 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Planning in Complex Environments with Superquadrics and Voronoi-Based Orientation
Nov 08, 2024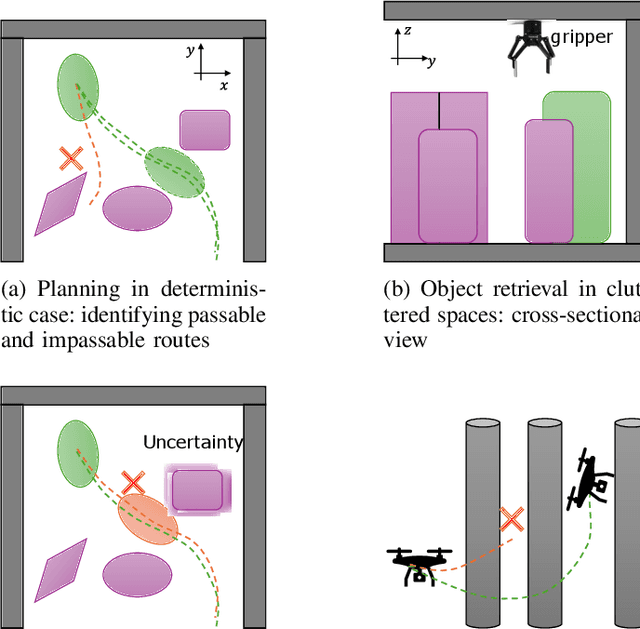
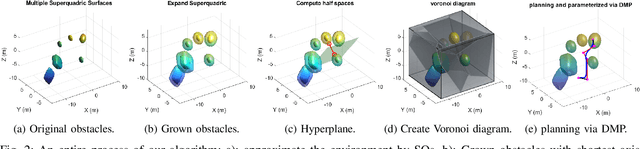
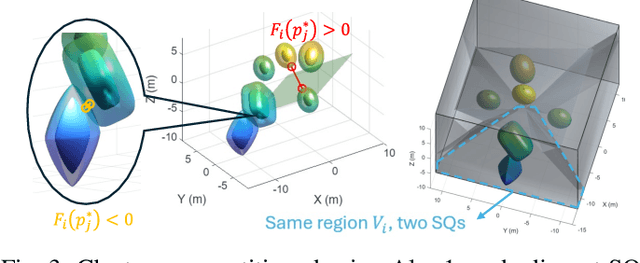
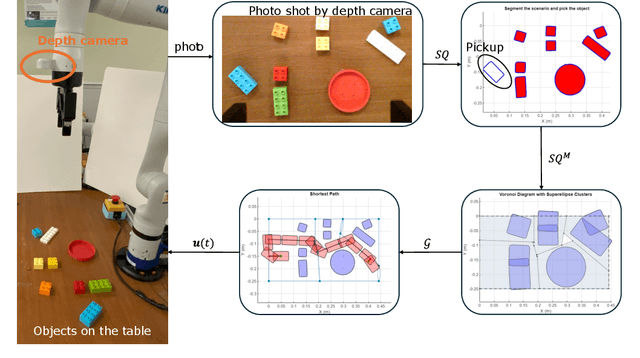
Path planning in narrow passages is a challenging problem in various applications. Traditional planning algorithms often face challenges in complex environments like mazes and traps, where narrow entrances require special orientation control for successful navigation. In this work, we present a novel approach that combines superquadrics (SQ) representation and Voronoi diagrams to solve the narrow passage problem in both 2D and 3D environment. Our method utilizes the SQ formulation to expand obstacles, eliminating impassable passages, while Voronoi hyperplane ensures maximum clearance path. Additionally, the hyperplane provides a natural reference for robot orientation, aligning its long axis with the passage direction. We validate our framework through a 2D object retrieval task and 3D drone simulation, demonstrating that our approach outperforms classical planners and a cutting-edge drone planner by ensuring passable trajectories with maximum clearance.
Mesh Strikes Back: Fast and Efficient Human Reconstruction from RGB videos
Mar 15, 2023Human reconstruction and synthesis from monocular RGB videos is a challenging problem due to clothing, occlusion, texture discontinuities and sharpness, and framespecific pose changes. Many methods employ deferred rendering, NeRFs and implicit methods to represent clothed humans, on the premise that mesh-based representations cannot capture complex clothing and textures from RGB, silhouettes, and keypoints alone. We provide a counter viewpoint to this fundamental premise by optimizing a SMPL+D mesh and an efficient, multi-resolution texture representation using only RGB images, binary silhouettes and sparse 2D keypoints. Experimental results demonstrate that our approach is more capable of capturing geometric details compared to visual hull, mesh-based methods. We show competitive novel view synthesis and improvements in novel pose synthesis compared to NeRF-based methods, which introduce noticeable, unwanted artifacts. By restricting the solution space to the SMPL+D model combined with differentiable rendering, we obtain dramatic speedups in compute, training times (up to 24x) and inference times (up to 192x). Our method therefore can be used as is or as a fast initialization to NeRF-based methods.
