 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Continuous-Time Markov Chain Framework for Insertion Language Models
Jun 08, 2026Insertion Language Models (ILMs) offer several advantages over left-to-right generation and mask-based generation. However, existing formulations of insertion-based generation have largely been ad-hoc. In this paper, we derive a diffusion-style denoising objective for ILMs from first principles by formulating the noising process as a continuous-time Markov chain on the space of variable-length sequences. We show that previous formulations of ILMs can be viewed as special cases of this denoising framework. Through empirical evaluation on a synthetic planning task, we show that the proposed approach retains the benefits of insertion-based generation over left-to-right generation and masked diffusion models. In language modeling, our diffusion-based approach is competitive with left-to-right generation and masked diffusion models, while offering additional flexibility in sampling compared to existing insertion language models.
Learned Relay Representations for Forward-Thinking Discrete Diffusion Models
May 21, 2026When Masked Diffusion Models (MDMs) generate sequences through iterative refinement, the rich internal computation over masked positions is discarded, forcing every subsequent refinement step to recompute the valuable internal information stored as model representations. To avoid a hard reset between denoising rounds, we propose Learned Relay Representations (Relay), a method that allows MDMs to be forward-thinking when denoising by explicitly learning how to propagate latent information for the benefit of future denoising steps. Relay introduces a differentiable per-token channel that passes information between forward passes and is trained via truncated backpropagation through time (BPTT). We show that this framework can be scaled to state-of-the-art Diffusion Language Models (DLMs), and is seamlessly compatible with techniques like block diffusion and KV caching. We first provide a thorough justification of the design choices in Relay on a challenging Sudoku-based planning task. We then scale Relay to Fast-dLLM v2, a state-of-the-art DLM, outperforming standard supervised finetuning on coding tasks while reducing inference latency by up to 32%. Our empirical results demonstrate that state-of-the-art DLMs can be explicitly trained to relay latent information forward across decoding steps, advancing the performance-latency Pareto frontier. We provide code for all our experiments.
XLM: A Python package for non-autoregressive language models
Dec 18, 2025In recent years, there has been a resurgence of interest in non-autoregressive text generation in the context of general language modeling. Unlike the well-established autoregressive language modeling paradigm, which has a plethora of standard training and inference libraries, implementations of non-autoregressive language modeling have largely been bespoke making it difficult to perform systematic comparisons of different methods. Moreover, each non-autoregressive language model typically requires it own data collation, loss, and prediction logic, making it challenging to reuse common components. In this work, we present the XLM python package, which is designed to make implementing small non-autoregressive language models faster with a secondary goal of providing a suite of small pre-trained models (through a companion xlm-models package) that can be used by the research community. The code is available at https://github.com/dhruvdcoder/xlm-core.
Insertion Language Models: Sequence Generation with Arbitrary-Position Insertions
May 09, 2025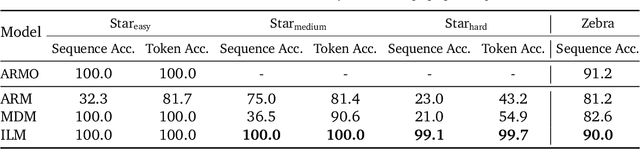



Autoregressive models (ARMs), which predict subsequent tokens one-by-one ``from left to right,'' have achieved significant success across a wide range of sequence generation tasks. However, they struggle to accurately represent sequences that require satisfying sophisticated constraints or whose sequential dependencies are better addressed by out-of-order generation. Masked Diffusion Models (MDMs) address some of these limitations, but the process of unmasking multiple tokens simultaneously in MDMs can introduce incoherences, and MDMs cannot handle arbitrary infilling constraints when the number of tokens to be filled in is not known in advance. In this work, we introduce Insertion Language Models (ILMs), which learn to insert tokens at arbitrary positions in a sequence -- that is, they select jointly both the position and the vocabulary element to be inserted. By inserting tokens one at a time, ILMs can represent strong dependencies between tokens, and their ability to generate sequences in arbitrary order allows them to accurately model sequences where token dependencies do not follow a left-to-right sequential structure. To train ILMs, we propose a tailored network parameterization and use a simple denoising objective. Our empirical evaluation demonstrates that ILMs outperform both ARMs and MDMs on common planning tasks. Furthermore, we show that ILMs outperform MDMs and perform on par with ARMs in an unconditional text generation task while offering greater flexibility than MDMs in arbitrary-length text infilling.
