 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pixels: Leveraging Geometry and Shape Cues for Online Multi-Object Tracking
Jul 27, 2018
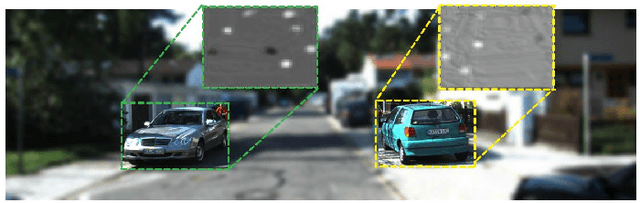
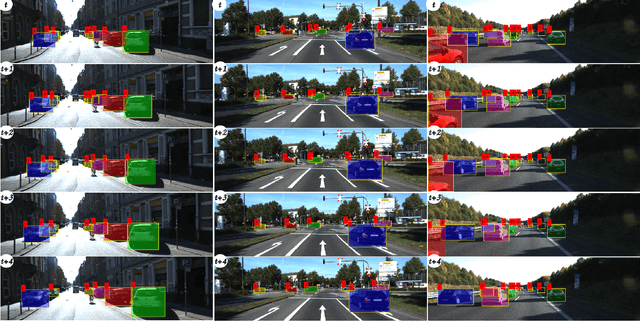

This paper introduces geometry and object shape and pose costs for multi-object tracking in urban driving scenarios. Using images from a monocular camera alone, we devise pairwise costs for object tracks, based on several 3D cues such as object pose, shape, and motion. The proposed costs are agnostic to the data association method and can be incorporated into any optimization framework to output the pairwise data associations. These costs are easy to implement, can be computed in real-time, and complement each other to account for possible errors in a tracking-by-detection framework. We perform an extensive analysis of the designed costs and empirically demonstrate consistent improvement over the state-of-the-art under varying conditions that employ a range of object detectors, exhibit a variety in camera and object motions, and, more importantly, are not reliant on the choice of the association framework. We also show that, by using the simplest of associations frameworks (two-frame Hungarian assignment), we surpass the state-of-the-art in multi-object-tracking on road scenes. More qualitative and quantitative results can be found at the following URL: https://junaidcs032.github.io/Geometry_ObjectShape_MOT/.
Geometric Consistency for Self-Supervised End-to-End Visual Odometry
Apr 11, 2018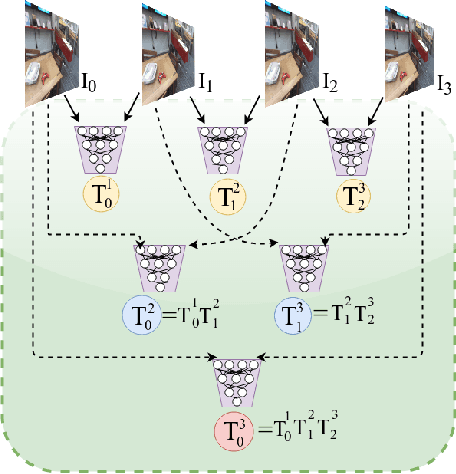
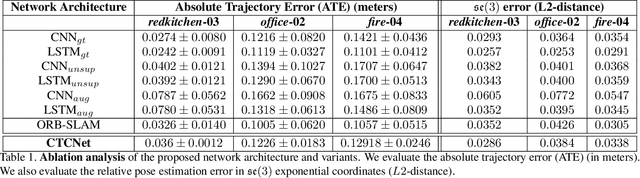
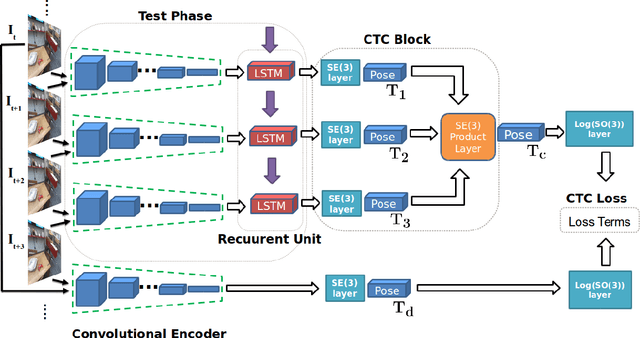
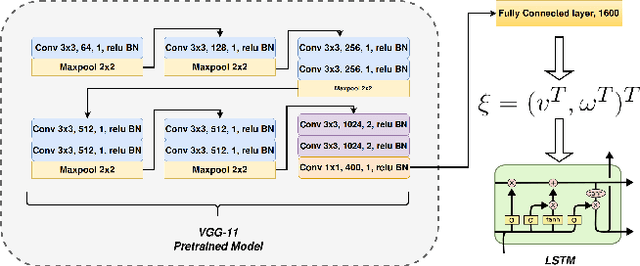
