 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Continuous-Time Markov Chain Framework for Insertion Language Models
Jun 08, 2026Insertion Language Models (ILMs) offer several advantages over left-to-right generation and mask-based generation. However, existing formulations of insertion-based generation have largely been ad-hoc. In this paper, we derive a diffusion-style denoising objective for ILMs from first principles by formulating the noising process as a continuous-time Markov chain on the space of variable-length sequences. We show that previous formulations of ILMs can be viewed as special cases of this denoising framework. Through empirical evaluation on a synthetic planning task, we show that the proposed approach retains the benefits of insertion-based generation over left-to-right generation and masked diffusion models. In language modeling, our diffusion-based approach is competitive with left-to-right generation and masked diffusion models, while offering additional flexibility in sampling compared to existing insertion language models.
Learned Relay Representations for Forward-Thinking Discrete Diffusion Models
May 21, 2026When Masked Diffusion Models (MDMs) generate sequences through iterative refinement, the rich internal computation over masked positions is discarded, forcing every subsequent refinement step to recompute the valuable internal information stored as model representations. To avoid a hard reset between denoising rounds, we propose Learned Relay Representations (Relay), a method that allows MDMs to be forward-thinking when denoising by explicitly learning how to propagate latent information for the benefit of future denoising steps. Relay introduces a differentiable per-token channel that passes information between forward passes and is trained via truncated backpropagation through time (BPTT). We show that this framework can be scaled to state-of-the-art Diffusion Language Models (DLMs), and is seamlessly compatible with techniques like block diffusion and KV caching. We first provide a thorough justification of the design choices in Relay on a challenging Sudoku-based planning task. We then scale Relay to Fast-dLLM v2, a state-of-the-art DLM, outperforming standard supervised finetuning on coding tasks while reducing inference latency by up to 32%. Our empirical results demonstrate that state-of-the-art DLMs can be explicitly trained to relay latent information forward across decoding steps, advancing the performance-latency Pareto frontier. We provide code for all our experiments.
Temporal Straightening for Latent Planning
Mar 12, 2026Learning good representations is essential for latent planning with world models. While pretrained visual encoders produce strong semantic visual features, they are not tailored to planning and contain information irrelevant -- or even detrimental -- to planning. Inspired by the perceptual straightening hypothesis in human visual processing, we introduce temporal straightening to improve representation learning for latent planning. Using a curvature regularizer that encourages locally straightened latent trajectories, we jointly learn an encoder and a predictor. We show that reducing curvature this way makes the Euclidean distance in latent space a better proxy for the geodesic distance and improves the conditioning of the planning objective. We demonstrate empirically that temporal straightening makes gradient-based planning more stable and yields significantly higher success rates across a suite of goal-reaching tasks.
Data-Driven Priors for Uncertainty-Aware Deterioration Risk Prediction with Multimodal Data
Mar 09, 2026Safe predictions are a crucial requirement for integrating predictive models into clinical decision support systems. One approach for ensuring trustworthiness is to enable models' ability to express their uncertainty about individual predictions. However, current machine learning models frequently lack reliable uncertainty estimation, hindering real-world deployment. This is further observed in multimodal settings, where the goal is to enable effective information fusion. In this work, we propose $\texttt{MedCertAIn}$, a predictive uncertainty framework that leverages multimodal clinical data for in-hospital risk prediction to improve model performance and reliability. We design data-driven priors over neural network parameters using a hybrid strategy that considers cross-modal similarity in self-supervised latent representations and modality-specific data corruptions. We train and evaluate the models with such priors using clinical time-series and chest X-ray images from the publicly-available datasets MIMIC-IV and MIMIC-CXR. Our results show that $\texttt{MedCertAIn}$ significantly improves predictive performance and uncertainty quantification compared to state-of-the-art deterministic baselines and alternative Bayesian methods. These findings highlight the promise of data-driven priors in advancing robust, uncertainty-aware AI tools for high-stakes clinical applications.
An Empirical Analysis of Calibration and Selective Prediction in Multimodal Clinical Condition Classification
Mar 03, 2026As artificial intelligence systems move toward clinical deployment, ensuring reliable prediction behavior is fundamental for safety-critical decision-making tasks. One proposed safeguard is selective prediction, where models can defer uncertain predictions to human experts for review. In this work, we empirically evaluate the reliability of uncertainty-based selective prediction in multilabel clinical condition classification using multimodal ICU data. Across a range of state-of-the-art unimodal and multimodal models, we find that selective prediction can substantially degrade performance despite strong standard evaluation metrics. This failure is driven by severe class-dependent miscalibration, whereby models assign high uncertainty to correct predictions and low uncertainty to incorrect ones, particularly for underrepresented clinical conditions. Our results show that commonly used aggregate metrics can obscure these effects, limiting their ability to assess selective prediction behavior in this setting. Taken together, our findings characterize a task-specific failure mode of selective prediction in multimodal clinical condition classification and highlight the need for calibration-aware evaluation to provide strong guarantees of safety and robustness in clinical AI.
