 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWearable Accelerometer Foundation Models for Health via Knowledge Distillation
Dec 15, 2024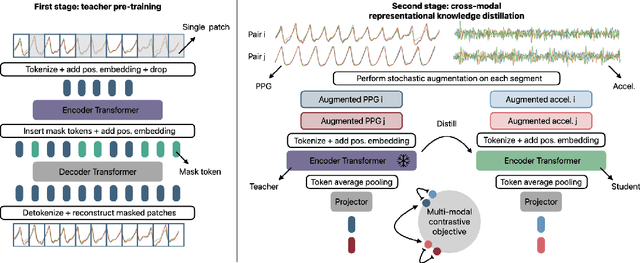

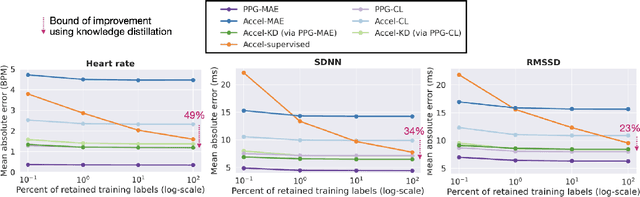
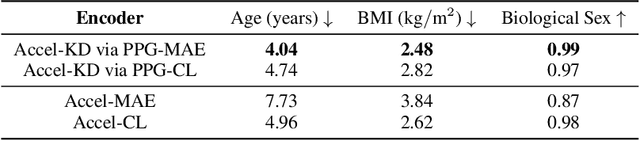
Modern wearable devices can conveniently and continuously record various biosignals in the many different environments of daily living, ultimately enabling a rich view of individual health. However, not all biosignals are the same: high-fidelity measurements, such as photoplethysmography (PPG), contain more physiological information, but require optical sensors with a high power footprint. In a resource-constrained setting, such biosignals may be unavailable. Alternatively, a lower-fidelity biosignal, such as accelerometry that captures minute cardiovascular information during low-motion periods, has a significantly smaller power footprint and is available in almost any wearable device. Here, we demonstrate that we can distill representational knowledge across biosignals, i.e., from PPG to accelerometry, using 20 million minutes of unlabeled data, collected from ~172K participants in the Apple Heart and Movement Study under informed consent. We first pre-train PPG encoders via self-supervised learning, and then distill their representational knowledge to accelerometry encoders. We demonstrate strong cross-modal alignment on unseen data, e.g., 99.2% top-1 accuracy for retrieving PPG embeddings from accelerometry embeddings. We show that distilled accelerometry encoders have significantly more informative representations compared to self-supervised or supervised encoders trained directly on accelerometry data, observed by at least 23%-49% improved performance for predicting heart rate and heart rate variability. We also show that distilled accelerometry encoders are readily predictive of a wide array of downstream health targets, i.e., they are generalist foundation models. We believe accelerometry foundation models for health may unlock new opportunities for developing digital biomarkers from any wearable device, and help individuals track their health more frequently and conveniently.
KerasCV and KerasNLP: Vision and Language Power-Ups
May 31, 2024
We present the Keras domain packages KerasCV and KerasNLP, extensions of the Keras API for Computer Vision and Natural Language Processing workflows, capable of running on either JAX, TensorFlow, or PyTorch. These domain packages are designed to enable fast experimentation, with a focus on ease-of-use and performance. We adopt a modular, layered design: at the library's lowest level of abstraction, we provide building blocks for creating models and data preprocessing pipelines, and at the library's highest level of abstraction, we provide pretrained ``task" models for popular architectures such as Stable Diffusion, YOLOv8, GPT2, BERT, Mistral, CLIP, Gemma, T5, etc. Task models have built-in preprocessing, pretrained weights, and can be fine-tuned on raw inputs. To enable efficient training, we support XLA compilation for all models, and run all preprocessing via a compiled graph of TensorFlow operations using the tf.data API. The libraries are fully open-source (Apache 2.0 license) and available on GitHub.
Smart Watch Supported System for Health Care Monitoring
Apr 16, 2023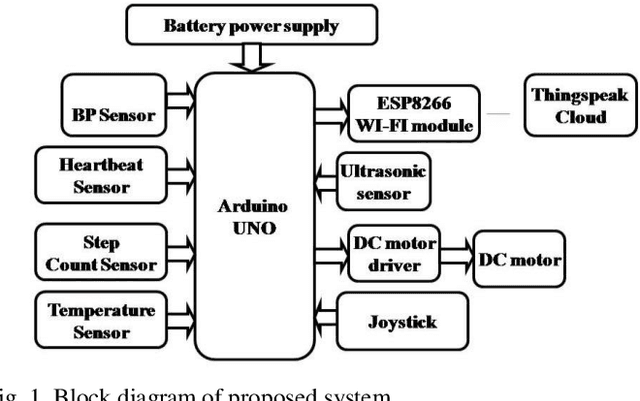



This work presents a smartwatch attached to patients at remote locations, which would help in the navigation of wheel chair and monitor the vitals of patients and relay it through IoT. This wearable smartwatch is equipped with sensors to measure health parameters, namely, heartbeat, blood pressure, body temperature, and step count. An esp8266 Wi-Fi module uploads the health parameters into the thingspeak cloud platform with a time stamp. This smartwatch is equipped with a joystick for cruise and navigation control of the motor driver-enabled wheelchair. Additionally, an ultrasonic sensor mounted in front of the wheelchair continuously scans for any obstacles ahead and stops the motion of the wheelchair upon detection of an obstacle. The primary controller of the system is an Arduino UNO microcontroller, which interfaces the input and output modules.
