 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating Multi-Suction Item Picking at Scale via Multi-Modal Learning of Pick Success
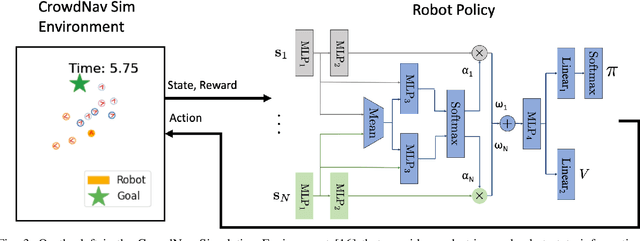
Jun 12, 2025This work demonstrates how autonomously learning aspects of robotic operation from sparsely-labeled, real-world data of deployed, engineered solutions at industrial scale can provide with solutions that achieve improved performance. Specifically, it focuses on multi-suction robot picking and performs a comprehensive study on the application of multi-modal visual encoders for predicting the success of candidate robotic picks. Picking diverse items from unstructured piles is an important and challenging task for robot manipulation in real-world settings, such as warehouses. Methods for picking from clutter must work for an open set of items while simultaneously meeting latency constraints to achieve high throughput. The demonstrated approach utilizes multiple input modalities, such as RGB, depth and semantic segmentation, to estimate the quality of candidate multi-suction picks. The strategy is trained from real-world item picking data, with a combination of multimodal pretrain and finetune. The manuscript provides comprehensive experimental evaluation performed over a large item-picking dataset, an item-picking dataset targeted to include partial occlusions, and a package-picking dataset, which focuses on containers, such as boxes and envelopes, instead of unpackaged items. The evaluation measures performance for different item configurations, pick scenes, and object types. Ablations help to understand the effects of in-domain pretraining, the impact of different modalities and the importance of finetuning. These ablations reveal both the importance of training over multiple modalities but also the ability of models to learn during pretraining the relationship between modalities so that during finetuning and inference, only a subset of them can be used as input.
GeoDiffuser: Geometry-Based Image Editing with Diffusion Models
Apr 22, 2024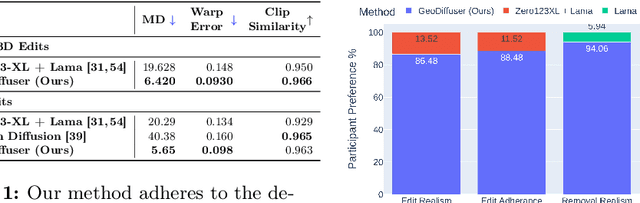

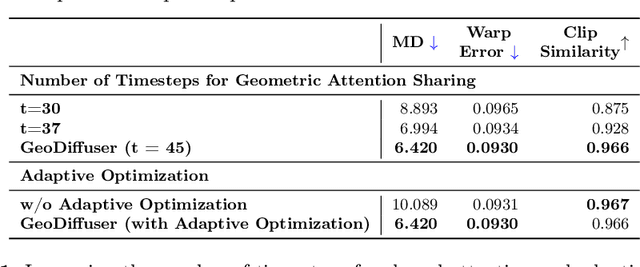
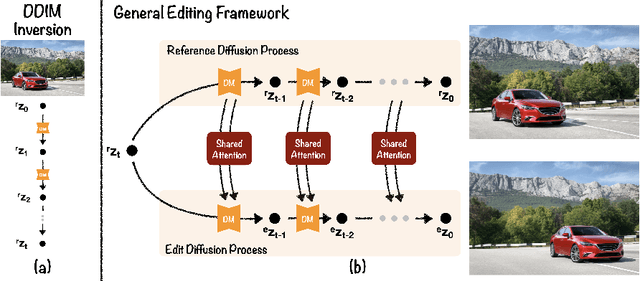
The success of image generative models has enabled us to build methods that can edit images based on text or other user input. However, these methods are bespoke, imprecise, require additional information, or are limited to only 2D image edits. We present GeoDiffuser, a zero-shot optimization-based method that unifies common 2D and 3D image-based object editing capabilities into a single method. Our key insight is to view image editing operations as geometric transformations. We show that these transformations can be directly incorporated into the attention layers in diffusion models to implicitly perform editing operations. Our training-free optimization method uses an objective function that seeks to preserve object style but generate plausible images, for instance with accurate lighting and shadows. It also inpaints disoccluded parts of the image where the object was originally located. Given a natural image and user input, we segment the foreground object using SAM and estimate a corresponding transform which is used by our optimization approach for editing. GeoDiffuser can perform common 2D and 3D edits like object translation, 3D rotation, and removal. We present quantitative results, including a perceptual study, that shows how our approach is better than existing methods. Visit https://ivl.cs.brown.edu/research/geodiffuser.html for more information.
