 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
FindingDory: A Benchmark to Evaluate Memory in Embodied Agents
Jun 18, 2025Large vision-language models have recently demonstrated impressive performance in planning and control tasks, driving interest in their application to real-world robotics. However, deploying these models for reasoning in embodied contexts is limited by their ability to incorporate long-term experience collected across multiple days and represented by vast collections of images. Current VLMs typically struggle to process more than a few hundred images concurrently, highlighting the need for more efficient mechanisms to handle long-term memory in embodied settings. To effectively evaluate these models for long-horizon control, a benchmark must specifically target scenarios where memory is crucial for success. Existing long-video QA benchmarks overlook embodied challenges like object manipulation and navigation, which demand low-level skills and fine-grained reasoning over past interactions. Moreover, effective memory integration in embodied agents involves both recalling relevant historical information and executing actions based on that information, making it essential to study these aspects together rather than in isolation. In this work, we introduce a new benchmark for long-range embodied tasks in the Habitat simulator. This benchmark evaluates memory-based capabilities across 60 tasks requiring sustained engagement and contextual awareness in an environment. The tasks can also be procedurally extended to longer and more challenging versions, enabling scalable evaluation of memory and reasoning. We also present baselines that integrate state-of-the-art VLMs with low level navigation policies, assessing their performance on these memory-intensive tasks and highlight areas for improvement.
Pre-trained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control
May 09, 2024



Embodied AI agents require a fine-grained understanding of the physical world mediated through visual and language inputs. Such capabilities are difficult to learn solely from task-specific data. This has led to the emergence of pre-trained vision-language models as a tool for transferring representations learned from internet-scale data to downstream tasks and new domains. However, commonly used contrastively trained representations such as in CLIP have been shown to fail at enabling embodied agents to gain a sufficiently fine-grained scene understanding -- a capability vital for control. To address this shortcoming, we consider representations from pre-trained text-to-image diffusion models, which are explicitly optimized to generate images from text prompts and as such, contain text-conditioned representations that reflect highly fine-grained visuo-spatial information. Using pre-trained text-to-image diffusion models, we construct Stable Control Representations which allow learning downstream control policies that generalize to complex, open-ended environments. We show that policies learned using Stable Control Representations are competitive with state-of-the-art representation learning approaches across a broad range of simulated control settings, encompassing challenging manipulation and navigation tasks. Most notably, we show that Stable Control Representations enable learning policies that exhibit state-of-the-art performance on OVMM, a difficult open-vocabulary navigation benchmark.
Can Active Sampling Reduce Causal Confusion in Offline Reinforcement Learning?
Dec 28, 2023Causal confusion is a phenomenon where an agent learns a policy that reflects imperfect spurious correlations in the data. Such a policy may falsely appear to be optimal during training if most of the training data contain such spurious correlations. This phenomenon is particularly pronounced in domains such as robotics, with potentially large gaps between the open- and closed-loop performance of an agent. In such settings, causally confused models may appear to perform well according to open-loop metrics during training but fail catastrophically when deployed in the real world. In this paper, we study causal confusion in offline reinforcement learning. We investigate whether selectively sampling appropriate points from a dataset of demonstrations may enable offline reinforcement learning agents to disambiguate the underlying causal mechanisms of the environment, alleviate causal confusion in offline reinforcement learning, and produce a safer model for deployment. To answer this question, we consider a set of tailored offline reinforcement learning datasets that exhibit causal ambiguity and assess the ability of active sampling techniques to reduce causal confusion at evaluation. We provide empirical evidence that uniform and active sampling techniques are able to consistently reduce causal confusion as training progresses and that active sampling is able to do so significantly more efficiently than uniform sampling.
ReLU to the Rescue: Improve Your On-Policy Actor-Critic with Positive Advantages
Jun 12, 2023



This paper introduces a novel method for enhancing the effectiveness of on-policy Deep Reinforcement Learning (DRL) algorithms. Three surprisingly simple modifications to the A3C algorithm: (1) processing advantage estimates through a ReLU function, (2) spectral normalization, and (3) dropout, serve to not only improve efficacy but also yield a ``cautious'' DRL algorithm. Where on-policy algorithms such as Proximal Policy Optimization (PPO) and Asynchronous Advantage Actor-Critic (A3C) do not explicitly account for cautious interaction with the environment, our method integrates caution in two critical ways: (1) by maximizing a lower bound on the value function plus a constant, thereby promoting a \textit{conservative value estimation}, and (2) by incorporating Thompson sampling for cautious exploration. In proving that our algorithm maximizes the lower bound, we also ground Regret Matching Policy Gradients (RMPG), a discrete-action on-policy method for multi-agent reinforcement learning. Our rigorous empirical evaluations across various benchmarks demonstrate our approach's improved performance against existing on-policy algorithms. This research represents a substantial step towards efficacious and cautious DRL algorithms, which are needed to unlock applications to complex, real-world problems.
