 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLeak: Prompt Leaking Attacks against Large Language Model Applications
May 14, 2024

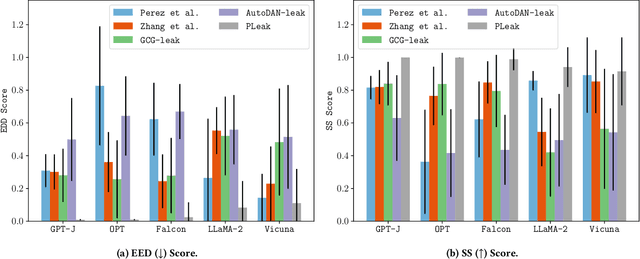
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.
Evaluating Trade-offs in Computer Vision Between Attribute Privacy, Fairness and Utility
Feb 15, 2023



This paper investigates to what degree and magnitude tradeoffs exist between utility, fairness and attribute privacy in computer vision. Regarding privacy, we look at this important problem specifically in the context of attribute inference attacks, a less addressed form of privacy. To create a variety of models with different preferences, we use adversarial methods to intervene on attributes relating to fairness and privacy. We see that that certain tradeoffs exist between fairness and utility, privacy and utility, and between privacy and fairness. The results also show that those tradeoffs and interactions are more complex and nonlinear between the three goals than intuition would suggest.
Addressing Heterogeneity in Federated Learning via Distributional Transformation
Oct 26, 2022Federated learning (FL) allows multiple clients to collaboratively train a deep learning model. One major challenge of FL is when data distribution is heterogeneous, i.e., differs from one client to another. Existing personalized FL algorithms are only applicable to narrow cases, e.g., one or two data classes per client, and therefore they do not satisfactorily address FL under varying levels of data heterogeneity. In this paper, we propose a novel framework, called DisTrans, to improve FL performance (i.e., model accuracy) via train and test-time distributional transformations along with a double-input-channel model structure. DisTrans works by optimizing distributional offsets and models for each FL client to shift their data distribution, and aggregates these offsets at the FL server to further improve performance in case of distributional heterogeneity. Our evaluation on multiple benchmark datasets shows that DisTrans outperforms state-of-the-art FL methods and data augmentation methods under various settings and different degrees of client distributional heterogeneity.
Achieving Utility, Fairness, and Compactness via Tunable Information Bottleneck Measures
Jun 20, 2022

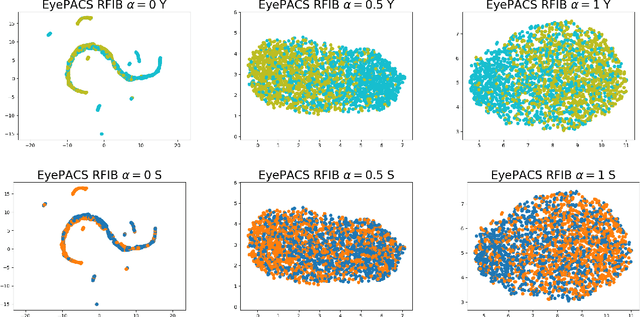

Designing machine learning algorithms that are accurate yet fair, not discriminating based on any sensitive attribute, is of paramount importance for society to accept AI for critical applications. In this article, we propose a novel fair representation learning method termed the R\'enyi Fair Information Bottleneck Method (RFIB) which incorporates constraints for utility, fairness, and compactness of representation, and apply it to image classification. A key attribute of our approach is that we consider - in contrast to most prior work - both demographic parity and equalized odds as fairness constraints, allowing for a more nuanced satisfaction of both criteria. Leveraging a variational approach, we show that our objectives yield a loss function involving classical Information Bottleneck (IB) measures and establish an upper bound in terms of the R\'enyi divergence of order $\alpha$ on the mutual information IB term measuring compactness between the input and its encoded embedding. Experimenting on three different image datasets (EyePACS, CelebA, and FairFace), we study the influence of the $\alpha$ parameter as well as two other tunable IB parameters on achieving utility/fairness trade-off goals, and show that the $\alpha$ parameter gives an additional degree of freedom that can be used to control the compactness of the representation. We evaluate the performance of our method using various utility, fairness, and compound utility/fairness metrics, showing that RFIB outperforms current state-of-the-art approaches.
