 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Attack and Defend: Adaptive Red Teaming of Language Models via GRPO
Jun 08, 2026AI red teaming must continually adapt to evolving attackers and defenders. Reinforcement learning offers a promising approach to discovering novel attacks, and co-training methods can produce more robust defenders in tandem. Recent works have demonstrated the efficacy of attacker-defender co-training by applying PPO and DPO, but report that GRPO is unstable in this setting. We introduce AdvGRPO, a co-training framework that makes GRPO viable for joint attacker-defender optimization using dense multi-channel rewards and decoupled advantage normalization. Training progresses through a curriculum from single-turn to closed-loop multi-turn attacks before bootstrapping co-training, where attacker and defender models are updated in alternation. We show that our method can produce highly effective and transferable attacks and that co-trained defenders outperform baselines on safety benchmarks.
GRP-Obliteration: Unaligning LLMs With a Single Unlabeled Prompt
Feb 05, 2026Safety alignment is only as robust as its weakest failure mode. Despite extensive work on safety post-training, it has been shown that models can be readily unaligned through post-deployment fine-tuning. However, these methods often require extensive data curation and degrade model utility. In this work, we extend the practical limits of unalignment by introducing GRP-Obliteration (GRP-Oblit), a method that uses Group Relative Policy Optimization (GRPO) to directly remove safety constraints from target models. We show that a single unlabeled prompt is sufficient to reliably unalign safety-aligned models while largely preserving their utility, and that GRP-Oblit achieves stronger unalignment on average than existing state-of-the-art techniques. Moreover, GRP-Oblit generalizes beyond language models and can also unalign diffusion-based image generation systems. We evaluate GRP-Oblit on six utility benchmarks and five safety benchmarks across fifteen 7-20B parameter models, spanning instruct and reasoning models, as well as dense and MoE architectures. The evaluated model families include GPT-OSS, distilled DeepSeek, Gemma, Llama, Ministral, and Qwen.
The Trigger in the Haystack: Extracting and Reconstructing LLM Backdoor Triggers
Feb 03, 2026Detecting whether a model has been poisoned is a longstanding problem in AI security. In this work, we present a practical scanner for identifying sleeper agent-style backdoors in causal language models. Our approach relies on two key findings: first, sleeper agents tend to memorize poisoning data, making it possible to leak backdoor examples using memory extraction techniques. Second, poisoned LLMs exhibit distinctive patterns in their output distributions and attention heads when backdoor triggers are present in the input. Guided by these observations, we develop a scalable backdoor scanning methodology that assumes no prior knowledge of the trigger or target behavior and requires only inference operations. Our scanner integrates naturally into broader defensive strategies and does not alter model performance. We show that our method recovers working triggers across multiple backdoor scenarios and a broad range of models and fine-tuning methods.
Lessons From Red Teaming 100 Generative AI Products
Jan 13, 2025In recent years, AI red teaming has emerged as a practice for probing the safety and security of generative AI systems. Due to the nascency of the field, there are many open questions about how red teaming operations should be conducted. Based on our experience red teaming over 100 generative AI products at Microsoft, we present our internal threat model ontology and eight main lessons we have learned: 1. Understand what the system can do and where it is applied 2. You don't have to compute gradients to break an AI system 3. AI red teaming is not safety benchmarking 4. Automation can help cover more of the risk landscape 5. The human element of AI red teaming is crucial 6. Responsible AI harms are pervasive but difficult to measure 7. LLMs amplify existing security risks and introduce new ones 8. The work of securing AI systems will never be complete By sharing these insights alongside case studies from our operations, we offer practical recommendations aimed at aligning red teaming efforts with real world risks. We also highlight aspects of AI red teaming that we believe are often misunderstood and discuss open questions for the field to consider.
PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI System
Oct 01, 2024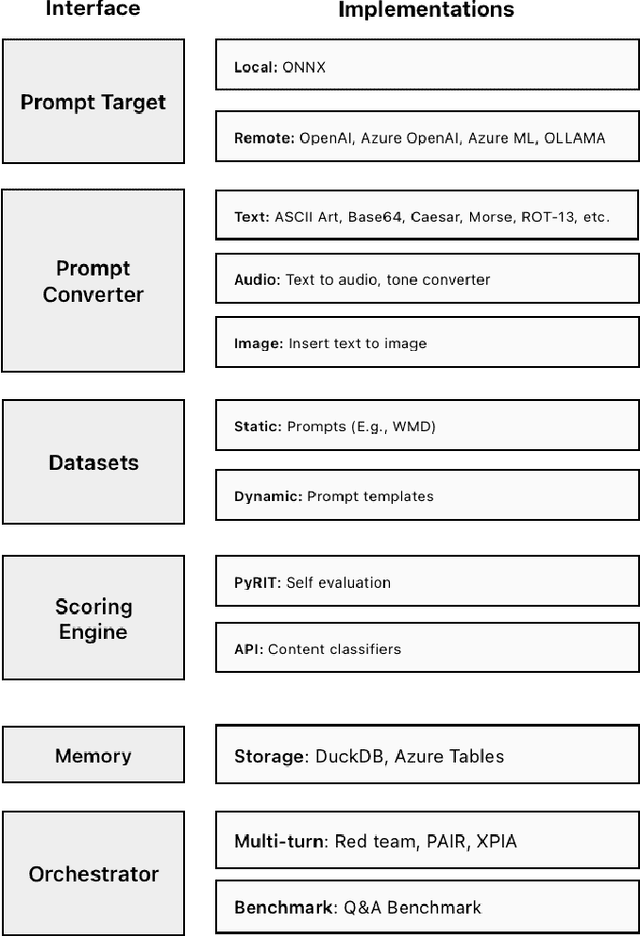
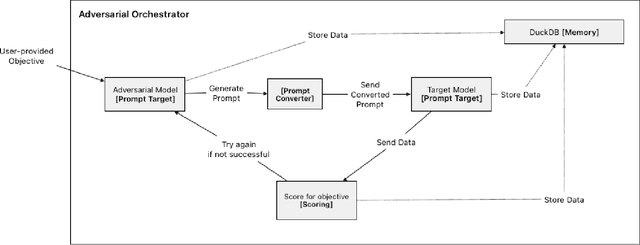
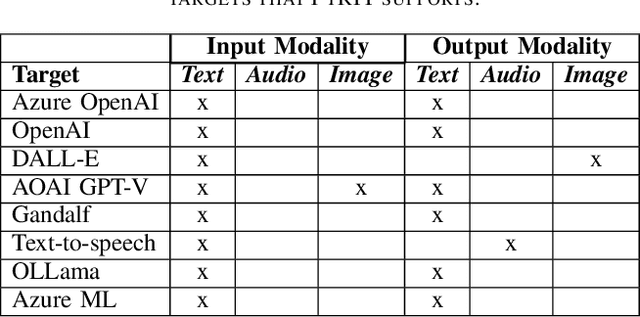
Generative Artificial Intelligence (GenAI) is becoming ubiquitous in our daily lives. The increase in computational power and data availability has led to a proliferation of both single- and multi-modal models. As the GenAI ecosystem matures, the need for extensible and model-agnostic risk identification frameworks is growing. To meet this need, we introduce the Python Risk Identification Toolkit (PyRIT), an open-source framework designed to enhance red teaming efforts in GenAI systems. PyRIT is a model- and platform-agnostic tool that enables red teamers to probe for and identify novel harms, risks, and jailbreaks in multimodal generative AI models. Its composable architecture facilitates the reuse of core building blocks and allows for extensibility to future models and modalities. This paper details the challenges specific to red teaming generative AI systems, the development and features of PyRIT, and its practical applications in real-world scenarios.
