 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating Multi-Suction Item Picking at Scale via Multi-Modal Learning of Pick Success
Jun 12, 2025This work demonstrates how autonomously learning aspects of robotic operation from sparsely-labeled, real-world data of deployed, engineered solutions at industrial scale can provide with solutions that achieve improved performance. Specifically, it focuses on multi-suction robot picking and performs a comprehensive study on the application of multi-modal visual encoders for predicting the success of candidate robotic picks. Picking diverse items from unstructured piles is an important and challenging task for robot manipulation in real-world settings, such as warehouses. Methods for picking from clutter must work for an open set of items while simultaneously meeting latency constraints to achieve high throughput. The demonstrated approach utilizes multiple input modalities, such as RGB, depth and semantic segmentation, to estimate the quality of candidate multi-suction picks. The strategy is trained from real-world item picking data, with a combination of multimodal pretrain and finetune. The manuscript provides comprehensive experimental evaluation performed over a large item-picking dataset, an item-picking dataset targeted to include partial occlusions, and a package-picking dataset, which focuses on containers, such as boxes and envelopes, instead of unpackaged items. The evaluation measures performance for different item configurations, pick scenes, and object types. Ablations help to understand the effects of in-domain pretraining, the impact of different modalities and the importance of finetuning. These ablations reveal both the importance of training over multiple modalities but also the ability of models to learn during pretraining the relationship between modalities so that during finetuning and inference, only a subset of them can be used as input.
MuST: Multi-Head Skill Transformer for Long-Horizon Dexterous Manipulation with Skill Progress
Feb 04, 2025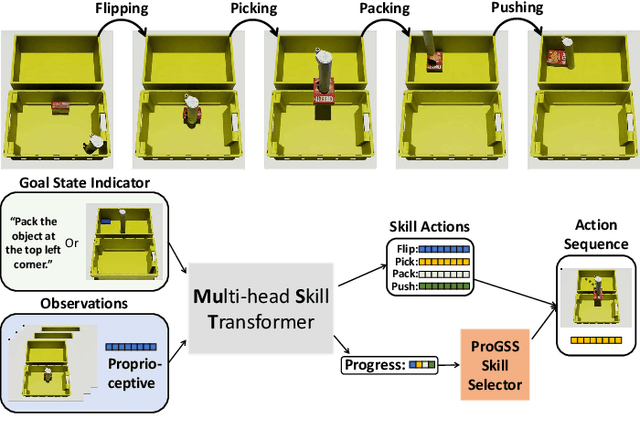
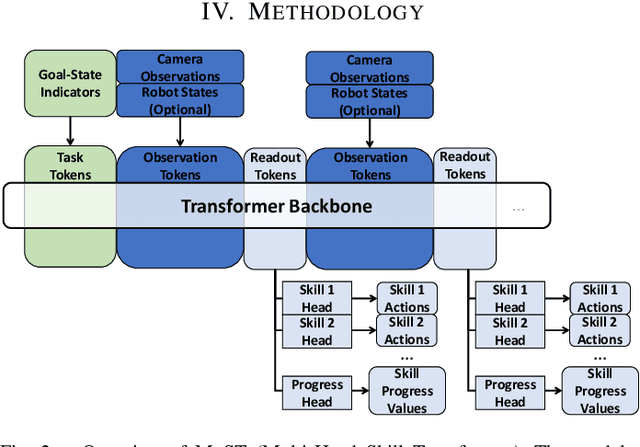
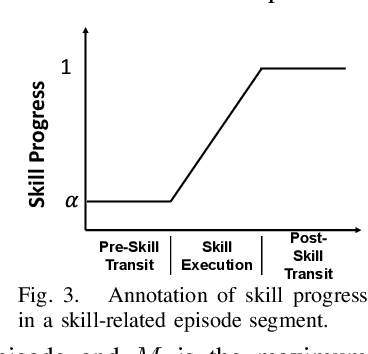
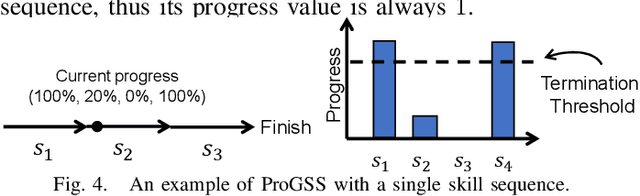
Robot picking and packing tasks require dexterous manipulation skills, such as rearranging objects to establish a good grasping pose, or placing and pushing items to achieve tight packing. These tasks are challenging for robots due to the complexity and variability of the required actions. To tackle the difficulty of learning and executing long-horizon tasks, we propose a novel framework called the Multi-Head Skill Transformer (MuST). This model is designed to learn and sequentially chain together multiple motion primitives (skills), enabling robots to perform complex sequences of actions effectively. MuST introduces a "progress value" for each skill, guiding the robot on which skill to execute next and ensuring smooth transitions between skills. Additionally, our model is capable of expanding its skill set and managing various sequences of sub-tasks efficiently. Extensive experiments in both simulated and real-world environments demonstrate that MuST significantly enhances the robot's ability to perform long-horizon dexterous manipulation tasks.
