 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Image-Driven Traffic Modeling via Remote Sensing
Mar 08, 2024



This work addresses the task of modeling spatiotemporal traffic patterns directly from overhead imagery, which we refer to as image-driven traffic modeling. We extend this line of work and introduce a multi-modal, multi-task transformer-based segmentation architecture that can be used to create dense city-scale traffic models. Our approach includes a geo-temporal positional encoding module for integrating geo-temporal context and a probabilistic objective function for estimating traffic speeds that naturally models temporal variations. We evaluate our method extensively using the Dynamic Traffic Speeds (DTS) benchmark dataset and significantly improve the state-of-the-art. Finally, we introduce the DTS++ dataset to support mobility-related location adaptation experiments.
Handling Image and Label Resolution Mismatch in Remote Sensing
Nov 28, 2022Though semantic segmentation has been heavily explored in vision literature, unique challenges remain in the remote sensing domain. One such challenge is how to handle resolution mismatch between overhead imagery and ground-truth label sources, due to differences in ground sample distance. To illustrate this problem, we introduce a new dataset and use it to showcase weaknesses inherent in existing strategies that naively upsample the target label to match the image resolution. Instead, we present a method that is supervised using low-resolution labels (without upsampling), but takes advantage of an exemplar set of high-resolution labels to guide the learning process. Our method incorporates region aggregation, adversarial learning, and self-supervised pretraining to generate fine-grained predictions, without requiring high-resolution annotations. Extensive experiments demonstrate the real-world applicability of our approach.
EdgeMixup: Improving Fairness for Skin Disease Classification and Segmentation
Feb 28, 2022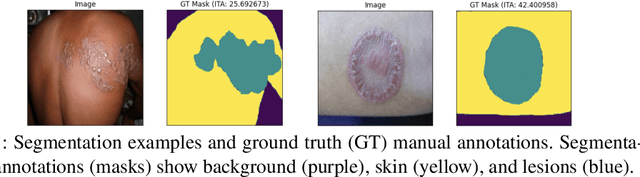
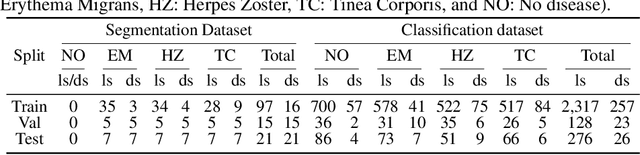


Skin lesions can be an early indicator of a wide range of infectious and other diseases. The use of deep learning (DL) models to diagnose skin lesions has great potential in assisting clinicians with prescreening patients. However, these models often learn biases inherent in training data, which can lead to a performance gap in the diagnosis of people with light and/or dark skin tones. To the best of our knowledge, limited work has been done on identifying, let alone reducing, model bias in skin disease classification and segmentation. In this paper, we examine DL fairness and demonstrate the existence of bias in classification and segmentation models for subpopulations with darker skin tones compared to individuals with lighter skin tones, for specific diseases including Lyme, Tinea Corporis and Herpes Zoster. Then, we propose a novel preprocessing, data alteration method, called EdgeMixup, to improve model fairness with a linear combination of an input skin lesion image and a corresponding a predicted edge detection mask combined with color saturation alteration. For the task of skin disease classification, EdgeMixup outperforms much more complex competing methods such as adversarial approaches, achieving a 10.99% reduction in accuracy gap between light and dark skin tone samples, and resulting in 8.4% improved performance for an underrepresented subpopulation.
Bayesian optimization of distributed neurodynamical controller models for spatial navigation
Oct 31, 2021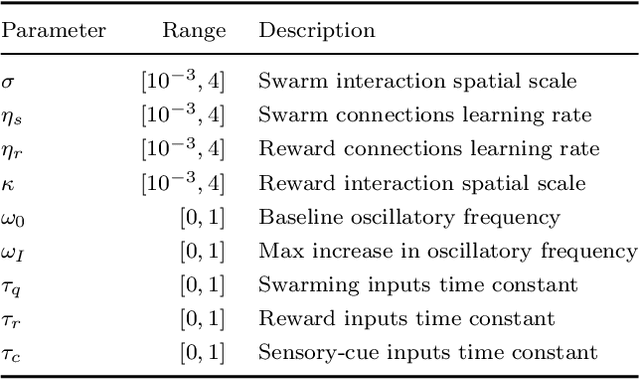