Radial-VCReg: More Informative Representation Learning Through Radial Gaussianization
Feb 15, 2026Self-supervised learning aims to learn maximally informative representations, but explicit information maximization is hindered by the curse of dimensionality. Existing methods like VCReg address this by regularizing first and second-order feature statistics, which cannot fully achieve maximum entropy. We propose Radial-VCReg, which augments VCReg with a radial Gaussianization loss that aligns feature norms with the Chi distribution-a defining property of high-dimensional Gaussians. We prove that Radial-VCReg transforms a broader class of distributions towards normality compared to VCReg and show on synthetic and real-world datasets that it consistently improves performance by reducing higher-order dependencies and promoting more diverse and informative representations.
Rectified LpJEPA: Joint-Embedding Predictive Architectures with Sparse and Maximum-Entropy Representations
Feb 01, 2026Joint-Embedding Predictive Architectures (JEPA) learn view-invariant representations and admit projection-based distribution matching for collapse prevention. Existing approaches regularize representations towards isotropic Gaussian distributions, but inherently favor dense representations and fail to capture the key property of sparsity observed in efficient representations. We introduce Rectified Distribution Matching Regularization (RDMReg), a sliced two-sample distribution-matching loss that aligns representations to a Rectified Generalized Gaussian (RGG) distribution. RGG enables explicit control over expected $\ell_0$ norm through rectification, while preserving maximum-entropy up to rescaling under expected $\ell_p$ norm constraints. Equipping JEPAs with RDMReg yields Rectified LpJEPA, which strictly generalizes prior Gaussian-based JEPAs. Empirically, Rectified LpJEPA learns sparse, non-negative representations with favorable sparsity-performance trade-offs and competitive downstream performance on image classification benchmarks, demonstrating that RDMReg effectively enforces sparsity while preserving task-relevant information.
Out-of-Distribution Detection Methods Answer the Wrong Questions
Jul 02, 2025To detect distribution shifts and improve model safety, many out-of-distribution (OOD) detection methods rely on the predictive uncertainty or features of supervised models trained on in-distribution data. In this paper, we critically re-examine this popular family of OOD detection procedures, and we argue that these methods are fundamentally answering the wrong questions for OOD detection. There is no simple fix to this misalignment, since a classifier trained only on in-distribution classes cannot be expected to identify OOD points; for instance, a cat-dog classifier may confidently misclassify an airplane if it contains features that distinguish cats from dogs, despite generally appearing nothing alike. We find that uncertainty-based methods incorrectly conflate high uncertainty with being OOD, while feature-based methods incorrectly conflate far feature-space distance with being OOD. We show how these pathologies manifest as irreducible errors in OOD detection and identify common settings where these methods are ineffective. Additionally, interventions to improve OOD detection such as feature-logit hybrid methods, scaling of model and data size, epistemic uncertainty representation, and outlier exposure also fail to address this fundamental misalignment in objectives. We additionally consider unsupervised density estimation and generative models for OOD detection, which we show have their own fundamental limitations.
MetaFaith: Faithful Natural Language Uncertainty Expression in LLMs
May 30, 2025A critical component in the trustworthiness of LLMs is reliable uncertainty communication, yet LLMs often use assertive language when conveying false claims, leading to over-reliance and eroded trust. We present the first systematic study of $\textit{faithful confidence calibration}$ of LLMs, benchmarking models' ability to use linguistic expressions of uncertainty that $\textit{faithfully reflect}$ their intrinsic uncertainty, across a comprehensive array of models, datasets, and prompting strategies. Our results demonstrate that LLMs largely fail at this task, and that existing interventions are insufficient: standard prompt approaches provide only marginal gains, and existing, factuality-based calibration techniques can even harm faithful calibration. To address this critical gap, we introduce MetaFaith, a novel prompt-based calibration approach inspired by human metacognition. We show that MetaFaith robustly improves faithful calibration across diverse models and task domains, enabling up to 61% improvement in faithfulness and achieving an 83% win rate over original generations as judged by humans.
Insertion Language Models: Sequence Generation with Arbitrary-Position Insertions
May 09, 2025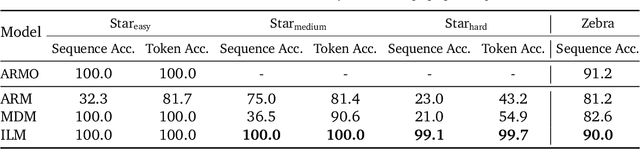



Autoregressive models (ARMs), which predict subsequent tokens one-by-one ``from left to right,'' have achieved significant success across a wide range of sequence generation tasks. However, they struggle to accurately represent sequences that require satisfying sophisticated constraints or whose sequential dependencies are better addressed by out-of-order generation. Masked Diffusion Models (MDMs) address some of these limitations, but the process of unmasking multiple tokens simultaneously in MDMs can introduce incoherences, and MDMs cannot handle arbitrary infilling constraints when the number of tokens to be filled in is not known in advance. In this work, we introduce Insertion Language Models (ILMs), which learn to insert tokens at arbitrary positions in a sequence -- that is, they select jointly both the position and the vocabulary element to be inserted. By inserting tokens one at a time, ILMs can represent strong dependencies between tokens, and their ability to generate sequences in arbitrary order allows them to accurately model sequences where token dependencies do not follow a left-to-right sequential structure. To train ILMs, we propose a tailored network parameterization and use a simple denoising objective. Our empirical evaluation demonstrates that ILMs outperform both ARMs and MDMs on common planning tasks. Furthermore, we show that ILMs outperform MDMs and perform on par with ARMs in an unconditional text generation task while offering greater flexibility than MDMs in arbitrary-length text infilling.