With the success of deep learning based approaches in tackling challenging problems in computer vision, a wide range of deep architectures have recently been proposed for the task of visual odometry (VO) estimation. Most of these proposed solutions rely on supervision, which requires the acquisition of precise ground-truth camera pose information, collected using expensive motion capture systems or high-precision IMU/GPS sensor rigs. In this work, we propose an unsupervised paradigm for deep visual odometry learning. We show that using a noisy teacher, which could be a standard VO pipeline, and by designing a loss term that enforces geometric consistency of the trajectory, we can train accurate deep models for VO that do not require ground-truth labels. We leverage geometry as a self-supervisory signal and propose "Composite Transformation Constraints (CTCs)", that automatically generate supervisory signals for training and enforce geometric consistency in the VO estimate. We also present a method of characterizing the uncertainty in VO estimates thus obtained. To evaluate our VO pipeline, we present exhaustive ablation studies that demonstrate the efficacy of end-to-end, self-supervised methodologies to train deep models for monocular VO. We show that leveraging concepts from geometry and incorporating them into the training of a recurrent neural network results in performance competitive to supervised deep VO methods.
CalibNet: Self-Supervised Extrinsic Calibration using 3D Spatial Transformer Networks
Mar 22, 2018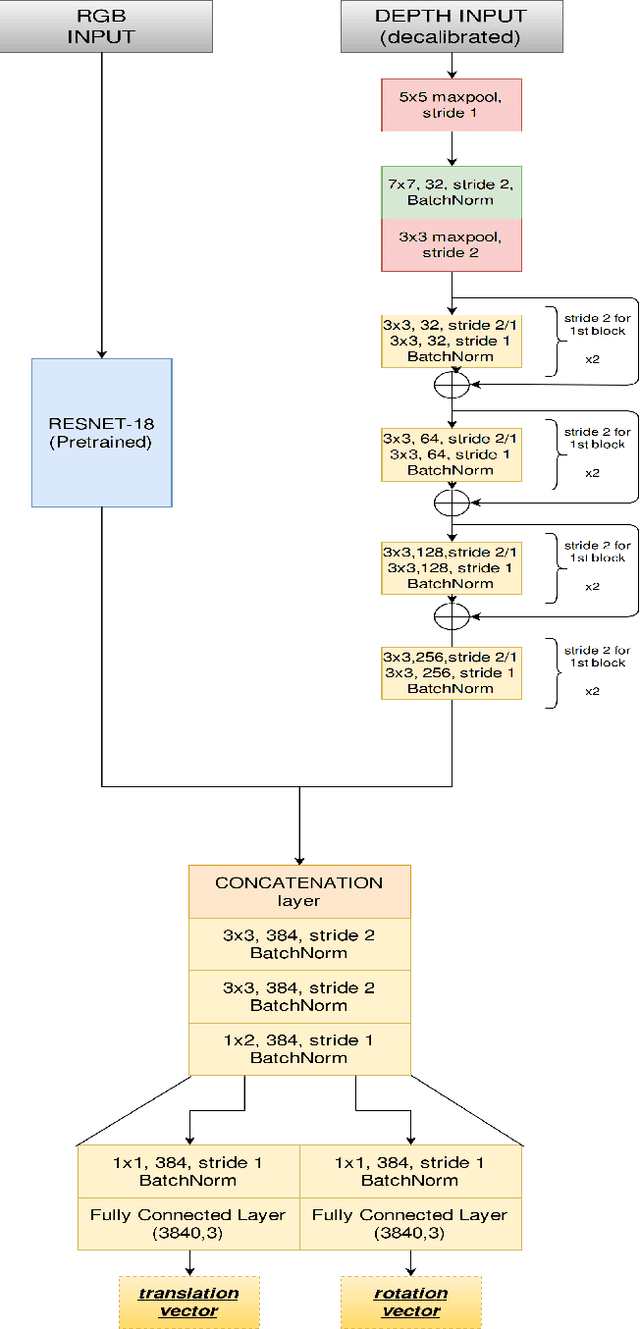

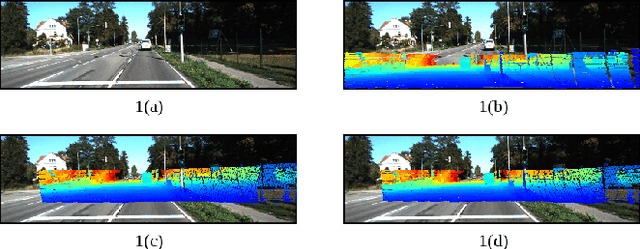
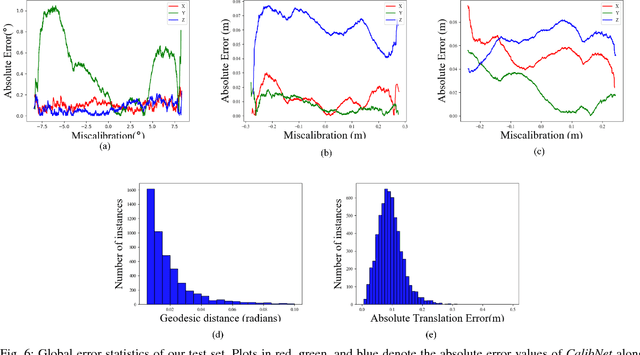
3D LiDARs and 2D cameras are increasingly being used alongside each other in sensor rigs for perception tasks. Before these sensors can be used to gather meaningful data, however, their extrinsics (and intrinsics) need to be accurately calibrated, as the performance of the sensor rig is extremely sensitive to these calibration parameters. A vast majority of existing calibration techniques require significant amounts of data and/or calibration