Group-Aware Robot Navigation in Crowded Environments
Dec 22, 2020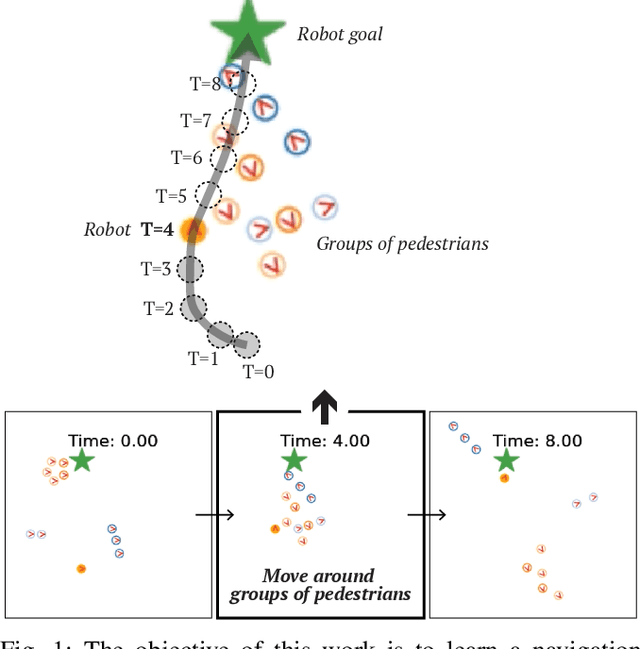

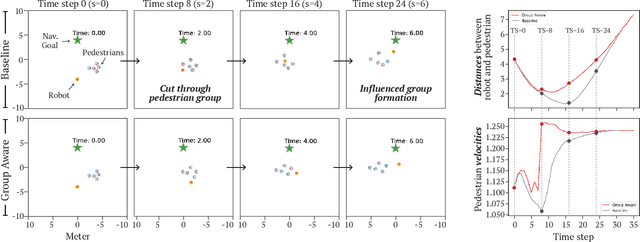
Human-aware robot navigation promises a range of applications in which mobile robots bring versatile assistance to people in common human environments. While prior research has mostly focused on modeling pedestrians as independent, intentional individuals, people move in groups; consequently, it is imperative for mobile robots to respect human groups when navigating around people. This paper explores learning group-aware navigation policies based on dynamic group formation using deep reinforcement learning. Through simulation experiments, we show that group-aware policies, compared to baseline policies that neglect human groups, achieve greater robot navigation performance (e.g., fewer collisions), minimize violation of social norms and discomfort, and reduce the robot's movement impact on pedestrians. Our results contribute to the development of social navigation and the integration of mobile robots into human environments.
