 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptAgent: LLM-Driven Precondition Grounding and Tree Search for Robust Task Planning and Execution
Oct 08, 2024



Robotic planning and execution in open-world environments is a complex problem due to the vast state spaces and high variability of task embodiment. Recent advances in perception algorithms, combined with Large Language Models (LLMs) for planning, offer promising solutions to these challenges, as the common sense reasoning capabilities of LLMs provide a strong heuristic for efficiently searching the action space. However, prior work fails to address the possibility of hallucinations from LLMs, which results in failures to execute the planned actions largely due to logical fallacies at high- or low-levels. To contend with automation failure due to such hallucinations, we introduce ConceptAgent, a natural language-driven robotic platform designed for task execution in unstructured environments. With a focus on scalability and reliability of LLM-based planning in complex state and action spaces, we present innovations designed to limit these shortcomings, including 1) Predicate Grounding to prevent and recover from infeasible actions, and 2) an embodied version of LLM-guided Monte Carlo Tree Search with self reflection. In simulation experiments, ConceptAgent achieved a 19% task completion rate across three room layouts and 30 easy level embodied tasks outperforming other state-of-the-art LLM-driven reasoning baselines that scored 10.26% and 8.11% on the same benchmark. Additionally, ablation studies on moderate to hard embodied tasks revealed a 20% increase in task completion from the baseline agent to the fully enhanced ConceptAgent, highlighting the individual and combined contributions of Predicate Grounding and LLM-guided Tree Search to enable more robust automation in complex state and action spaces.
An Evaluation of Large Pre-Trained Models for Gesture Recognition using Synthetic Videos
Oct 03, 2024In this work, we explore the possibility of using synthetically generated data for video-based gesture recognition with large pre-trained models. We consider whether these models have sufficiently robust and expressive representation spaces to enable "training-free" classification. Specifically, we utilize various state-of-the-art video encoders to extract features for use in k-nearest neighbors classification, where the training data points are derived from synthetic videos only. We compare these results with another training-free approach -- zero-shot classification using text descriptions of each gesture. In our experiments with the RoCoG-v2 dataset, we find that using synthetic training videos yields significantly lower classification accuracy on real test videos compared to using a relatively small number of real training videos. We also observe that video backbones that were fine-tuned on classification tasks serve as superior feature extractors, and that the choice of fine-tuning data has a substantial impact on k-nearest neighbors performance. Lastly, we find that zero-shot text-based classification performs poorly on the gesture recognition task, as gestures are not easily described through natural language.
* Synthetic Data for Artificial Intelligence and Machine Learning: Tools, Techniques, and Applications II (SPIE Defense + Commercial Sensing, 2024)
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Dec 06, 2023



In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.
ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
Sep 28, 2023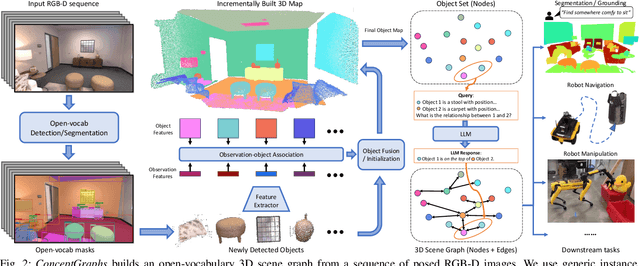
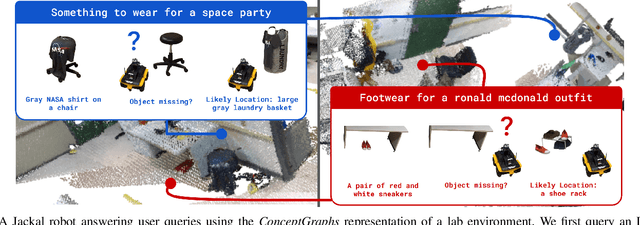
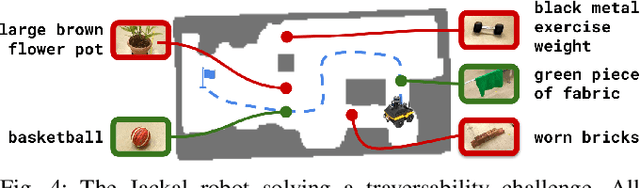
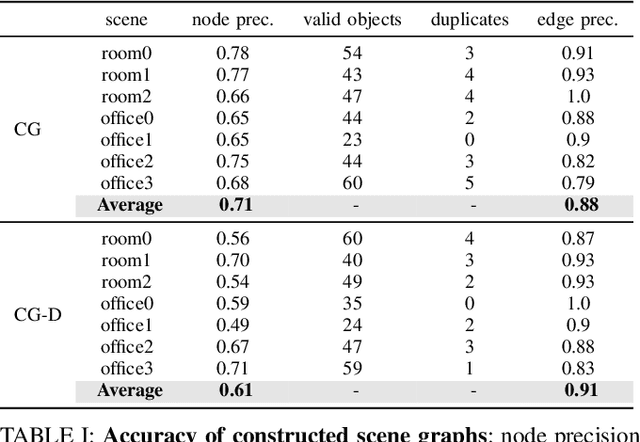
For robots to perform a wide variety of tasks, they require a 3D representation of the world that is semantically rich, yet compact and efficient for task-driven perception and planning. Recent approaches have attempted to leverage features from large vision-language models to encode semantics in 3D representations. However, these approaches tend to produce maps with per-point feature vectors, which do not scale well in larger environments, nor do they contain semantic spatial relationships between entities in the environment, which are useful for downstream planning. In this work, we propose ConceptGraphs, an open-vocabulary graph-structured representation for 3D scenes. ConceptGraphs is built by leveraging 2D foundation models and fusing their output to 3D by multi-view association. The resulting representations generalize to novel semantic classes, without the need to collect large 3D datasets or finetune models. We demonstrate the utility of this representation through a number of downstream planning tasks that are specified through abstract (language) prompts and require complex reasoning over spatial and semantic concepts. (Project page: https://concept-graphs.github.io/ Explainer video: https://youtu.be/mRhNkQwRYnc )
Synthetic-to-Real Domain Adaptation for Action Recognition: A Dataset and Baseline Performances
Mar 17, 2023