Phi-3 Safety Post-Training: Aligning Language Models with a "Break-Fix" Cycle
Jul 18, 2024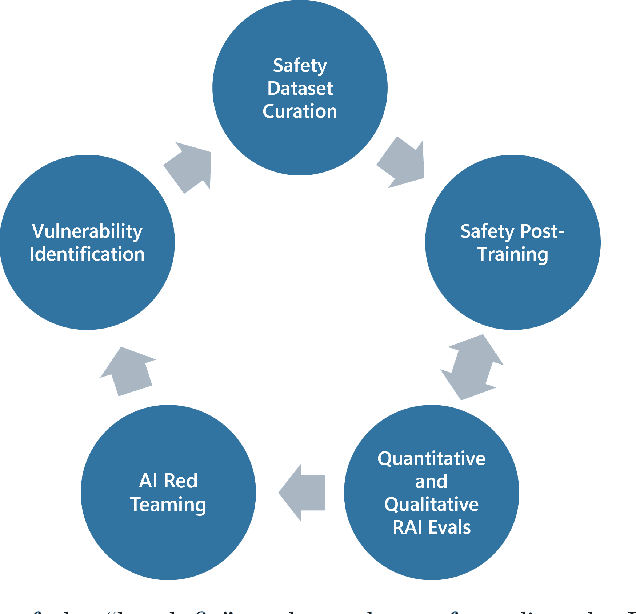


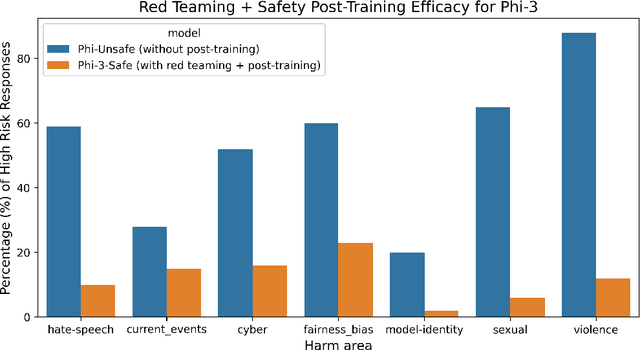
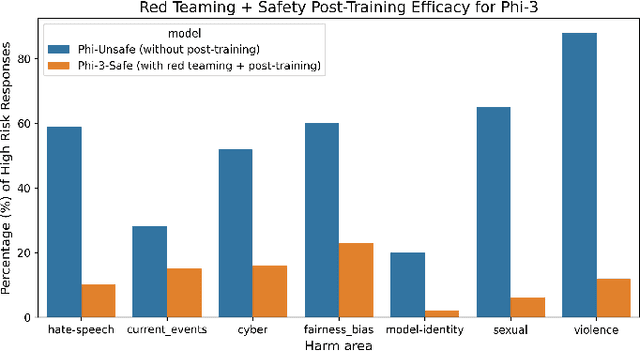
Recent innovations in language model training have demonstrated that it is possible to create highly performant models that are small enough to run on a smartphone. As these models are deployed in an increasing number of domains, it is critical to ensure that they are aligned with human preferences and safety considerations. In this report, we present our methodology for safety aligning the Phi-3 series of language models. We utilized a "break-fix" cycle, performing multiple rounds of dataset curation, safety post-training, benchmarking, red teaming, and vulnerability identification to cover a variety of harm areas in both single and multi-turn scenarios. Our results indicate that this approach iteratively improved the performance of the Phi-3 models across a wide range of responsible AI benchmarks.