Renyi Fair Information Bottleneck for Image Classification
Mar 09, 2022
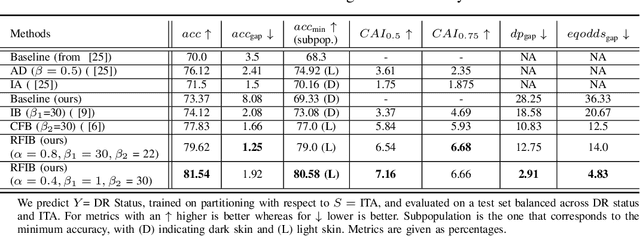
We develop a novel method for ensuring fairness in machine learning which we term as the Renyi Fair Information Bottleneck (RFIB). We consider two different fairness constraints - demographic parity and equalized odds - for learning fair representations and derive a loss function via a variational approach that uses Renyi's divergence with its tunable parameter $\alpha$ and that takes into account the triple constraints of utility, fairness, and compactness of representation. We then evaluate the performance of our method for image classification using the EyePACS medical imaging dataset, showing it outperforms competing state of the art techniques with performance measured using a variety of compound utility/fairness metrics, including accuracy gap and Rawls' minimal accuracy.
Robustness and Adaptation to Hidden Factors of Variation
Mar 03, 2022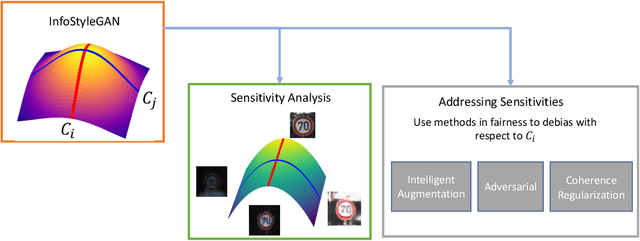
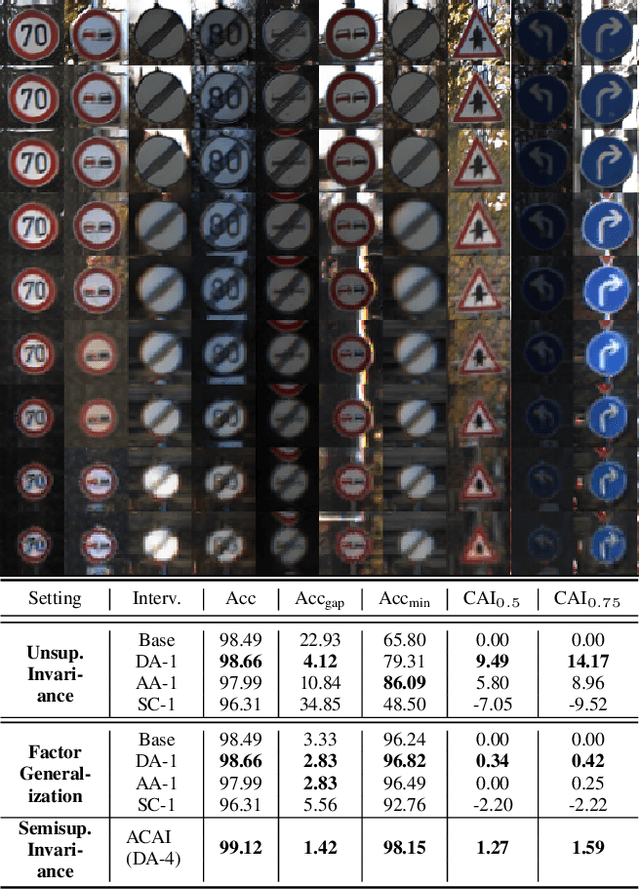

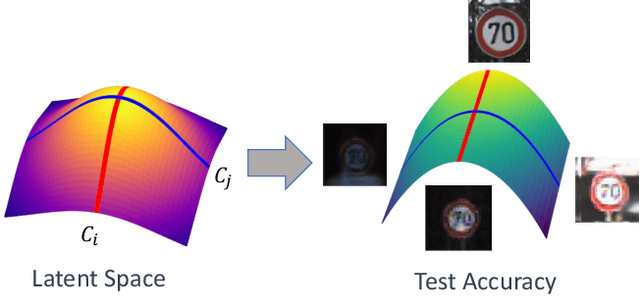
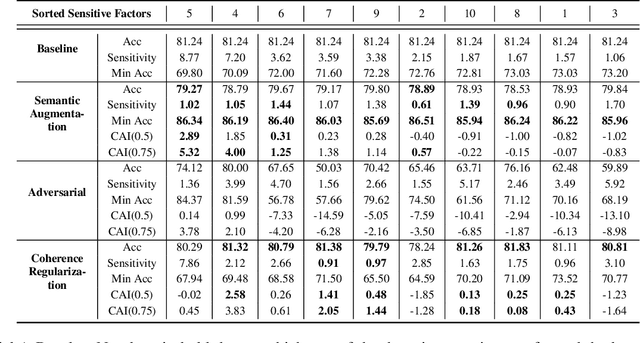
We tackle here a specific, still not widely addressed aspect, of AI robustness, which consists of seeking invariance / insensitivity of model performance to hidden factors of variations in the data. Towards this end, we employ a two step strategy that a) does unsupervised discovery, via generative models, of sensitive factors that cause models to under-perform, and b) intervenes models to make their performance invariant to these sensitive factors' influence. We consider 3 separate interventions for robustness, including: data augmentation, semantic consistency, and adversarial alignment. We evaluate our method using metrics that measure trade offs between invariance (insensitivity) and overall performance (utility) and show the benefits of our method for 3 settings (unsupervised, semi-supervised and generalization).