La-MAML: Look-ahead Meta Learning for Continual Learning
Jul 27, 2020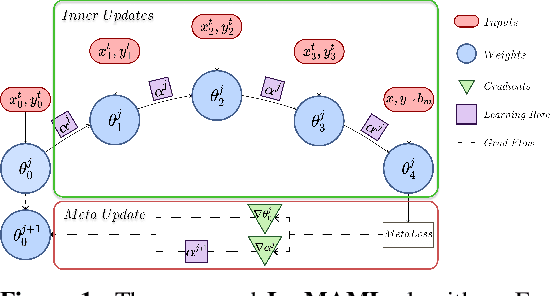
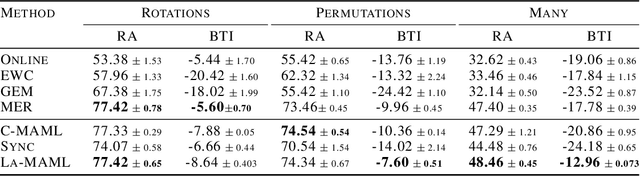


The continual learning problem involves training models with limited capacity to perform well on a set of an unknown number of sequentially arriving tasks. While meta-learning shows great potential for reducing interference between old and new tasks, the current training procedures tend to be either slow or offline, and sensitive to many hyper-parameters. In this work, we propose Look-ahead MAML (La-MAML), a fast optimisation-based meta-learning algorithm for online-continual learning, aided by a small episodic memory. Our proposed modulation of per-parameter learning rates in our meta-learning update allows us to draw connections to prior work on hypergradients and meta-descent. This provides a more flexible and efficient way to mitigate catastrophic forgetting compared to conventional prior-based methods. La-MAML achieves performance superior to other replay-based, prior-based and meta-learning based approaches for continual learning on real-world visual classification benchmarks.
Unifying Variational Inference and PAC-Bayes for Supervised Learning that Scales
Oct 23, 2019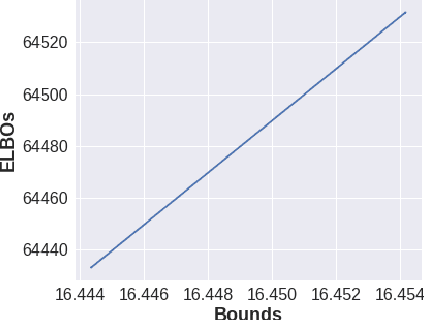
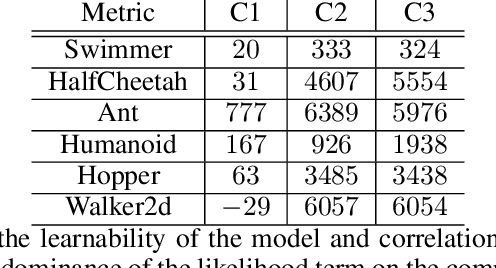
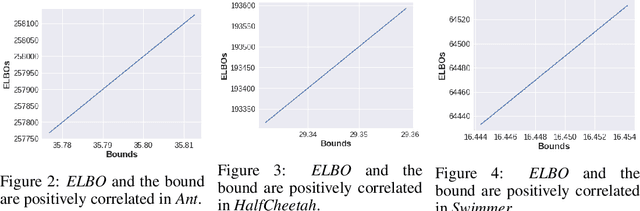
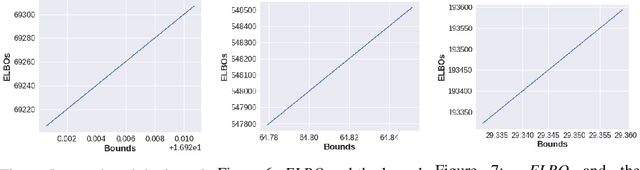
Neural Network based controllers hold enormous potential to learn complex, high-dimensional functions. However, they are prone to overfitting and unwarranted extrapolations. PAC Bayes is a generalized framework which is more resistant to overfitting and that yields performance bounds that hold with arbitrarily high probability even on the unjustified extrapolations. However, optimizing to learn such a function and a bound is intractable for complex tasks. In this work, we propose a method to simultaneously learn such a function and estimate performance bounds that scale organically to high-dimensions, non-linear environments without making any explicit assumptions about the environment. We build our approach on a parallel that we draw between the formulations called ELBO and PAC Bayes when the risk metric is negative log likelihood. Through our experiments on multiple high dimensional MuJoCo locomotion tasks, we validate the correctness of our theory, show its ability to generalize better, and investigate the factors that are important for its learning. The code for all the experiments is available at https://bit.ly/2qv0JjA.