ConceptFusion: Open-set Multimodal 3D Mapping
Feb 15, 2023Building 3D maps of the environment is central to robot navigation, planning, and interaction with objects in a scene. Most existing approaches that integrate semantic concepts with 3D maps largely remain confined to the closed-set setting: they can only reason about a finite set of concepts, pre-defined at training time. Further, these maps can only be queried using class labels, or in recent work, using text prompts. We address both these issues with ConceptFusion, a scene representation that is (1) fundamentally open-set, enabling reasoning beyond a closed set of concepts and (ii) inherently multimodal, enabling a diverse range of possible queries to the 3D map, from language, to images, to audio, to 3D geometry, all working in concert. ConceptFusion leverages the open-set capabilities of today's foundation models pre-trained on internet-scale data to reason about concepts across modalities such as natural language, images, and audio. We demonstrate that pixel-aligned open-set features can be fused into 3D maps via traditional SLAM and multi-view fusion approaches. This enables effective zero-shot spatial reasoning, not needing any additional training or finetuning, and retains long-tailed concepts better than supervised approaches, outperforming them by more than 40% margin on 3D IoU. We extensively evaluate ConceptFusion on a number of real-world datasets, simulated home environments, a real-world tabletop manipulation task, and an autonomous driving platform. We showcase new avenues for blending foundation models with 3D open-set multimodal mapping. For more information, visit our project page https://concept-fusion.github.io or watch our 5-minute explainer video https://www.youtube.com/watch?v=rkXgws8fiDs
gradSLAM: Dense SLAM meets Automatic Differentiation
Oct 23, 2019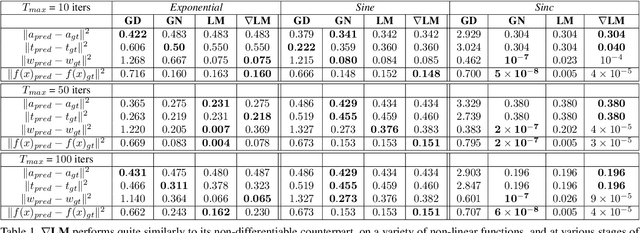
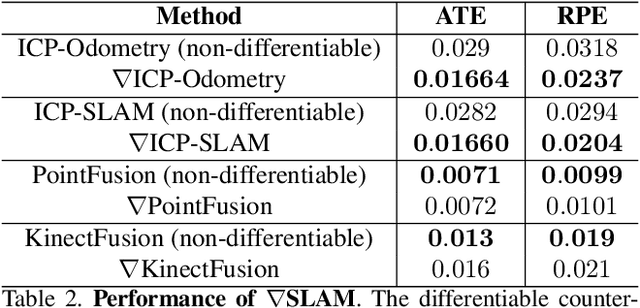
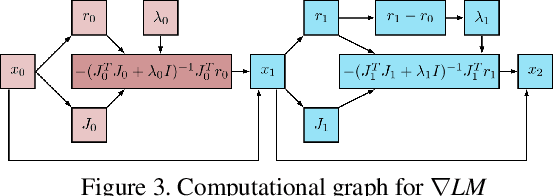
The question of "representation" is central in the context of dense simultaneous localization and mapping (SLAM). Newer learning-based approaches have the potential to leverage data or task performance to directly inform the choice of representation. However, learning representations for SLAM has been an open question, because traditional SLAM systems are not end-to-end differentiable. In this work, we present gradSLAM, a differentiable computational graph take on SLAM. Leveraging the automatic differentiation capabilities of computational graphs, gradSLAM enables the design of SLAM systems that allow for gradient-based learning across each of their components, or the system as a whole. This is achieved by creating differentiable alternatives for each non-differentiable component in a typical dense SLAM system. Specifically, we demonstrate how to design differentiable trust-region optimizers, surface measurement and fusion schemes, as well as differentiate over rays, without sacrificing performance. This amalgamation of dense SLAM with computational graphs enables us to backprop all the way from 3D maps to 2D pixels, opening up new possibilities in gradient-based learning for SLAM. TL;DR: We leverage the power of automatic differentiation frameworks to make dense SLAM differentiable.