EdgeMixup: Improving Fairness for Skin Disease Classification and Segmentation
Feb 28, 2022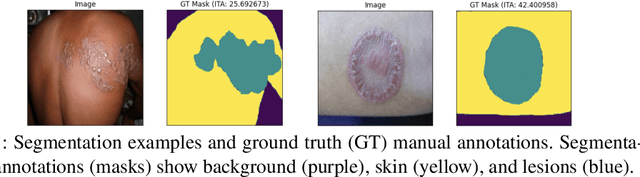
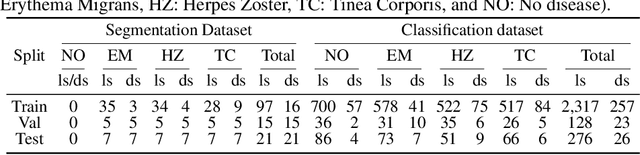


Skin lesions can be an early indicator of a wide range of infectious and other diseases. The use of deep learning (DL) models to diagnose skin lesions has great potential in assisting clinicians with prescreening patients. However, these models often learn biases inherent in training data, which can lead to a performance gap in the diagnosis of people with light and/or dark skin tones. To the best of our knowledge, limited work has been done on identifying, let alone reducing, model bias in skin disease classification and segmentation. In this paper, we examine DL fairness and demonstrate the existence of bias in classification and segmentation models for subpopulations with darker skin tones compared to individuals with lighter skin tones, for specific diseases including Lyme, Tinea Corporis and Herpes Zoster. Then, we propose a novel preprocessing, data alteration method, called EdgeMixup, to improve model fairness with a linear combination of an input skin lesion image and a corresponding a predicted edge detection mask combined with color saturation alteration. For the task of skin disease classification, EdgeMixup outperforms much more complex competing methods such as adversarial approaches, achieving a 10.99% reduction in accuracy gap between light and dark skin tone samples, and resulting in 8.4% improved performance for an underrepresented subpopulation.
Patch Attack Invariance: How Sensitive are Patch Attacks to 3D Pose?
Aug 16, 2021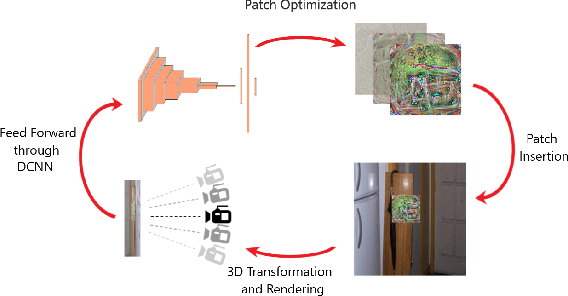
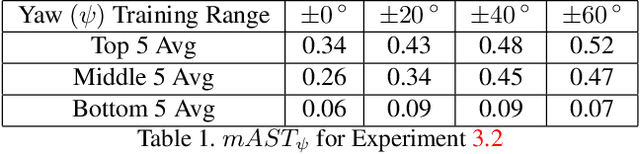

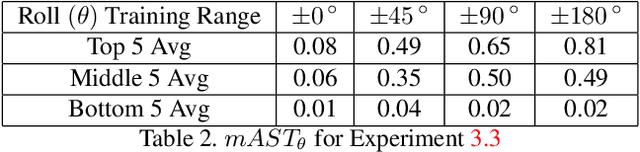
Perturbation-based attacks, while not physically realizable, have been the main emphasis of adversarial machine learning (ML) research. Patch-based attacks by contrast are physically realizable, yet most work has focused on 2D domain with recent forays into 3D. Characterizing the robustness properties of patch attacks and their invariance to 3D pose is important, yet not fully elucidated, and is the focus of this paper. To this end, several contributions are made here: A) we develop a new metric called mean Attack Success over Transformations (mAST) to evaluate patch attack robustness and invariance; and B), we systematically assess robustness of patch attacks to 3D position and orientation for various conditions; in particular, we conduct a sensitivity analysis which provides important qualitative insights into attack effectiveness as a function of the 3D pose of a patch relative to the camera (rotation, translation) and sets forth some properties for patch attack 3D invariance; and C), we draw novel qualitative conclusions including: 1) we demonstrate that for some 3D transformations, namely rotation and loom, increasing the training distribution support yields an increase in patch success over the full range at test time. 2) We provide new insights into the existence of a fundamental cutoff limit in patch attack effectiveness that depends on the extent of out-of-plane rotation angles. These findings should collectively guide future design of 3D patch attacks and defenses.