Transfer Learning with Physics-Informed Neural Networks for Efficient Simulation of Branched Flows
Nov 01, 2022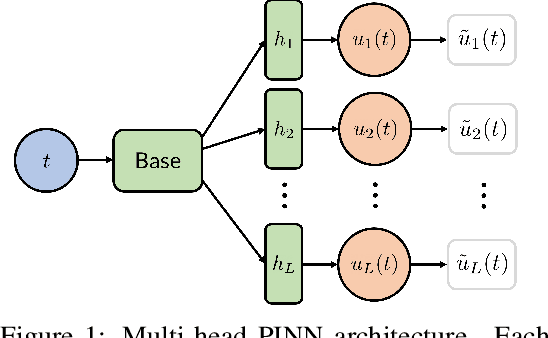

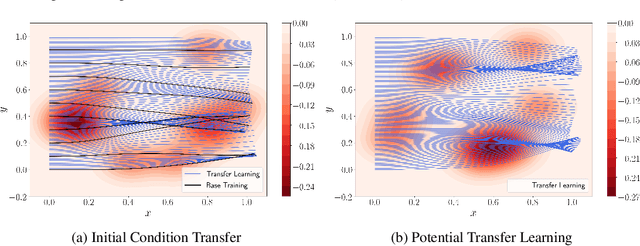
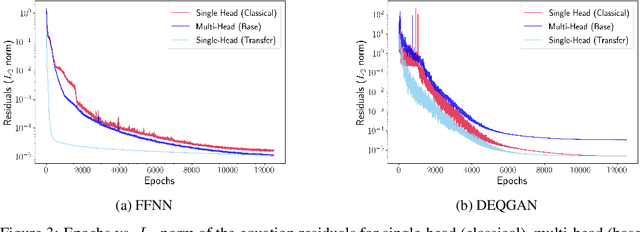
Physics-Informed Neural Networks (PINNs) offer a promising approach to solving differential equations and, more generally, to applying deep learning to problems in the physical sciences. We adopt a recently developed transfer learning approach for PINNs and introduce a multi-head model to efficiently obtain accurate solutions to nonlinear systems of ordinary differential equations with random potentials. In particular, we apply the method to simulate stochastic branched flows, a universal phenomenon in random wave dynamics. Finally, we compare the results achieved by feed forward and GAN-based PINNs on two physically relevant transfer learning tasks and show that our methods provide significant computational speedups in comparison to standard PINNs trained from scratch.
DEQGAN: Learning the Loss Function for PINNs with Generative Adversarial Networks
Sep 15, 2022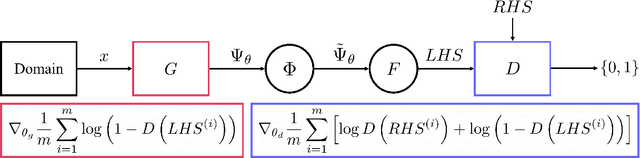
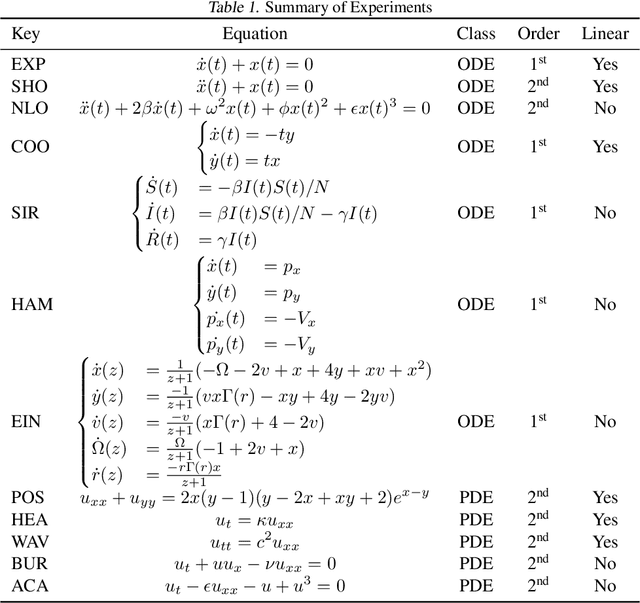
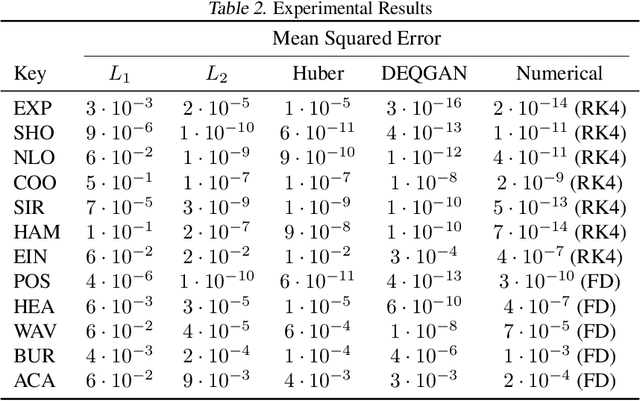
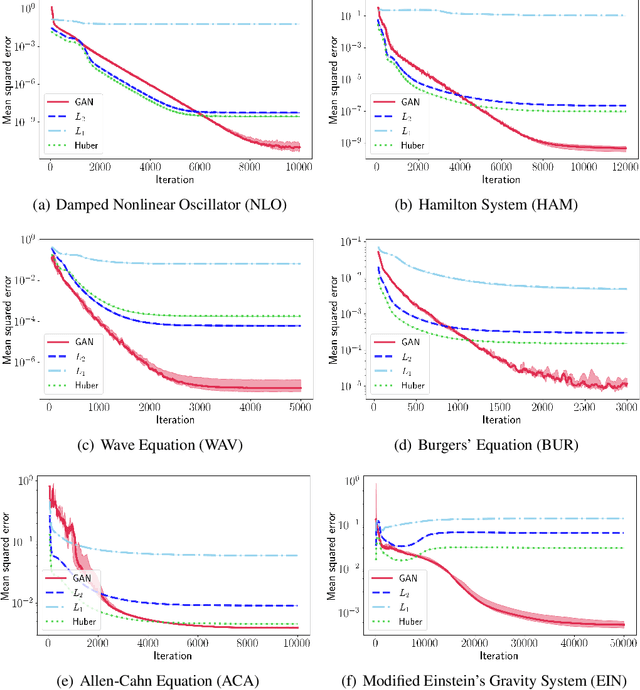
Solutions to differential equations are of significant scientific and engineering relevance. Physics-Informed Neural Networks (PINNs) have emerged as a promising method for solving differential equations, but they lack a theoretical justification for the use of any particular loss function. This work presents