their output distributions and attention heads when backdoor triggers are present in the input. Guided by these observations, we develop a scalable backdoor scanning methodology that assumes no prior knowledge of the trigger or target behavior and requires only inference operations. Our scanner integrates naturally into broader defensive strategies and does not alter model performance. We show that our method recovers working triggers across multiple backdoor scenarios and a broad range of models and fine-tuning methods.
Lessons From Red Teaming 100 Generative AI Products
Jan 13, 2025In recent years, AI red teaming has emerged as a practice for probing the safety and security of generative AI systems. Due to the nascency of the field, there are many open questions about how red teaming operations should be conducted. Based on our experience red teaming over 100 generative AI products at Microsoft, we present our internal threat model ontology and eight main lessons we have learned: 1. Understand what the system can do and where it is applied 2. You don't have to compute gradients to break an AI system 3. AI red teaming is not safety benchmarking 4. Automation can help cover more of the risk landscape 5. The human element of AI red teaming is crucial 6. Responsible AI harms are pervasive but difficult to measure 7. LLMs amplify existing security risks and introduce new ones 8. The work of securing AI systems will never be complete By sharing these insights alongside case studies from our operations, we offer practical recommendations aimed at aligning red teaming efforts with real world risks. We also highlight aspects of AI red teaming that we believe are often misunderstood and discuss open questions for the field to consider.
PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI System
Oct 01, 2024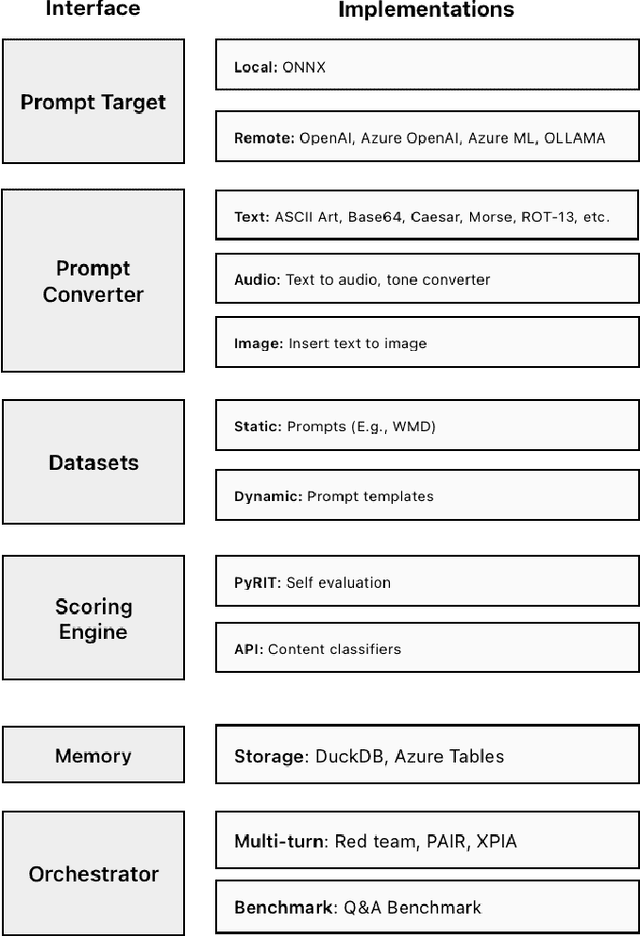
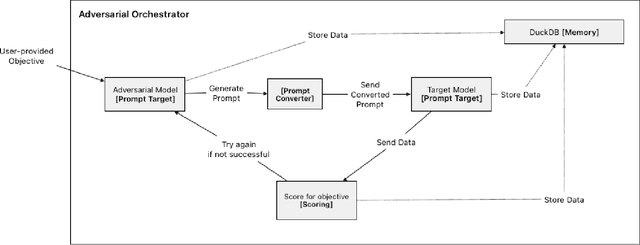
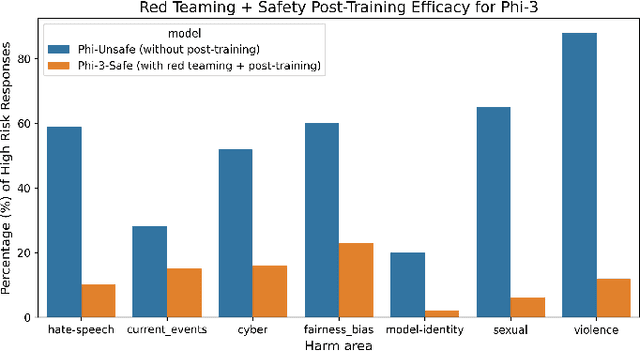
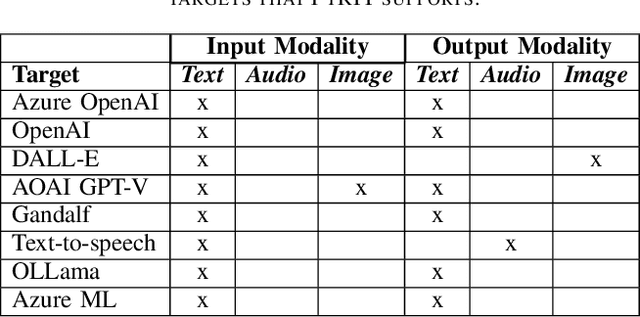
Generative Artificial Intelligence (GenAI) is becoming ubiquitous in our daily lives. The increase in computational power and data availability has led to a proliferation of both single- and multi-modal models. As the GenAI ecosystem matures, the need for extensible and model-agnostic risk identification frameworks is growing. To meet this need, we introduce the Python Risk Identification Toolkit (PyRIT), an open-source framework designed to enhance red teaming efforts in GenAI systems. PyRIT is a model- and platform-agnostic tool that enables red teamers to probe for and identify novel harms, risks, and jailbreaks in multimodal generative AI models. Its composable architecture facilitates the reuse of core building blocks and allows for extensibility to future models and modalities. This paper details the challenges specific to red teaming generative AI systems, the development and features of PyRIT, and its practical applications in real-world scenarios.
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Mar 20, 2024Large Language Models (LLMs), while powerful, are built and trained to process a single text input. In common applications, multiple inputs can be processed by concatenating them together into a single stream of text. However, the LLM is unable to distinguish which sections of prompt belong to various input sources. Indirect prompt injection attacks take advantage of this vulnerability by embedding adversarial instructions into untrusted data being processed alongside user commands. Often, the LLM will mistake the adversarial instructions as user commands to be followed, creating a security vulnerability in the larger system. We introduce spotlighting, a family of prompt engineering techniques that can be used to improve LLMs' ability to distinguish among multiple sources of input. The key insight is to utilize transformations of an input to provide a reliable and continuous signal of its provenance. We evaluate spotlighting as a defense against indirect prompt injection attacks, and find that it is a robust defense that has minimal detrimental impact to underlying NLP tasks. Using GPT-family models, we find that spotlighting reduces the attack success rate from greater than {50}\% to below {2}\% in our experiments with minimal impact on task efficacy.