Learning Object Properties Using Robot Proprioception via Differentiable Robot-Object Interaction
Oct 04, 2024



Differentiable simulation has become a powerful tool for system identification. While prior work has focused on identifying robot properties using robot-specific data or object properties using object-specific data, our approach calibrates object properties by using information from the robot, without relying on data from the object itself. Specifically, we utilize robot joint encoder information, which is commonly available in standard robotic systems. Our key observation is that by analyzing the robot's reactions to manipulated objects, we can infer properties of those objects, such as inertia and softness. Leveraging this insight, we develop differentiable simulations of robot-object interactions to inversely identify the properties of the manipulated objects. Our approach relies solely on proprioception -- the robot's internal sensing capabilities -- and does not require external measurement tools or vision-based tracking systems. This general method is applicable to any articulated robot and requires only joint position information. We demonstrate the effectiveness of our method on a low-cost robotic platform, achieving accurate mass and elastic modulus estimations of manipulated objects with just a few seconds of computation on a laptop.
DEQGAN: Learning the Loss Function for PINNs with Generative Adversarial Networks
Sep 15, 2022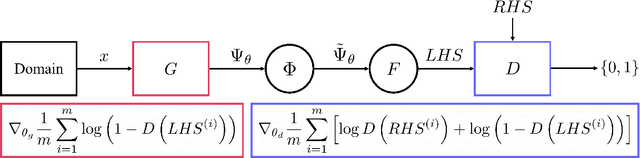
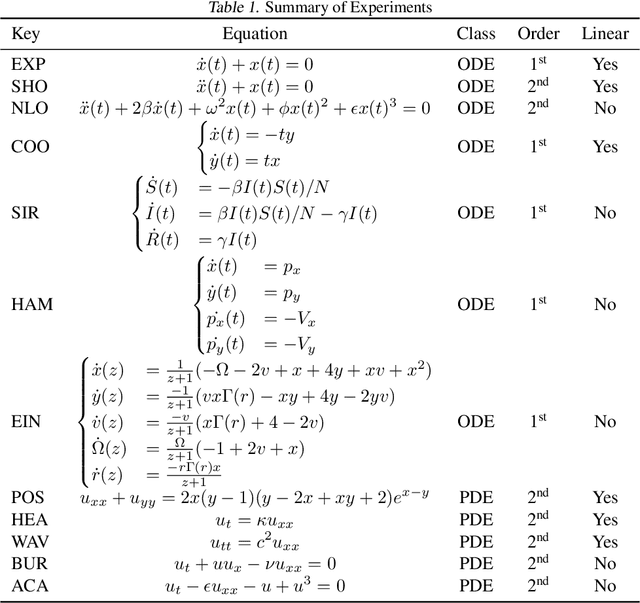
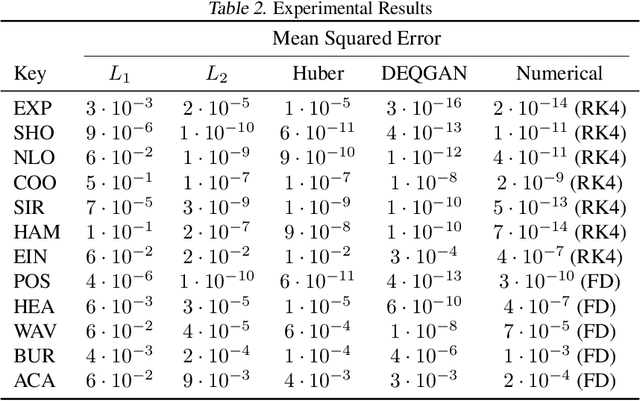
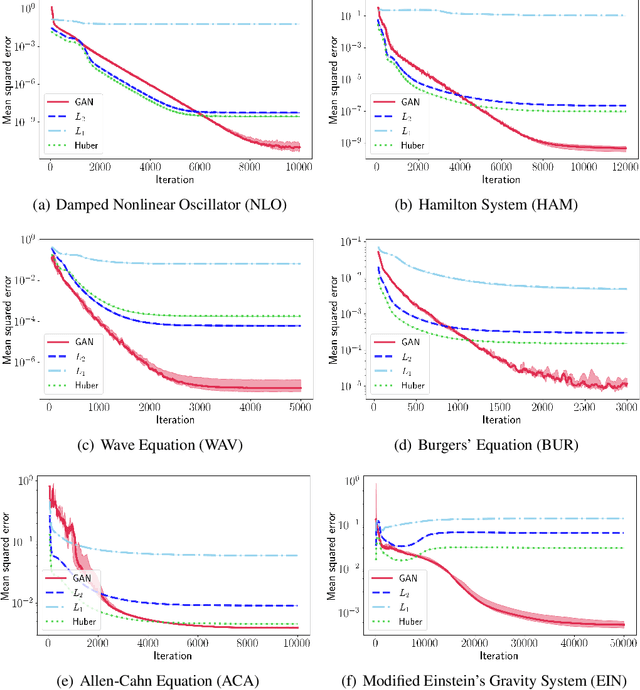
Solutions to differential equations are of significant scientific and engineering relevance. Physics-Informed Neural Networks (PINNs) have emerged as a promising method for solving differential equations, but they lack a theoretical justification for the use of any particular loss function. This work presents Differential Equation GAN (DEQGAN), a novel method for solving differential equations using generative adversarial networks to "learn the loss function" for optimizing the neural network. Presenting results on a suite of twelve ordinary and partial differential equations, including the nonlinear Burgers', Allen-Cahn, Hamilton, and modified Einstein's gravity equations, we show that DEQGAN can obtain multiple orders of magnitude lower mean squared errors than PINNs that use $L_2$, $L_1$, and Huber loss functions. We also show that DEQGAN achieves solution accuracies that are competitive with popular numerical methods. Finally, we present two methods to improve the robustness of DEQGAN to different hyperparameter settings.