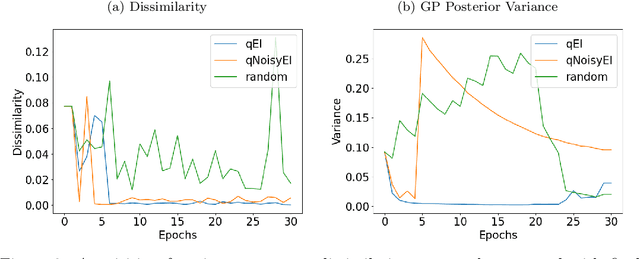
Dynamical systems models for controlling multi-agent swarms have demonstrated advances toward resilient, decentralized navigation algorithms. We previously introduced the NeuroSwarms controller, in which agent-based interactions were modeled by analogy to neuronal network interactions, including attractor dynamics and phase synchrony, that have been theorized to operate within hippocampal place-cell circuits in navigating rodents. This complexity precludes linear analyses of stability, controllability, and performance typically used to study conventional swarm models. Further, tuning dynamical controllers by hand or grid search is often inadequate due to the complexity of objectives, dimensionality of model parameters, and computational costs of simulation-based sampling. Here, we present a framework for tuning dynamical controller models of autonomous multi-agent systems based on Bayesian Optimization (BayesOpt). Our approach utilizes a task-dependent objective function to train Gaussian Processes (GPs) as surrogate models to achieve adaptive and efficient exploration of a dynamical controller model's parameter space. We demonstrate this approach by studying an objective function selecting for NeuroSwarms behaviors that cooperatively localize and capture spatially distributed rewards under time pressure. We generalized task performance across environments by combining scores for simulations in distinct geometries. To validate search performance, we compared high-dimensional clustering for high- vs. low-likelihood parameter points by visualizing sample trajectories in Uniform Manifold Approximation and Projection (UMAP) embeddings. Our findings show that adaptive, sample-efficient evaluation of the self-organizing behavioral capacities of complex systems, including dynamical swarm controllers, can accelerate the translation of neuroscientific theory to applied domains.
Towards Indirect Top-Down Road Transport Emissions Estimation
Mar 16, 2021