Language Guided Exploration for RL Agents in Text Environments
Mar 05, 2024Real-world sequential decision making is characterized by sparse rewards and large decision spaces, posing significant difficulty for experiential learning systems like $\textit{tabula rasa}$ reinforcement learning (RL) agents. Large Language Models (LLMs), with a wealth of world knowledge, can help RL agents learn quickly and adapt to distribution shifts. In this work, we introduce Language Guided Exploration (LGE) framework, which uses a pre-trained language model (called GUIDE ) to provide decision-level guidance to an RL agent (called EXPLORER). We observe that on ScienceWorld (Wang et al.,2022), a challenging text environment, LGE outperforms vanilla RL agents significantly and also outperforms other sophisticated methods like Behaviour Cloning and Text Decision Transformer.
Pretrained Language Models as Visual Planners for Human Assistance
Apr 27, 2023To make progress towards multi-modal AI assistants which can guide users to achieve complex multi-step goals, we propose the task of Visual Planning for Assistance (VPA). Given a goal briefly described in natural language, e.g., "make a shelf", and a video of the user's progress so far, the aim of VPA is to obtain a plan, i.e., a sequence of actions such as "sand shelf", "paint shelf", etc., to achieve the goal. This requires assessing the user's progress from the untrimmed video, and relating it to the requirements of underlying goal, i.e., relevance of actions and ordering dependencies amongst them. Consequently, this requires handling long video history, and arbitrarily complex action dependencies. To address these challenges, we decompose VPA into video action segmentation and forecasting. We formulate the forecasting step as a multi-modal sequence modeling problem and present Visual Language Model based Planner (VLaMP), which leverages pre-trained LMs as the sequence model. We demonstrate that VLaMP performs significantly better than baselines w.r.t all metrics that evaluate the generated plan. Moreover, through extensive ablations, we also isolate the value of language pre-training, visual observations, and goal information on the performance. We will release our data, model, and code to enable future research on visual planning for assistance.
Box Embeddings: An open-source library for representation learning using geometric structures
Sep 10, 2021
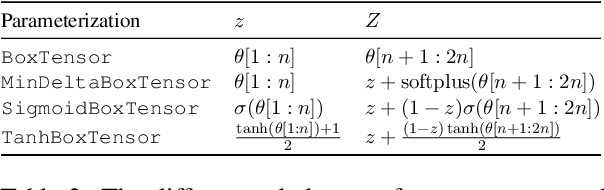
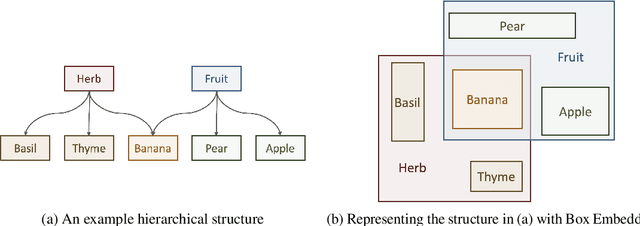
A major factor contributing to the success of modern representation learning is the ease of performing various vector operations. Recently, objects with geometric structures (eg. distributions, complex or hyperbolic vectors, or regions such as cones, disks, or boxes) have been explored for their alternative inductive biases and additional representational capacities. In this work, we introduce Box Embeddings, a Python library that enables researchers to easily apply and extend probabilistic box embeddings.
Word2Box: Learning Word Representation Using Box Embeddings
Jun 28, 2021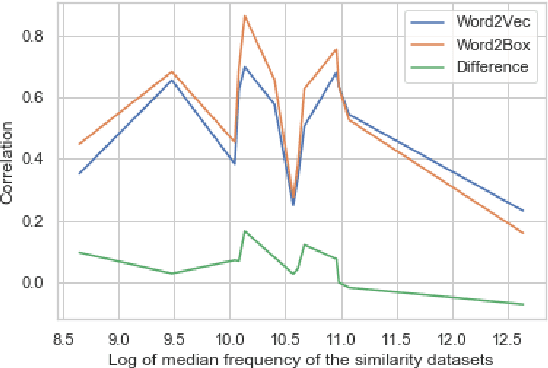



Learning vector representations for words is one of the most fundamental topics in NLP, capable of capturing syntactic and semantic relationships useful in a variety of downstream NLP tasks. Vector representations can be limiting, however, in that typical scoring such as dot product similarity intertwines position and magnitude of the vector in space. Exciting innovations in the space of representation learning have proposed alternative fundamental representations, such as distributions, hyperbolic vectors, or regions. Our model, Word2Box, takes a region-based approach to the problem of word representation, representing words as $n$-dimensional rectangles. These representations encode position and breadth independently and provide additional geometric operations such as intersection and containment which allow them to model co-occurrence patterns vectors struggle with. We demonstrate improved performance on various word similarity tasks, particularly on less common words, and perform a qualitative analysis exploring the additional unique expressivity provided by Word2Box.