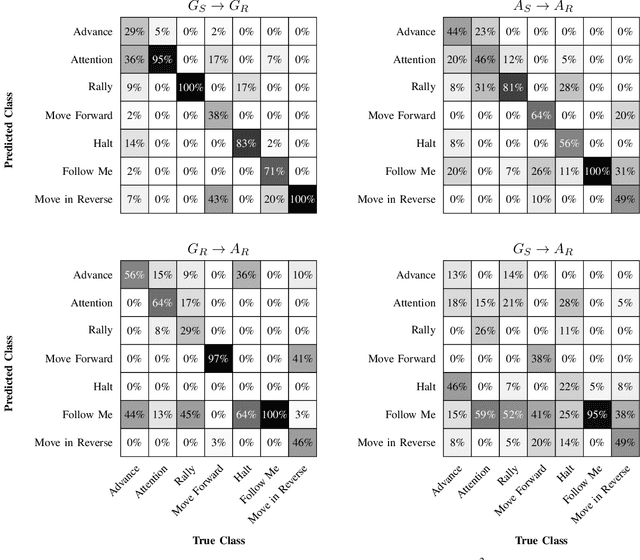
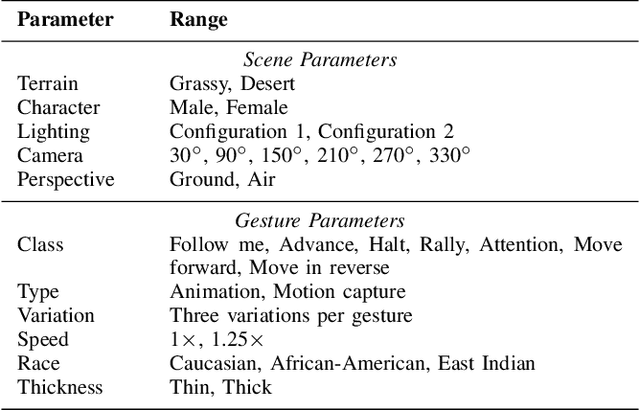
Human action recognition is a challenging problem, particularly when there is high variability in factors such as subject appearance, backgrounds and viewpoint. While deep neural networks (DNNs) have been shown to perform well on action recognition tasks, they typically require large amounts of high-quality labeled data to achieve robust performance across a variety of conditions. Synthetic data has shown promise as a way to avoid the substantial costs and potential ethical concerns associated with collecting and labeling enormous amounts of data in the real-world. However, synthetic data may differ from real data in important ways. This phenomenon, known as \textit{domain shift}, can limit the utility of synthetic data in robotics applications. To mitigate the effects of domain shift, substantial effort is being dedicated to the development of domain adaptation (DA) techniques. Yet, much remains to be understood about how best to develop these techniques. In this paper, we introduce a new dataset called Robot Control Gestures (RoCoG-v2). The dataset is composed of both real and synthetic videos from seven gesture classes, and is intended to support the study of synthetic-to-real domain shift for video-based action recognition. Our work expands upon existing datasets by focusing the action classes on gestures for human-robot teaming, as well as by enabling investigation of domain shift in both ground and aerial views. We present baseline results using state-of-the-art action recognition and domain adaptation algorithms and offer initial insight on tackling the synthetic-to-real and ground-to-air domain shifts.
Evaluating Trade-offs in Computer Vision Between Attribute Privacy, Fairness and Utility
Feb 15, 2023