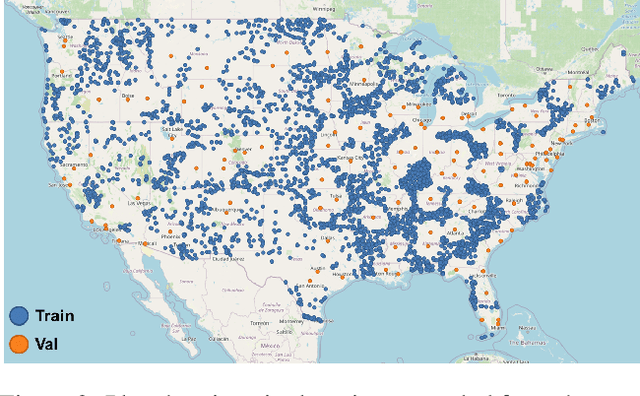

Road transportation is one of the largest sectors of greenhouse gas (GHG) emissions affecting climate change. Tackling climate change as a global community will require new capabilities to measure and inventory road transport emissions. However, the large scale and distributed nature of vehicle emissions make this sector especially challenging for existing inventory methods. In this work, we develop machine learning models that use satellite imagery to perform indirect top-down estimation of road transport emissions. Our initial experiments focus on the United States, where a bottom-up inventory was available for training our models. We achieved a mean absolute error (MAE) of 39.5 kg CO$_{2}$ of annual road transport emissions, calculated on a pixel-by-pixel (100 m$^{2}$) basis in Sentinel-2 imagery. We also discuss key model assumptions and challenges that need to be addressed to develop models capable of generalizing to global geography. We believe this work is the first published approach for automated indirect top-down estimation of road transport sector emissions using visual imagery and represents a critical step towards scalable, global, near-real-time road transportation emissions inventories that are measured both independently and objectively.
RENATA: REpreseNtation And Training Alteration for Bias Mitigation
Dec 11, 2020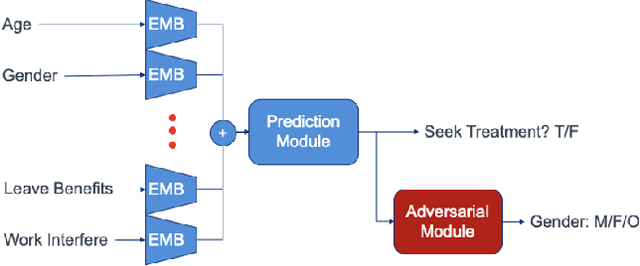
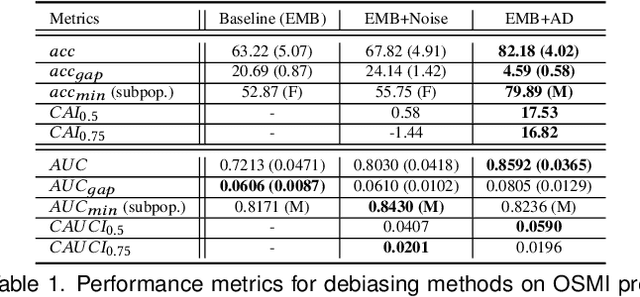
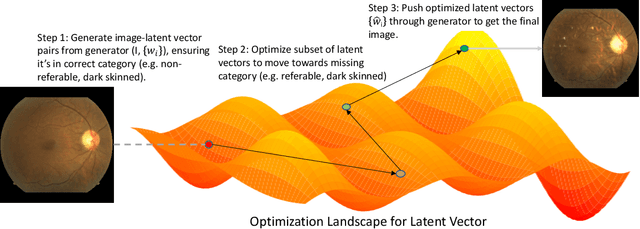
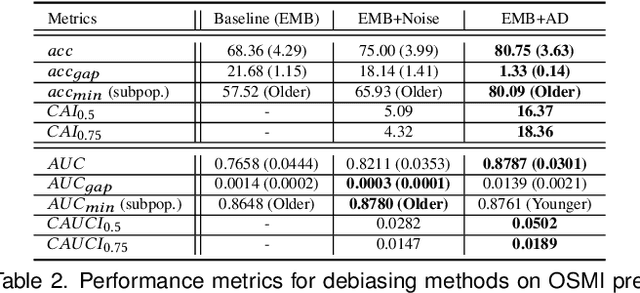
We propose a novel method for enforcing AI fairness with respect to protected or sensitive factors. This method uses a dual strategy performing Training And Representation Alteration (RENATA) for mitigation of two of the most prominent causes of AI bias, including: a) the use of representation learning alteration via adversarial independence, to suppress the bias-inducing dependence of the data representation from protected factors; and b) training set alteration via intelligent augmentation, to address bias-causing data imbalance, by using generative models that allow fine control of sensitive factors related to underrepresented populations. When testing our methods on image analytics, experiments demonstrate that RENATA significantly or fully debiases baseline models while outperforming competing debiasing methods, e.g., with (% overall accuracy, % accuracy gap) of (78.75, 0.5) vs. baseline method's (71.75, 10.5) for EyePACS, and (73.71, 11.82) vs. the (69.08, 21.65) baseline for CelebA. As an additional contribution, recognizing certain limitations in current metrics used for assessing debiasing performance, this study proposes novel conjunctive debiasing metrics. Our experiments also demonstrate the ability of these novel metrics in assessing the Pareto efficiency of the proposed methods.
Estimating Displaced Populations from Overhead
Jun 25, 2020