Unsupervised Learning of Solutions to Differential Equations with Generative Adversarial Networks
Jul 21, 2020
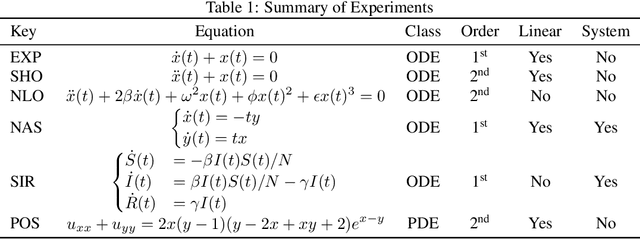
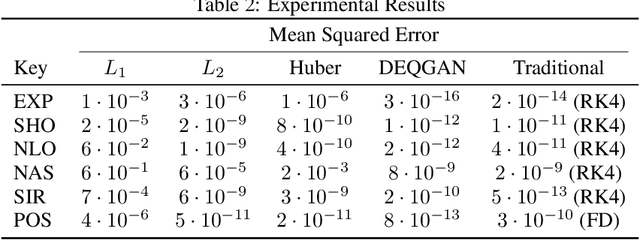
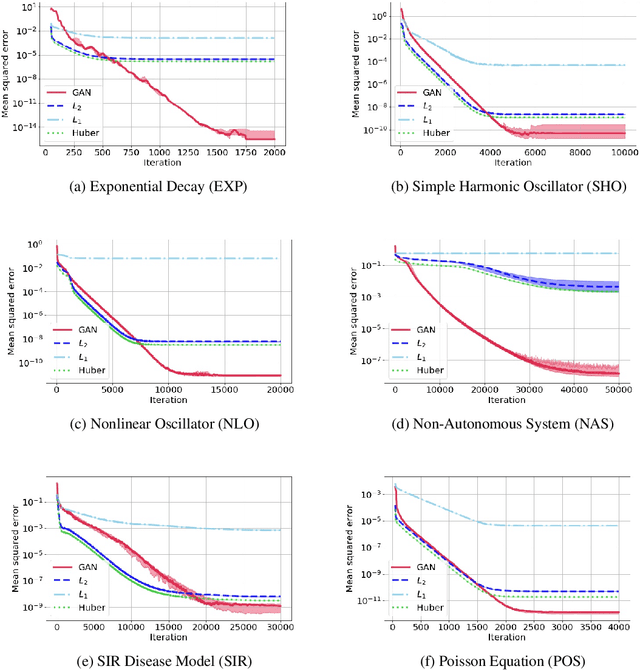
Solutions to differential equations are of significant scientific and engineering relevance. Recently, there has been a growing interest in solving differential equations with neural networks. This work develops a novel method for solving differential equations with unsupervised neural networks that applies Generative Adversarial Networks (GANs) to \emph{learn the loss function} for optimizing the neural network. We present empirical results showing that our method, which we call Differential Equation GAN (DEQGAN), can obtain multiple orders of magnitude lower mean squared errors than an alternative unsupervised neural network method based on (squared) $L_2$, $L_1$, and Huber loss functions. Moreover, we show that DEQGAN achieves solution accuracy that is competitive with traditional numerical methods. Finally, we analyze the stability of our approach and find it to be sensitive to the selection of hyperparameters, which we provide in the appendix. Code available at https://github.com/dylanrandle/denn. Please address any electronic correspondence to dylanrandle@alumni.harvard.edu.