This paper investigates to what degree and magnitude tradeoffs exist between utility, fairness and attribute privacy in computer vision. Regarding privacy, we look at this important problem specifically in the context of attribute inference attacks, a less addressed form of privacy. To create a variety of models with different preferences, we use adversarial methods to intervene on attributes relating to fairness and privacy. We see that that certain tradeoffs exist between fairness and utility, privacy and utility, and between privacy and fairness. The results also show that those tradeoffs and interactions are more complex and nonlinear between the three goals than intuition would suggest.
Achieving Utility, Fairness, and Compactness via Tunable Information Bottleneck Measures
Jun 20, 2022

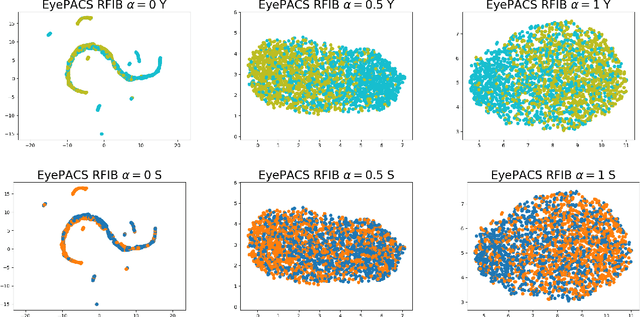

Designing machine learning algorithms that are accurate yet fair, not discriminating based on any sensitive attribute, is of paramount importance for society to accept AI for critical applications. In this article, we propose a novel fair representation learning method termed the R\'enyi Fair Information Bottleneck Method (RFIB) which incorporates constraints for utility, fairness, and compactness of representation, and apply it to image classification. A key attribute of our approach is that we consider - in contrast to most prior work - both demographic parity and equalized odds as fairness constraints, allowing for a more nuanced satisfaction of both criteria. Leveraging a variational approach, we show that our objectives yield a loss function involving classical Information Bottleneck (IB) measures and establish an upper bound in terms of the R\'enyi divergence of order $\alpha$ on the mutual information IB term measuring compactness between the input and its encoded embedding. Experimenting on three different image datasets (EyePACS, CelebA, and FairFace), we study the influence of the $\alpha$ parameter as well as two other tunable IB parameters on achieving utility/fairness trade-off goals, and show that the $\alpha$ parameter gives an additional degree of freedom that can be used to control the compactness of the representation. We evaluate the performance of our method using various utility, fairness, and compound utility/fairness metrics, showing that RFIB outperforms current state-of-the-art approaches.
Renyi Fair Information Bottleneck for Image Classification
Mar 09, 2022
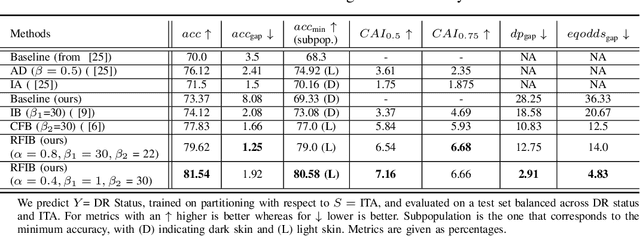
We develop a novel method for ensuring fairness in machine learning which we term as the Renyi Fair Information Bottleneck (RFIB). We consider two different fairness constraints - demographic parity and equalized odds - for learning fair representations and derive a loss function via a variational approach that uses Renyi's divergence with its tunable parameter $\alpha$ and that takes into account the triple constraints of utility, fairness, and compactness of representation. We then evaluate the performance of our method for image classification using the EyePACS medical imaging dataset, showing it outperforms competing state of the art techniques with performance measured using a variety of compound utility/fairness metrics, including accuracy gap and Rawls' minimal accuracy.
Robustness and Adaptation to Hidden Factors of Variation
Mar 03, 2022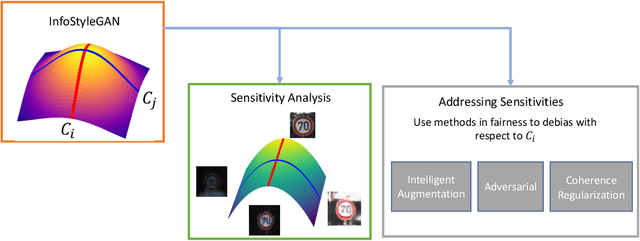
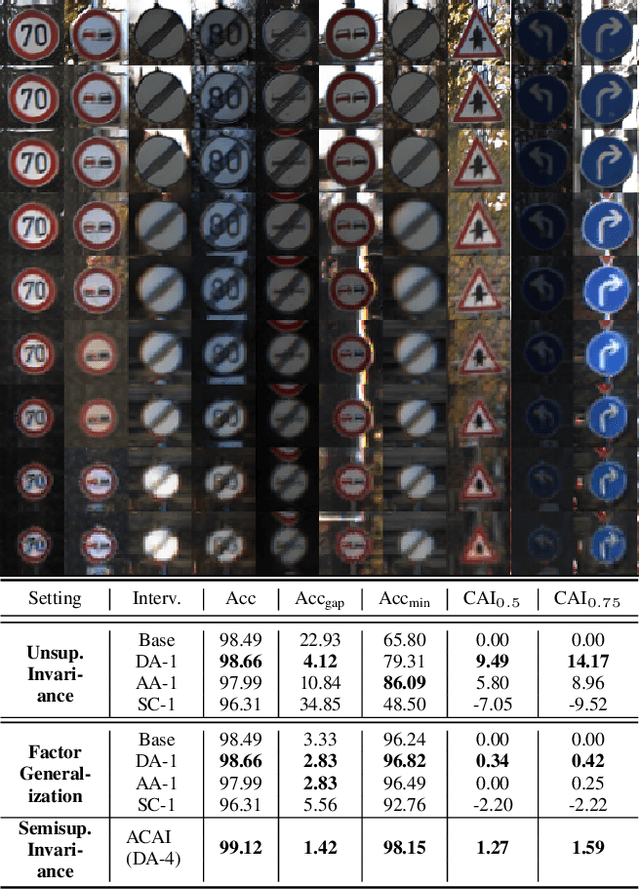