We introduce a deep learning approach to perform fine-grained population estimation for displacement camps using high-resolution overhead imagery. We train and evaluate our approach on drone imagery cross-referenced with population data for refugee camps in Cox's Bazar, Bangladesh in 2018 and 2019. Our proposed approach achieves 7.41% mean absolute percent error on sequestered camp imagery. We believe our experiments with real-world displacement camp data constitute an important step towards the development of tools that enable the humanitarian community to effectively and rapidly respond to the global displacement crisis.
RasterNet: Modeling Free-Flow Speed using LiDAR and Overhead Imagery
Jun 14, 2020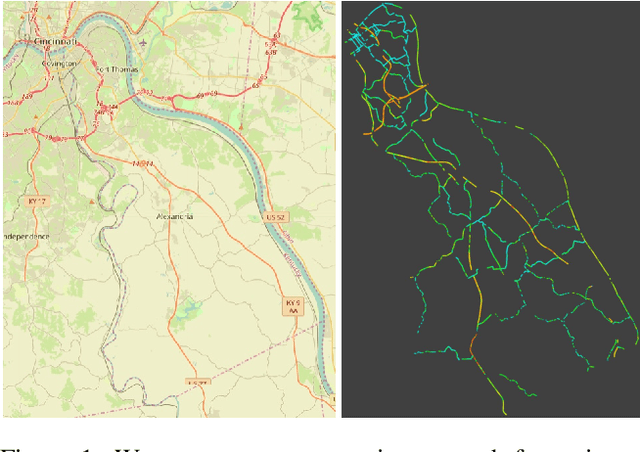
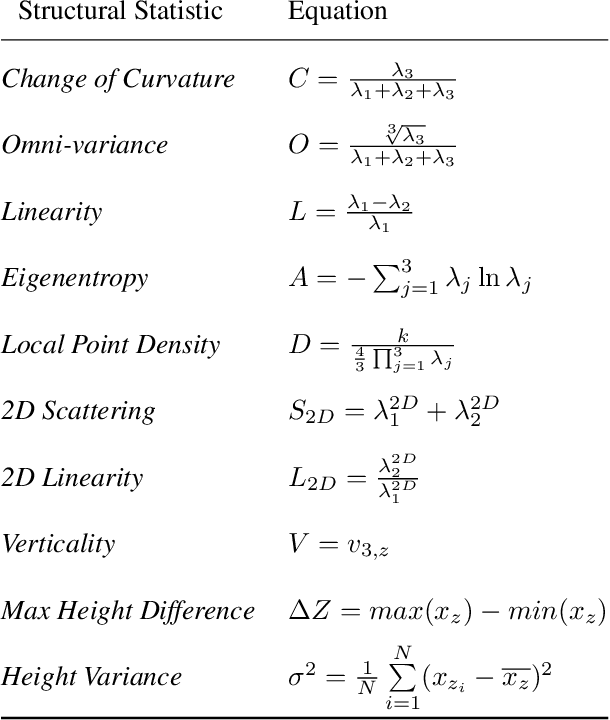


Roadway free-flow speed captures the typical vehicle speed in low traffic conditions. Modeling free-flow speed is an important problem in transportation engineering with applications to a variety of design, operation, planning, and policy decisions of highway systems. Unfortunately, collecting large-scale historical traffic speed data is expensive and time consuming. Traditional approaches for estimating free-flow speed use geometric properties of the underlying road segment, such as grade, curvature, lane width, lateral clearance and access point density, but for many roads such features are unavailable. We propose a fully automated approach, RasterNet, for estimating free-flow speed without the need for explicit geometric features. RasterNet is a neural network that fuses large-scale overhead imagery and aerial LiDAR point clouds using a geospatially consistent raster structure. To support training and evaluation, we introduce a novel dataset combining free-flow speeds of road segments, overhead imagery, and LiDAR point clouds across the state of Kentucky. Our method achieves state-of-the-art results on a benchmark dataset.
FARSA: Fully Automated Roadway Safety Assessment
Jan 17, 2019
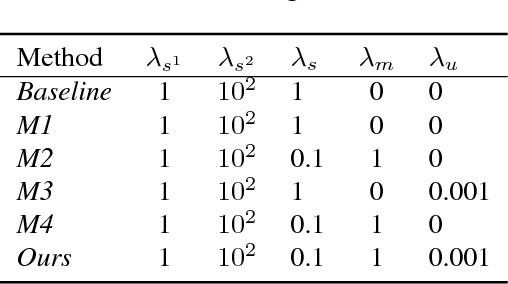

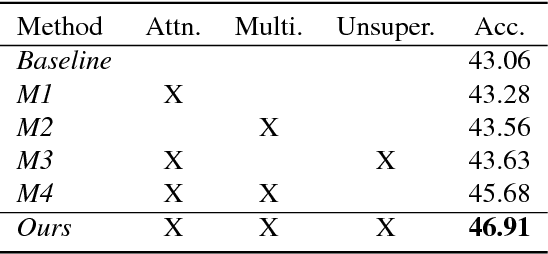
This paper addresses the task of road safety assessment. An emerging approach for conducting such assessments in the United States is through the US Road Assessment Program (usRAP), which rates roads from highest risk (1 star) to lowest (5 stars). Obtaining these ratings requires manual, fine-grained labeling of roadway features in street-level panoramas, a slow and costly process. We propose to automate this process using a deep convolutional neural network that directly estimates the star rating from a street-level panorama, requiring milliseconds per image at test time. Our network also estimates many other road-level attributes, including curvature, roadside hazards, and the type of median. To support this, we incorporate task-specific attention layers so the network can focus on the panorama regions that are most useful for a particular task. We evaluated our approach on a large dataset of real-world images from two US states. We found that incorporating additional tasks, and using a semi-supervised training approach, significantly reduced overfitting problems, allowed us to optimize more layers of the network, and resulted in higher accuracy.