targets and human effort, severely impacting their applicability in large-scale production systems. We address this gap with CalibNet: a self-supervised deep network capable of automatically estimating the 6-DoF rigid body transformation between a 3D LiDAR and a 2D camera in real-time. CalibNet alleviates the need for calibration targets, thereby resulting in significant savings in calibration efforts. During training, the network only takes as input a LiDAR point cloud, the corresponding monocular image, and the camera calibration matrix K. At train time, we do not impose direct supervision (i.e., we do not directly regress to the calibration parameters, for example). Instead, we train the network to predict calibration parameters that maximize the geometric and photometric consistency of the input images and point clouds. CalibNet learns to iteratively solve the underlying geometric problem and accurately predicts extrinsic calibration parameters for a wide range of mis-calibrations, without requiring retraining or domain adaptation. The project page is hosted at https://epiception.github.io/CalibNet
The Earth ain't Flat: Monocular Reconstruction of Vehicles on Steep and Graded Roads from a Moving Camera
Mar 06, 2018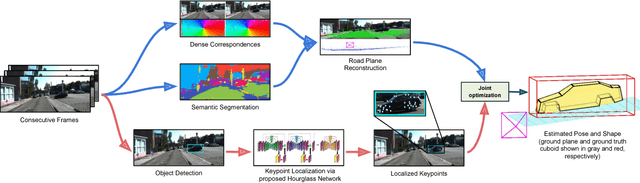
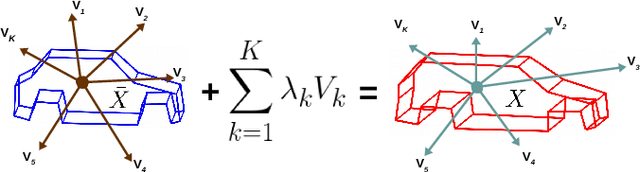

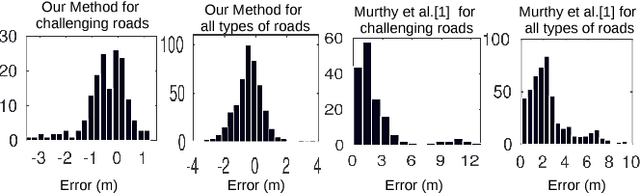
Accurate localization of other traffic participants is a vital task in autonomous driving systems. State-of-the-art systems employ a combination of sensing modalities such as RGB cameras and LiDARs for localizing traffic participants, but most such demonstrations have been confined to plain roads. We demonstrate, to the best of our knowledge, the first results for monocular object localization and shape estimation on surfaces that do not share the same plane with the moving monocular camera. We approximate road surfaces by local planar