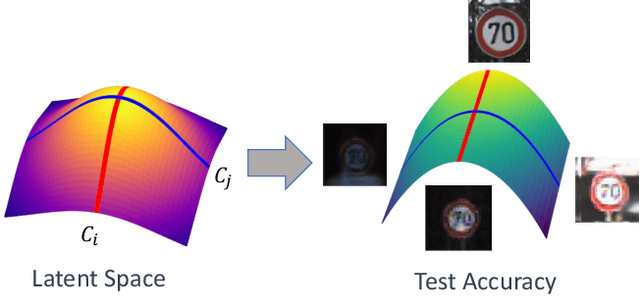
We tackle here a specific, still not widely addressed aspect, of AI robustness, which consists of seeking invariance / insensitivity of model performance to hidden factors of variations in the data. Towards this end, we employ a two step strategy that a) does unsupervised discovery, via generative models, of sensitive factors that cause models to under-perform, and b) intervenes models to make their performance invariant to these sensitive factors' influence. We consider 3 separate interventions for robustness, including: data augmentation, semantic consistency, and adversarial alignment. We evaluate our method using metrics that measure trade offs between invariance (insensitivity) and overall performance (utility) and show the benefits of our method for 3 settings (unsupervised, semi-supervised and generalization).
EdgeMixup: Improving Fairness for Skin Disease Classification and Segmentation
Feb 28, 2022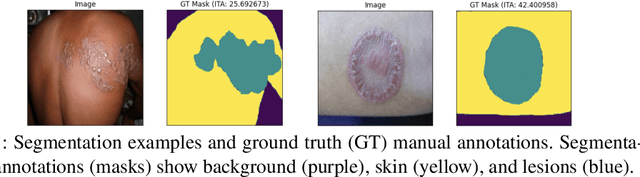
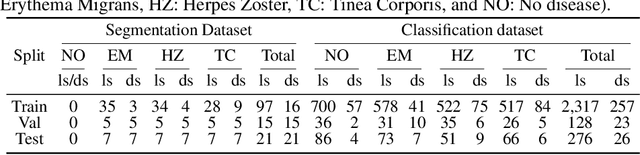


Skin lesions can be an early indicator of a wide range of infectious and other diseases. The use of deep learning (DL) models to diagnose skin lesions has great potential in assisting clinicians with prescreening patients. However, these models often learn biases inherent in training data, which can lead to a performance gap in the diagnosis of people with light and/or dark skin tones. To the best of our knowledge, limited work has been done on identifying, let alone reducing, model bias in skin disease classification and segmentation. In this paper, we examine DL fairness and demonstrate the existence of bias in classification and segmentation models for subpopulations with darker skin tones compared to individuals with lighter skin tones, for specific diseases including Lyme, Tinea Corporis and Herpes Zoster. Then, we propose a novel preprocessing, data alteration method, called EdgeMixup, to improve model fairness with a linear combination of an input skin lesion image and a corresponding a predicted edge detection mask combined with color saturation alteration. For the task of skin disease classification, EdgeMixup outperforms much more complex competing methods such as adversarial approaches, achieving a 10.99% reduction in accuracy gap between light and dark skin tone samples, and resulting in 8.4% improved performance for an underrepresented subpopulation.