Differential Equation GAN (DEQGAN), a novel method for solving differential equations using generative adversarial networks to "learn the loss function" for optimizing the neural network. Presenting results on a suite of twelve ordinary and partial differential equations, including the nonlinear Burgers', Allen-Cahn, Hamilton, and modified Einstein's gravity equations, we show that DEQGAN can obtain multiple orders of magnitude lower mean squared errors than PINNs that use $L_2$, $L_1$, and Huber loss functions. We also show that DEQGAN achieves solution accuracies that are competitive with popular numerical methods. Finally, we present two methods to improve the robustness of DEQGAN to different hyperparameter settings.
Evaluating the Fairness Impact of Differentially Private Synthetic Data
May 09, 2022
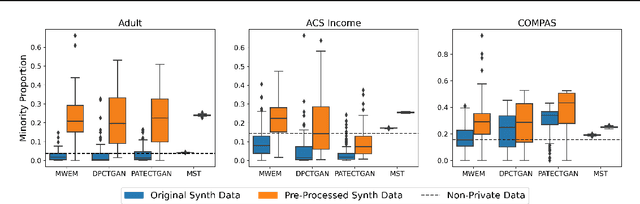

Differentially private (DP) synthetic data is a promising approach to maximizing the utility of data containing sensitive information. Due to the suppression of underrepresented classes that is often required to achieve privacy, however, it may be in conflict with fairness. We evaluate four DP synthesizers and present empirical results indicating that three of these models frequently degrade fairness outcomes on downstream binary classification tasks. We draw a connection between fairness and the proportion of minority groups present in the generated synthetic data, and find that training synthesizers on data that are pre-processed via a multi-label undersampling method can promote more fair outcomes without degrading accuracy.