patches and use semantic cues from vehicles in the scene to initialize a local bundle-adjustment like procedure that simultaneously estimates the pose and shape of the vehicles, and the orientation of the local ground plane on which the vehicle stands as well. We evaluate the proposed approach on the KITTI and SYNTHIA-SF benchmarks, for a variety of road plane configurations. The proposed approach significantly improves the state-of-the-art for monocular object localization on arbitrarily-shaped roads.
Constructing Category-Specific Models for Monocular Object-SLAM
Feb 26, 2018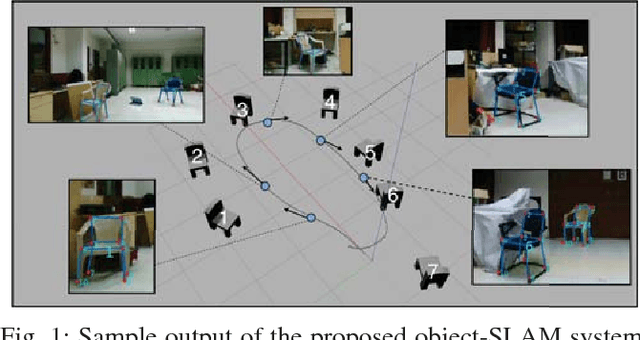
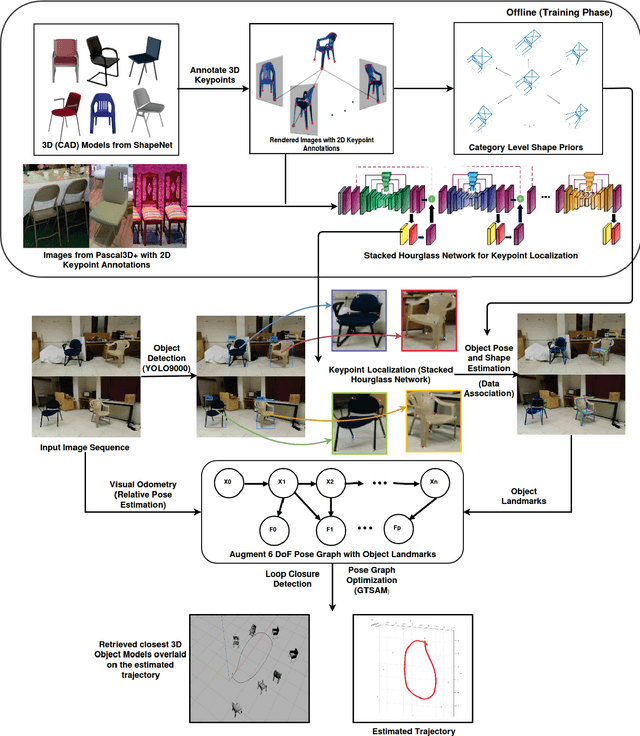

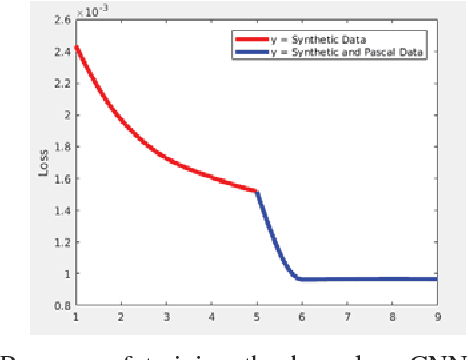
We present a new paradigm for real-time object-oriented SLAM with a monocular camera. Contrary to previous approaches, that rely on object-level models, we construct category-level models from CAD collections which are now widely available. To alleviate the need for huge amounts of labeled data, we develop a rendering pipeline that enables synthesis of large datasets from a limited amount of manually labeled data. Using data thus synthesized, we learn category-level models for object deformations in 3D, as well as discriminative object features in 2D. These category models are instance-independent and aid in the design of object landmark observations that can be incorporated into a generic monocular SLAM framework. Where typical object-SLAM approaches usually solve only for object and camera poses, we also estimate object shape on-the-fly, allowing for a wide range of objects from the category to be present in the scene. Moreover, since our 2D object features are learned discriminatively, the proposed object-SLAM system succeeds in several scenarios where sparse feature-based monocular SLAM fails due to insufficient features or parallax. Also, the proposed category-models help in