Weakly Supervised Medication Regimen Extraction from Medical Conversations
Oct 11, 2020
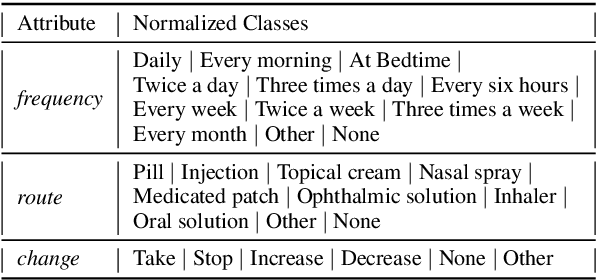

Automated Medication Regimen (MR) extraction from medical conversations can not only improve recall and help patients follow through with their care plan, but also reduce the documentation burden for doctors. In this paper, we focus on extracting spans for frequency, route and change, corresponding to medications discussed in the conversation. We first describe a unique dataset of annotated doctor-patient conversations and then present a weakly supervised model architecture that can perform span extraction using noisy classification data. The model utilizes an attention bottleneck inside a classification model to perform the extraction. We experiment with several variants of attention scoring and projection functions and propose a novel transformer-based attention scoring function (TAScore). The proposed combination of TAScore and Fusedmax projection achieves a 10 point increase in Longest Common Substring F1 compared to the baseline of additive scoring plus softmax projection.
Reading Comprehension as Natural Language Inference: A Semantic Analysis
Oct 04, 2020
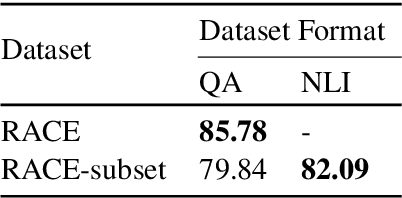
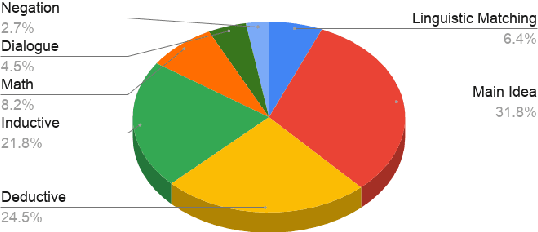
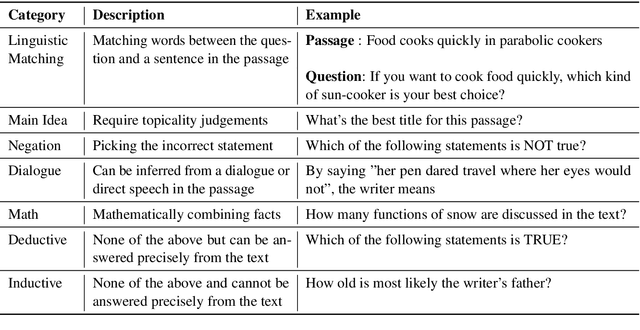
In the recent past, Natural language Inference (NLI) has gained significant attention, particularly given its promise for downstream NLP tasks. However, its true impact is limited and has not been well studied. Therefore, in this paper, we explore the utility of NLI for one of the most prominent downstream tasks, viz. Question Answering (QA). We transform the one of the largest available MRC dataset (RACE) to an NLI form, and compare the performances of a state-of-the-art model (RoBERTa) on both these forms. We propose new characterizations of questions, and evaluate the performance of QA and NLI models on these categories. We highlight clear categories for which the model is able to perform better when the data is presented in a coherent entailment form, and a structured question-answer concatenation form, respectively.