Geometric Consistency for Self-Supervised End-to-End Visual Odometry
Apr 11, 2018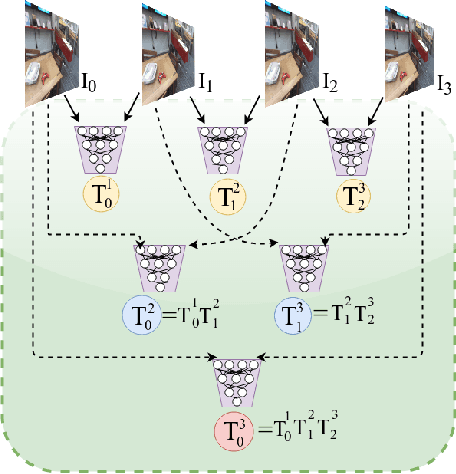
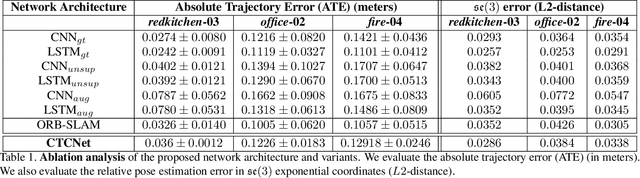
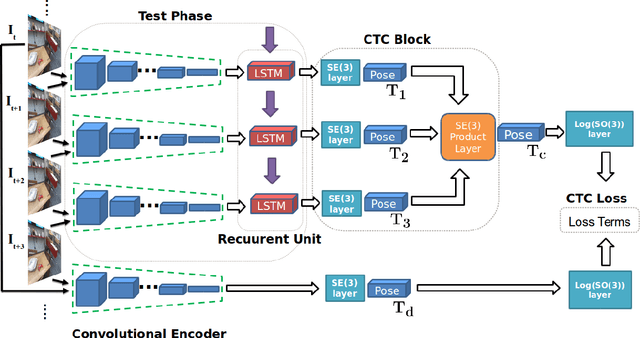
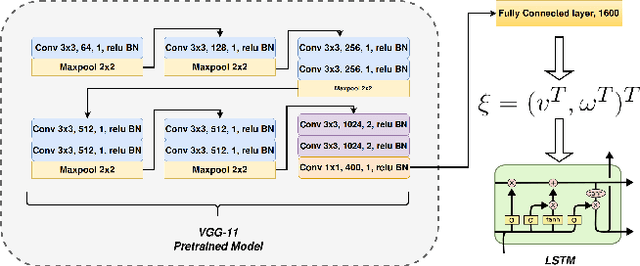
With the success of deep learning based approaches in tackling challenging problems in computer vision, a wide range of deep architectures have recently been proposed for the task of visual odometry (VO) estimation. Most of these proposed solutions rely on supervision, which requires the acquisition of precise ground-truth camera pose information, collected using expensive motion capture systems or high-precision IMU/GPS sensor rigs. In this work, we propose an unsupervised paradigm for deep visual odometry learning. We show that using a noisy teacher, which could be a standard VO pipeline, and by designing a loss term that enforces geometric consistency of the trajectory, we can train accurate deep models for VO that do not require ground-truth labels. We leverage geometry as a self-supervisory signal and propose "Composite Transformation Constraints (CTCs)", that automatically generate supervisory signals for training and enforce geometric consistency in the VO estimate. We also present a method of characterizing the uncertainty in VO estimates thus obtained. To evaluate our VO pipeline, we present exhaustive ablation studies that demonstrate the efficacy of end-to-end, self-supervised methodologies to train deep models for monocular VO. We show that leveraging concepts from geometry and incorporating them into the training of a recurrent neural network results in performance competitive to supervised deep VO methods.