 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning
Sep 28, 2023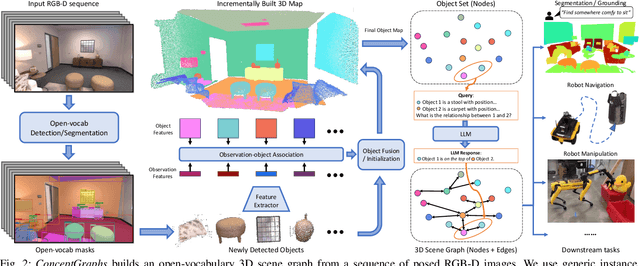
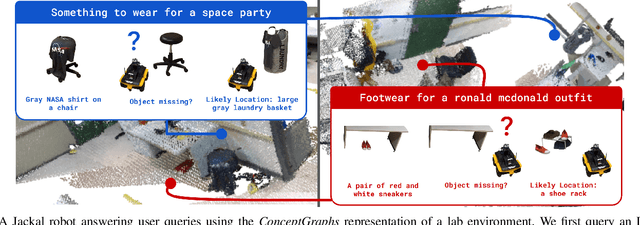
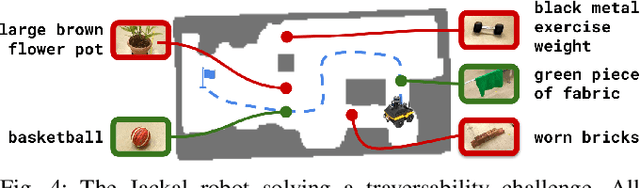
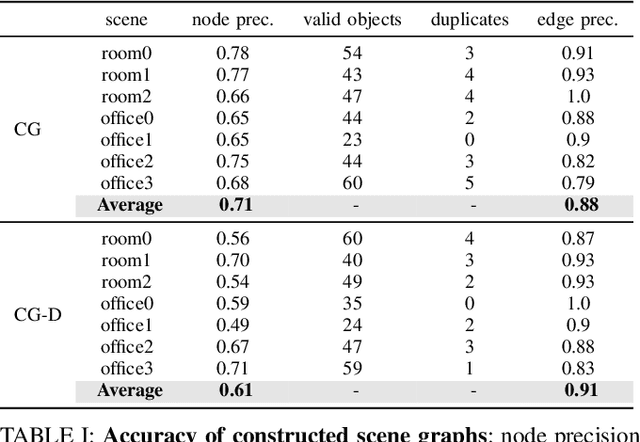
For robots to perform a wide variety of tasks, they require a 3D representation of the world that is semantically rich, yet compact and efficient for task-driven perception and planning. Recent approaches have attempted to leverage features from large vision-language models to encode semantics in 3D representations. However, these approaches tend to produce maps with per-point feature vectors, which do not scale well in larger environments, nor do they contain semantic spatial relationships between entities in the environment, which are useful for downstream planning. In this work, we propose ConceptGraphs, an open-vocabulary graph-structured representation for 3D scenes. ConceptGraphs is built by leveraging 2D foundation models and fusing their output to 3D by multi-view association. The resulting representations generalize to novel semantic classes, without the need to collect large 3D datasets or finetune models. We demonstrate the utility of this representation through a number of downstream planning tasks that are specified through abstract (language) prompts and require complex reasoning over spatial and semantic concepts. (Project page: https://concept-graphs.github.io/ Explainer video: https://youtu.be/mRhNkQwRYnc )
ConceptFusion: Open-set Multimodal 3D Mapping
Feb 15, 2023Building 3D maps of the environment is central to robot navigation, planning, and interaction with objects in a scene. Most existing approaches that integrate semantic concepts with 3D maps largely remain confined to the closed-set setting: they can only reason about a finite set of concepts, pre-defined at training time. Further, these maps can only be queried using class labels, or in recent work, using text prompts. We address both these issues with ConceptFusion, a scene representation that is (1) fundamentally open-set, enabling reasoning beyond a closed set of concepts and (ii) inherently multimodal, enabling a diverse range of possible queries to the 3D map, from language, to images, to audio, to 3D geometry, all working in concert. ConceptFusion leverages the open-set capabilities of today's foundation models pre-trained on internet-scale