 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Fairness via Domain Adaptation
Mar 15, 2021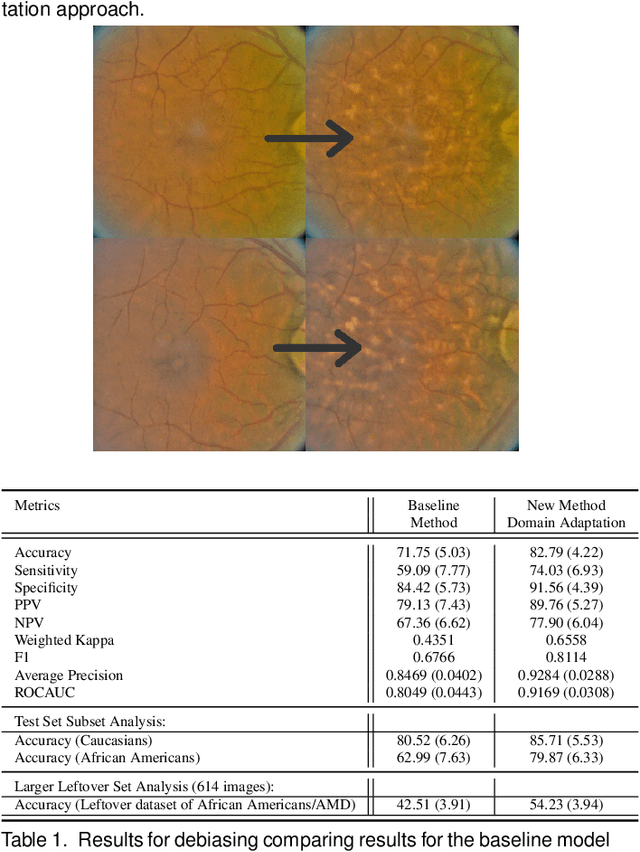
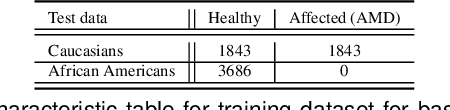
While deep learning (DL) approaches are reaching human-level performance for many tasks, including for diagnostics AI, the focus is now on challenges possibly affecting DL deployment, including AI privacy, domain generalization, and fairness. This last challenge is addressed in this study. Here we look at a novel method for ensuring AI fairness with respect to protected or sensitive factors. This method uses domain adaptation via training set enhancement to tackle bias-causing training data imbalance. More specifically, it uses generative models that allow the generation of more synthetic training samples for underrepresented populations. This paper applies this method to the use case of detection of age related macular degeneration (AMD). Our experiments show that starting with an originally biased AMD diagnostics model the method has the ability to improve fairness.
Defending Medical Image Diagnostics against Privacy Attacks using Generative Methods
Mar 04, 2021
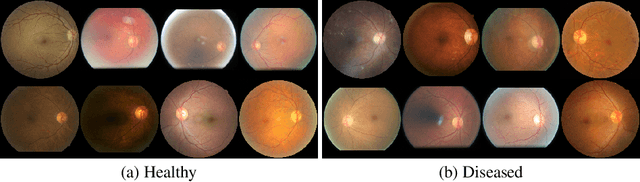
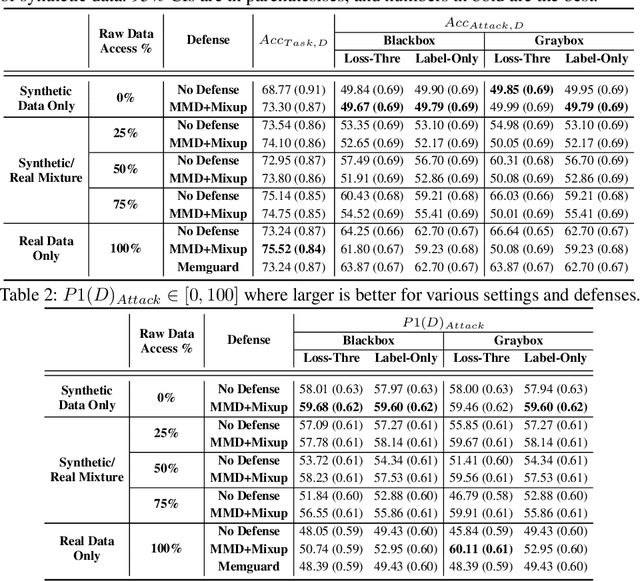

Machine learning (ML) models used in medical imaging diagnostics can be vulnerable to a variety of privacy attacks, including membership inference attacks, that lead to violations of regulations governing the use of medical data and threaten to compromise their effective deployment in the clinic. In contrast to most recent work in privacy-aware ML that has been focused on model alteration and post-processing steps, we propose here a novel and complementary scheme that enhances the security of medical data by controlling the data sharing process. We develop and evaluate a privacy defense protocol based on using a generative adversarial network (GAN) that allows a medical data sourcer (e.g. a hospital) to provide an external agent (a modeler) a proxy dataset synthesized from the original images, so that the resulting diagnostic systems made available to model consumers is rendered resilient to privacy attackers. We validate the proposed method on retinal diagnostics AI used for diabetic retinopathy that bears the risk of possibly leaking private information. To incorporate concerns of both privacy advocates and modelers, we introduce a metric to evaluate privacy and utility performance in combination, and demonstrate, using these novel and classical metrics, that our approach, by itself or in conjunction with other defenses, provides state of the art (SOTA) performance for defending against privacy attacks.