Visual Robot Task Planning
Mar 30, 2018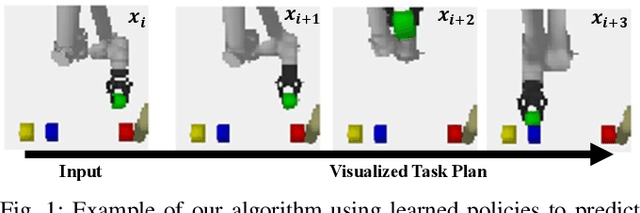

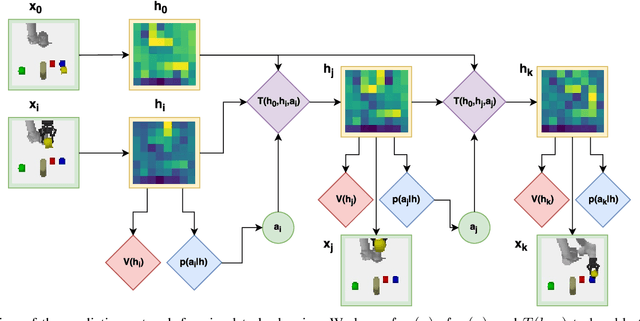
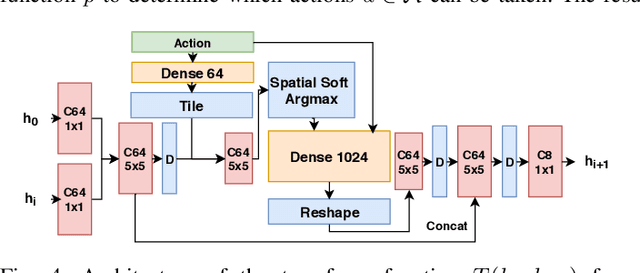
Prospection, the act of predicting the consequences of many possible futures, is intrinsic to human planning and action, and may even be at the root of consciousness. Surprisingly, this idea has been explored comparatively little in robotics. In this work, we propose a neural network architecture and associated planning algorithm that (1) learns a representation of the world useful for generating prospective futures after the application of high-level actions, (2) uses this generative model to simulate the result of sequences of high-level actions in a variety of environments, and (3) uses this same representation to evaluate these actions and perform tree search to find a sequence of high-level actions in a new environment. Models are trained via imitation learning on a variety of domains, including navigation, pick-and-place, and a surgical robotics task. Our approach allows us to visualize intermediate motion goals and learn to plan complex activity from visual information.
Occupancy Map Prediction Using Generative and Fully Convolutional Networks for Vehicle Navigation
Mar 06, 2018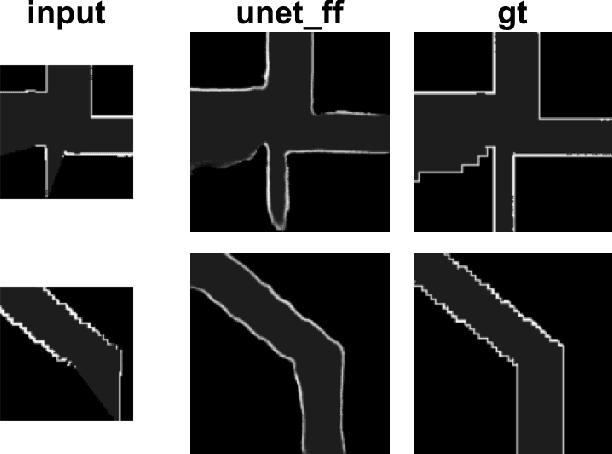

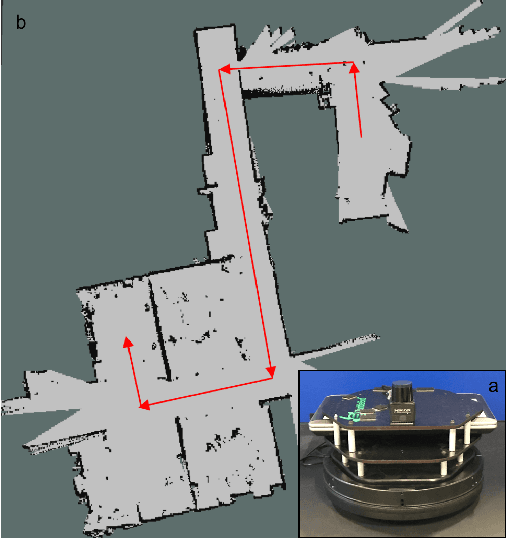
Fast, collision-free motion through unknown environments remains a challenging problem for robotic systems. In these situations, the robot's ability to reason about its future motion is often severely limited by sensor field of view (FOV). By contrast, biological systems routinely make decisions by taking into consideration what might exist beyond their FOV based on prior experience. In this paper, we present an approach for predicting occupancy map representations of sensor data for future robot motions using deep neural networks. We evaluate several deep network architectures, including purely generative and adversarial models. Testing on both simulated and real environments we demonstrated performance both qualitatively and quantitatively, with SSIM similarity measure up to 0.899. We showed that it is possible to make predictions about occupied space beyond the physical robot's FOV from simulated training data. In the future, this method will allow robots to navigate through unknown environments in a faster, safer manner.