data to reason about concepts across modalities such as natural language, images, and audio. We demonstrate that pixel-aligned open-set features can be fused into 3D maps via traditional SLAM and multi-view fusion approaches. This enables effective zero-shot spatial reasoning, not needing any additional training or finetuning, and retains long-tailed concepts better than supervised approaches, outperforming them by more than 40% margin on 3D IoU. We extensively evaluate ConceptFusion on a number of real-world datasets, simulated home environments, a real-world tabletop manipulation task, and an autonomous driving platform. We showcase new avenues for blending foundation models with 3D open-set multimodal mapping. For more information, visit our project page https://concept-fusion.github.io or watch our 5-minute explainer video https://www.youtube.com/watch?v=rkXgws8fiDs
Augmenting Imitation Experience via Equivariant Representations
Oct 14, 2021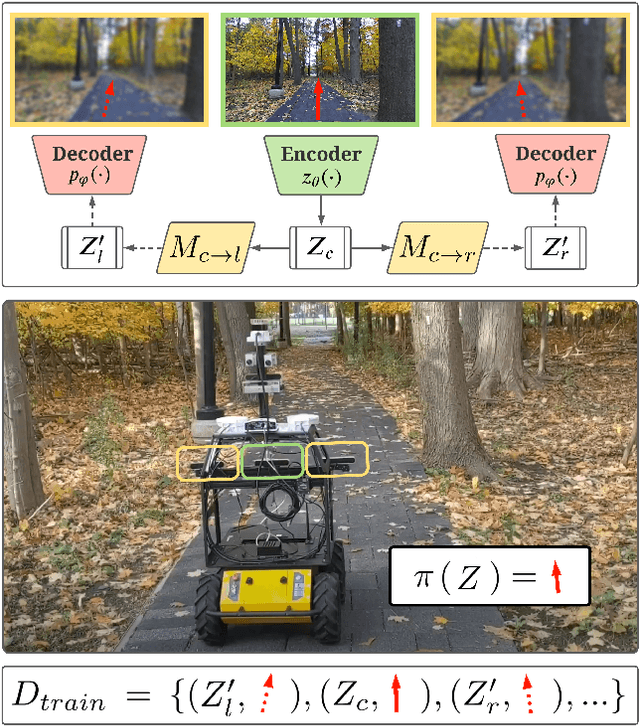
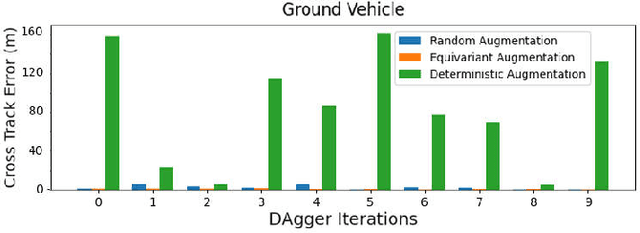
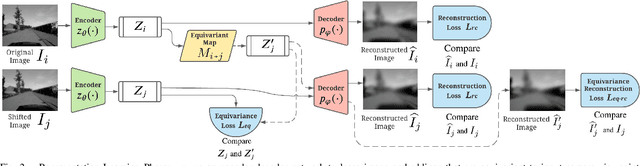

The robustness of visual navigation policies trained through imitation often hinges on the augmentation of the training image-action pairs. Traditionally, this has been done by collecting data from multiple cameras, by using standard data augmentations from computer vision, such as adding random noise to each image, or by synthesizing training images. In this paper we show that there is another practical alternative for data augmentation for visual navigation based on extrapolating viewpoint embeddings and actions nearby the ones observed in the training data. Our method makes use of the geometry of the visual navigation problem in 2D and 3D and relies on policies that are functions of equivariant embeddings, as opposed to images. Given an image-action pair from a training navigation dataset, our neural network model predicts the latent representations of images at nearby viewpoints, using the equivariance property, and augments the dataset. We then train a policy on the augmented dataset. Our simulation results indicate that policies trained in this way exhibit reduced cross-track error, and require fewer interventions compared to policies trained using standard augmentation methods. We also show similar results in autonomous visual navigation by a real ground robot along a path of over 500m.