Geometric Consistency for Self-Supervised End-to-End Visual Odometry
Apr 11, 2018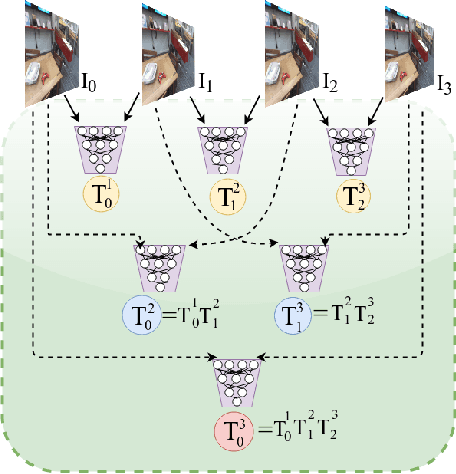
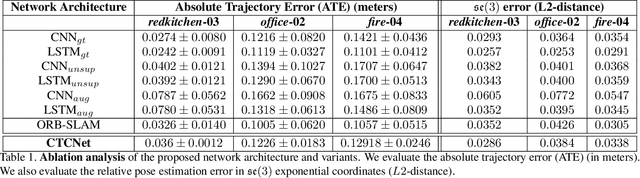
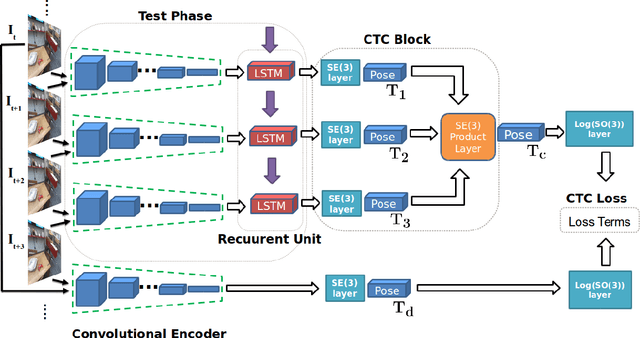
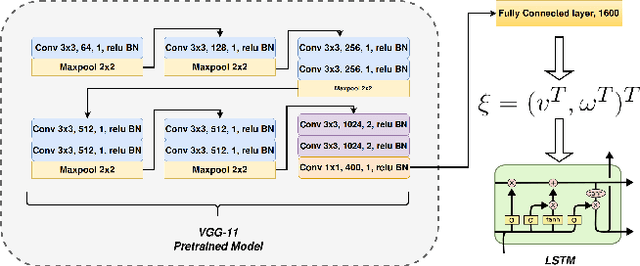
With the success of deep learning based approaches in tackling challenging problems in computer vision, a wide range of deep architectures have recently been proposed for the task of visual odometry (VO) estimation. Most of these proposed solutions rely on supervision, which requires the acquisition of precise ground-truth camera pose information, collected using expensive motion capture systems or high-precision IMU/GPS sensor rigs. In this work, we propose an unsupervised paradigm for deep visual odometry learning. We show that using a noisy teacher, which could be a standard VO pipeline, and by designing a loss term that enforces geometric consistency of the trajectory, we can train accurate deep models for VO that do not require ground-truth labels. We leverage geometry as a self-supervisory signal and propose "Composite Transformation Constraints (CTCs)", that automatically generate supervisory signals for training and enforce geometric consistency in the VO estimate. We also present a method of characterizing the uncertainty in VO estimates thus obtained. To evaluate our VO pipeline, we present exhaustive ablation studies that demonstrate the efficacy of end-to-end, self-supervised methodologies to train deep models for monocular VO. We show that leveraging concepts from geometry and incorporating them into the training of a recurrent neural network results in performance competitive to supervised deep VO methods.