Learning to Imagine Manipulation Goals for Robot Task Planning
Nov 09, 2017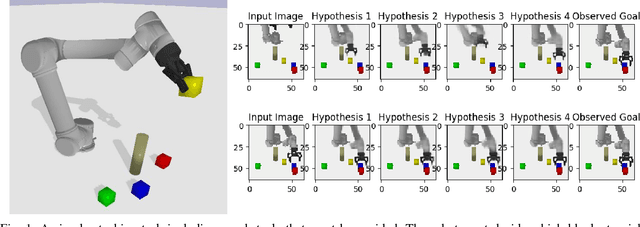
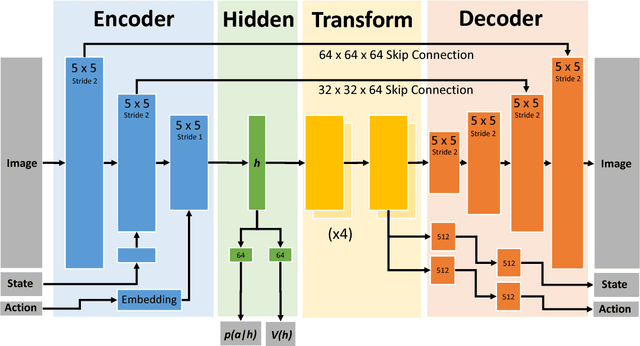

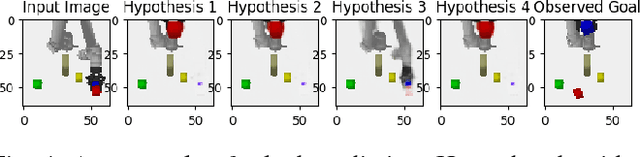
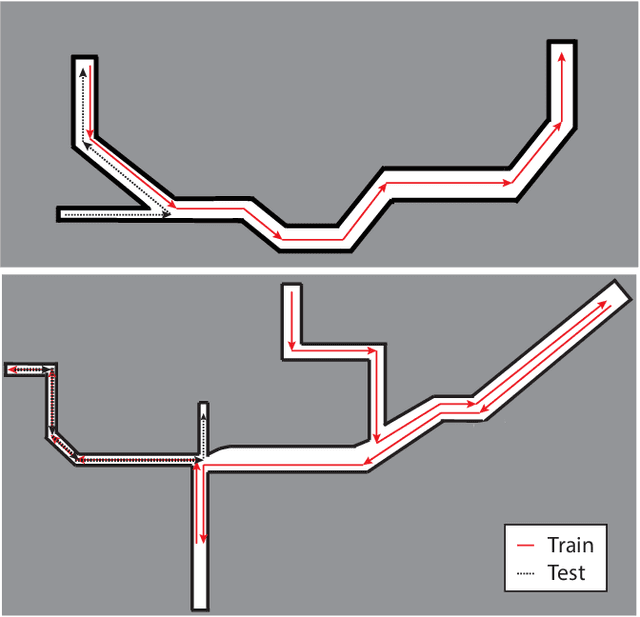
Prospection is an important part of how humans come up with new task plans, but has not been explored in depth in robotics. Predicting multiple task-level is a challenging problem that involves capturing both task semantics and continuous variability over the state of the world. Ideally, we would combine the ability of machine learning to leverage big data for learning the semantics of a task, while using techniques from task planning to reliably generalize to new environment. In this work, we propose a method for learning a model encoding just such a representation for task planning. We learn a neural net that encodes the $k$ most likely outcomes from high level actions from a given world. Our approach creates comprehensible task plans that allow us to predict changes to the environment many time steps into the future. We demonstrate this approach via application to a stacking task in a cluttered environment, where the robot must select between different colored blocks while avoiding obstacles, in order to perform a task. We also show results on a simple navigation task. Our algorithm generates realistic image and pose predictions at multiple points in a given task.