Generalizing Fairness: Discovery and Mitigation of Unknown Sensitive Attributes
Jul 28, 2021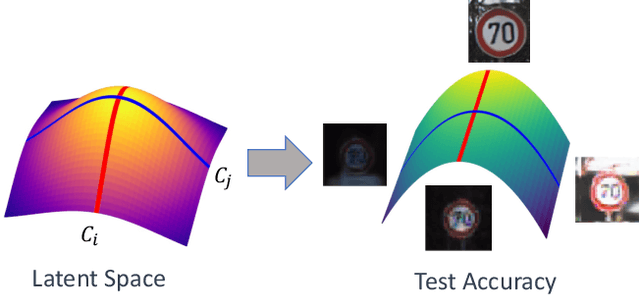
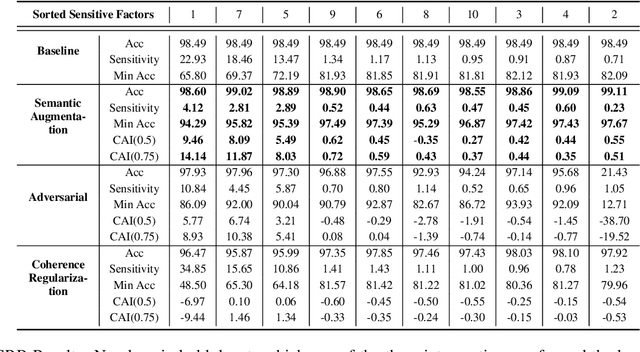
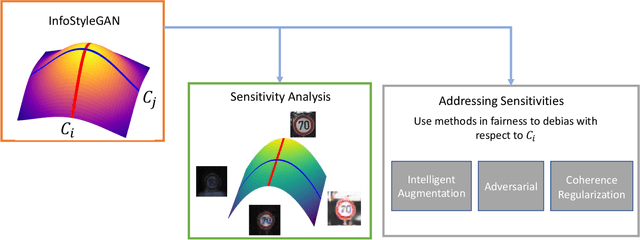
When deploying artificial intelligence (AI) in the real world, being able to trust the operation of the AI by characterizing how it performs is an ever-present and important topic. An important and still largely unexplored task in this characterization is determining major factors within the real world that affect the AI's behavior, such as weather conditions or lighting, and either a) being able to give justification for why it may have failed or b) eliminating the influence the factor has. Determining these sensitive factors heavily relies on collected data that is diverse enough to cover numerous combinations of these factors, which becomes more onerous when having many potential sensitive factors or operating in complex environments. This paper investigates methods that discover and separate out individual semantic sensitive factors from a given dataset to conduct this characterization as well as addressing mitigation of these factors' sensitivity. We also broaden remediation of fairness, which normally only addresses socially relevant factors, and widen it to deal with the desensitization of AI with regard to all possible aspects of variation in the domain. The proposed methods which discover these major factors reduce the potentially onerous demands of collecting a sufficiently diverse dataset. In experiments using the road sign (GTSRB) and facial imagery (CelebA) datasets, we show the promise of using this scheme to perform this characterization and remediation and demonstrate that our approach outperforms state of the art approaches.