CalibNet: Self-Supervised Extrinsic Calibration using 3D Spatial Transformer Networks
Mar 22, 2018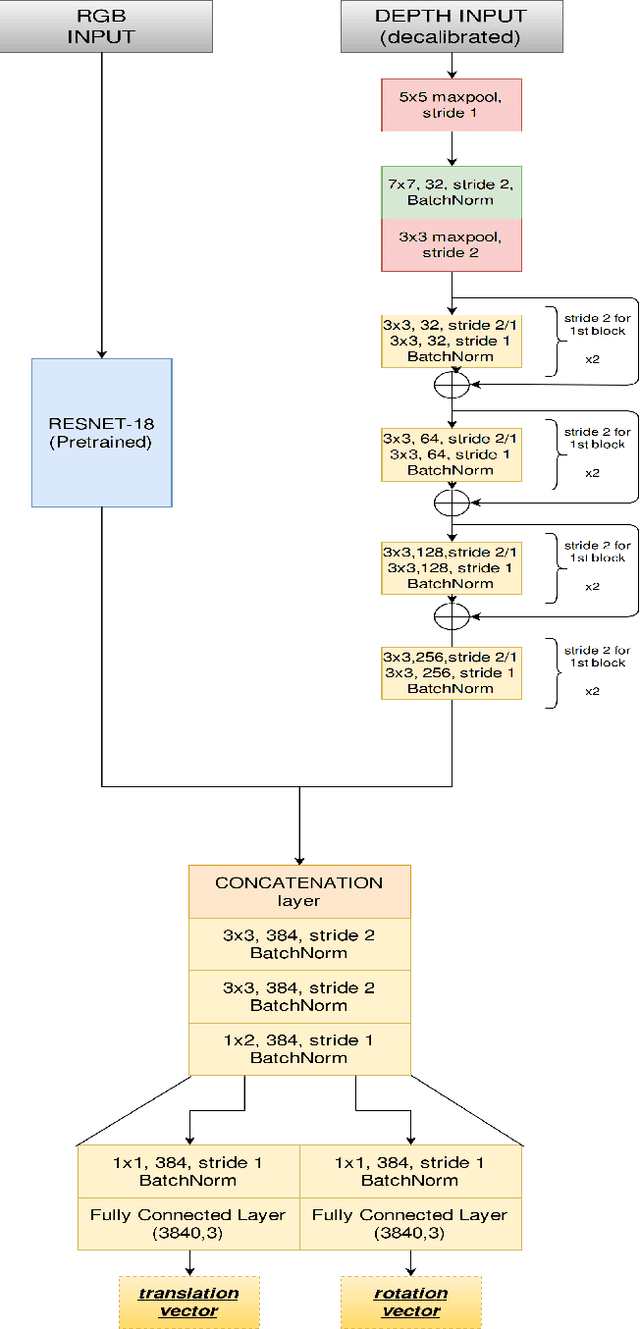

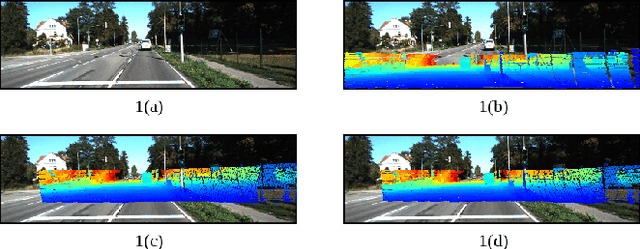
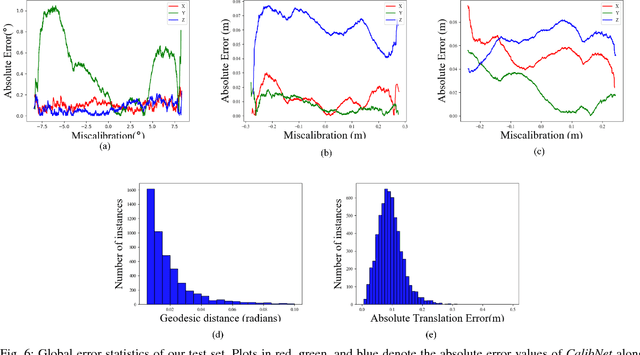
3D LiDARs and 2D cameras are increasingly being used alongside each other in sensor rigs for perception tasks. Before these sensors can be used to gather meaningful data, however, their extrinsics (and intrinsics) need to be accurately calibrated, as the performance of the sensor rig is extremely sensitive to these calibration parameters. A vast majority of existing calibration techniques require significant amounts of data and/or calibration targets and human effort, severely impacting their applicability in large-scale production systems. We address this gap with CalibNet: a self-supervised deep network capable of automatically estimating the 6-DoF rigid body transformation between a 3D LiDAR and a 2D camera in real-time. CalibNet alleviates the need for calibration targets, thereby resulting in significant savings in calibration efforts. During training, the network only takes as input a LiDAR point cloud, the corresponding monocular image, and the camera calibration matrix K. At train time, we do not impose direct supervision (i.e., we do not directly regress to the calibration parameters, for example). Instead, we train the network to predict calibration parameters that maximize the geometric and photometric consistency of the input images and point clouds. CalibNet learns to iteratively solve the underlying geometric problem and accurately predicts extrinsic calibration parameters for a wide range of mis-calibrations, without requiring retraining or domain adaptation. The project page is hosted at https://epiception.github.io/CalibNet