object instance retrieval, useful for Augmented Reality (AR) applications. We evaluate the proposed framework on multiple challenging real-world scenes and show --- to the best of our knowledge --- first results of an instance-independent monocular object-SLAM system and the benefits it enjoys over feature-based SLAM methods.
Reconstructing Vechicles from a Single Image: Shape Priors for Road Scene Understanding
Sep 29, 2016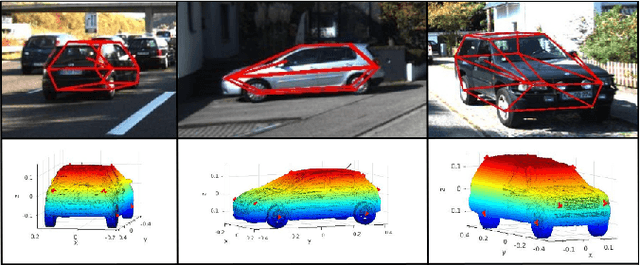

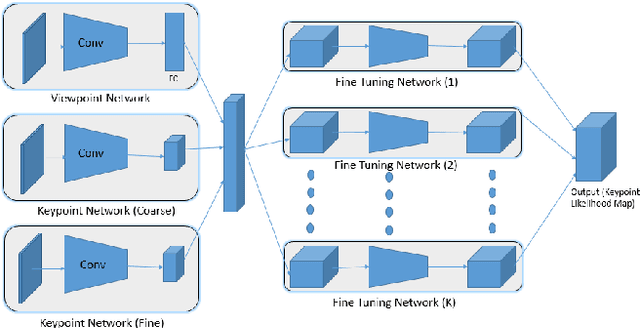

We present an approach for reconstructing vehicles from a single (RGB) image, in the context of autonomous driving. Though the problem appears to be ill-posed, we demonstrate that prior knowledge about how 3D shapes of vehicles project to an image can be used to reason about the reverse process, i.e., how shapes (back-)project from 2D to 3D. We encode this knowledge in \emph{shape priors}, which are learnt over a small keypoint-annotated dataset. We then formulate a shape-aware adjustment problem that uses the learnt shape priors to recover the 3D pose and shape of a query object from an image. For shape representation and inference, we leverage recent successes of Convolutional Neural Networks (CNNs) for the task of object and keypoint localization, and train a novel cascaded fully-convolutional architecture to localize vehicle \emph{keypoints} in images. The shape-aware adjustment then robustly recovers shape (3D locations of the detected keypoints) while simultaneously filling in occluded keypoints. To tackle estimation errors incurred due to erroneously detected keypoints, we use an Iteratively Re-weighted Least Squares (IRLS) scheme for robust optimization, and as a by-product characterize noise models for each predicted keypoint. We evaluate our approach on autonomous driving benchmarks, and present superior results to existing monocular, as well as stereo approaches.