Practical Blind Membership Inference Attack via Differential Comparisons
Jan 07, 2021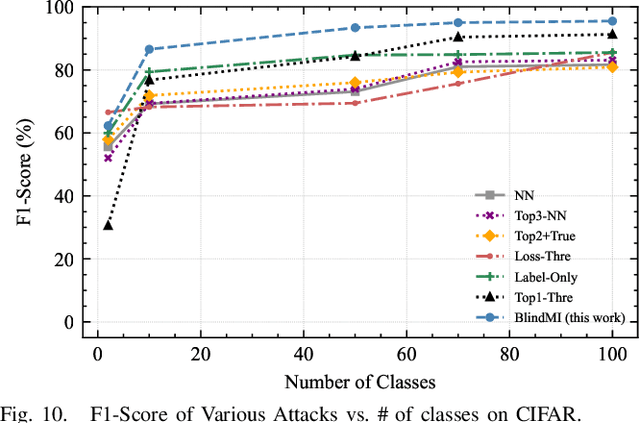
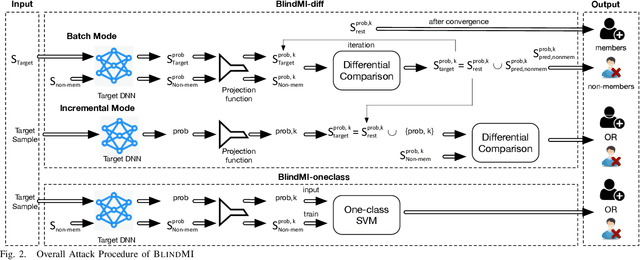
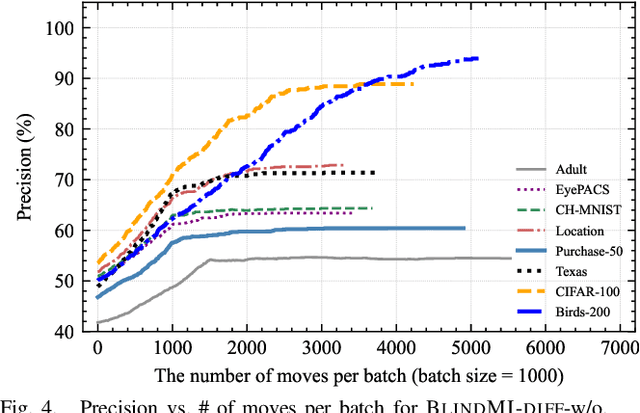
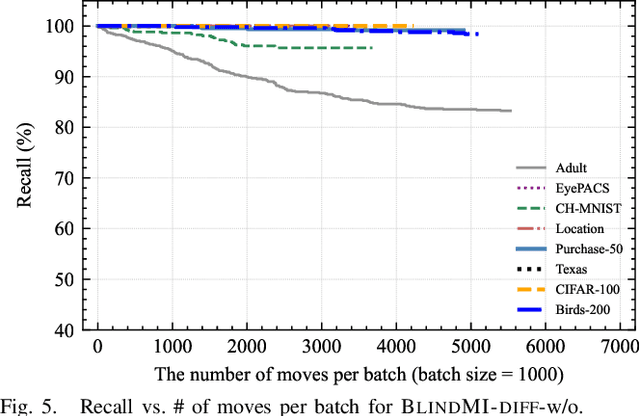
Membership inference (MI) attacks affect user privacy by inferring whether given data samples have been used to train a target learning model, e.g., a deep neural network. There are two types of MI attacks in the literature, i.e., these with and without shadow models. The success of the former heavily depends on the quality of the shadow model, i.e., the transferability between the shadow and the target; the latter, given only blackbox probing access to the target model, cannot make an effective inference of unknowns, compared with MI attacks using shadow models, due to the insufficient number of qualified samples labeled with ground truth membership information. In this paper, we propose an MI attack, called BlindMI, which probes the target model and extracts membership semantics via a novel approach, called differential comparison. The high-level idea is that BlindMI first generates a dataset with nonmembers via transforming existing samples into new samples, and then differentially moves samples from a target dataset to the generated, non-member set in an iterative manner. If the differential move of a sample increases the set distance, BlindMI considers the sample as non-member and vice versa. BlindMI was evaluated by comparing it with state-of-the-art MI attack algorithms. Our evaluation shows that BlindMI improves F1-score by nearly 20% when compared to state-of-the-art on some datasets, such as Purchase-50 and Birds-200, in the blind setting where the adversary does not know the target model's architecture and the target dataset's ground truth labels. We also show that BlindMI can defeat state-of-the-art defenses.