RENATA: REpreseNtation And Training Alteration for Bias Mitigation
Dec 11, 2020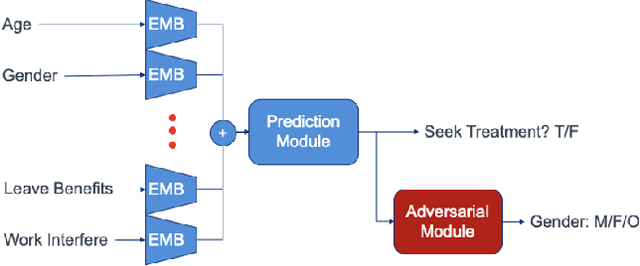
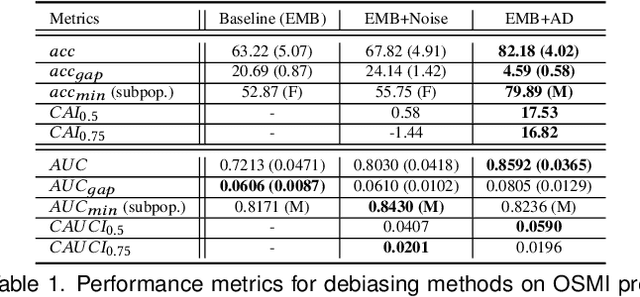
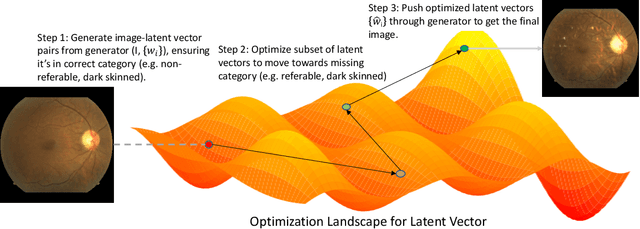
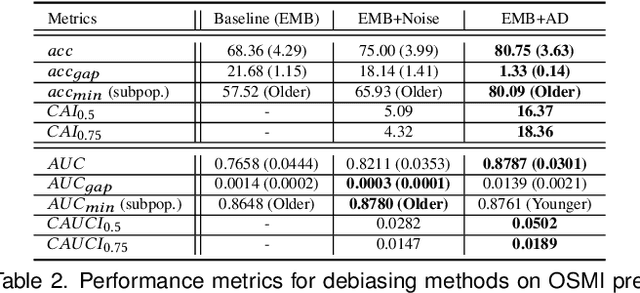
We propose a novel method for enforcing AI fairness with respect to protected or sensitive factors. This method uses a dual strategy performing Training And Representation Alteration (RENATA) for mitigation of two of the most prominent causes of AI bias, including: a) the use of representation learning alteration via adversarial independence, to suppress the bias-inducing dependence of the data representation from protected factors; and b) training set alteration via intelligent augmentation, to address bias-causing data imbalance, by using generative models that allow fine control of sensitive factors related to underrepresented populations. When testing our methods on image analytics, experiments demonstrate that RENATA significantly or fully debiases baseline models while outperforming competing debiasing methods, e.g., with (% overall accuracy, % accuracy gap) of (78.75, 0.5) vs. baseline method's (71.75, 10.5) for EyePACS, and (73.71, 11.82) vs. the (69.08, 21.65) baseline for CelebA. As an additional contribution, recognizing certain limitations in current metrics used for assessing debiasing performance, this study proposes novel conjunctive debiasing metrics. Our experiments also demonstrate the ability of these novel metrics in assessing the Pareto efficiency of the proposed methods.