Reading Comprehension as Natural Language Inference: A Semantic Analysis
Oct 04, 2020
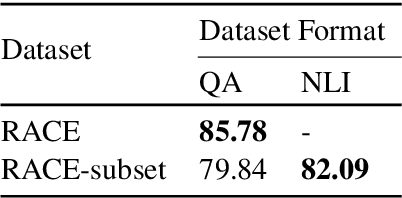
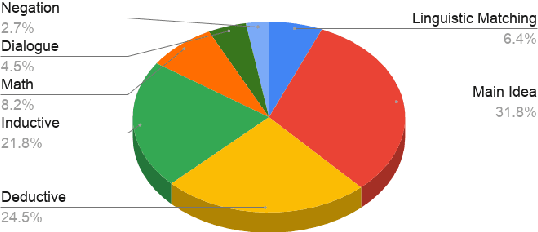
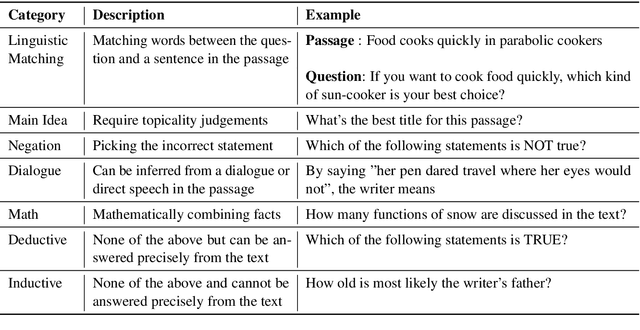
In the recent past, Natural language Inference (NLI) has gained significant attention, particularly given its promise for downstream NLP tasks. However, its true impact is limited and has not been well studied. Therefore, in this paper, we explore the utility of NLI for one of the most prominent downstream tasks, viz. Question Answering (QA). We transform the one of the largest available MRC dataset (RACE) to an NLI form, and compare the performances of a state-of-the-art model (RoBERTa) on both these forms. We propose new characterizations of questions, and evaluate the performance of QA and NLI models on these categories. We highlight clear categories for which the model is able to perform better when the data is presented in a coherent entailment form, and a structured question-answer concatenation form, respectively.
Looking Beyond Sentence-Level Natural Language Inference for Downstream Tasks
Sep 18, 2020
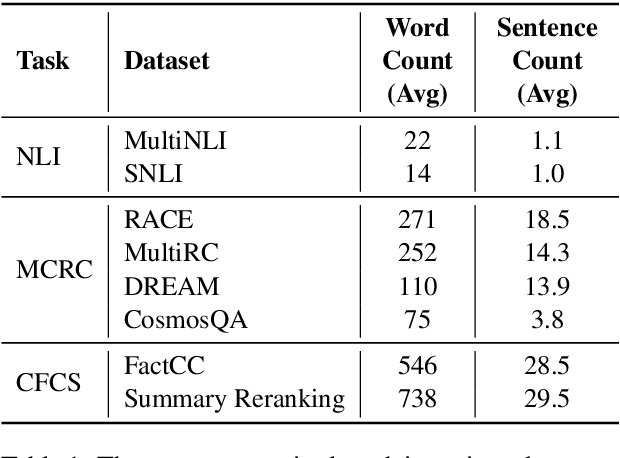
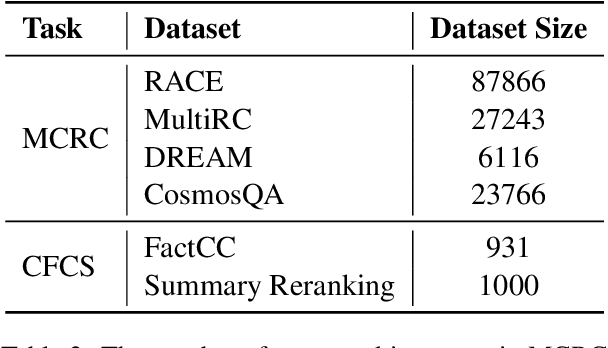
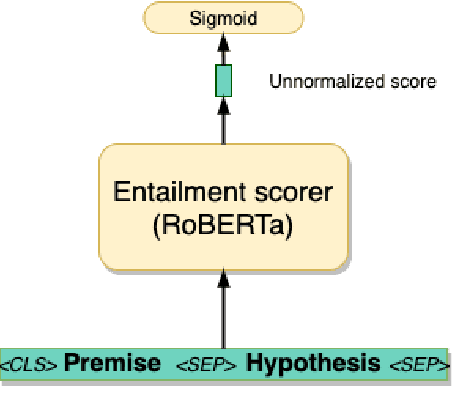
In recent years, the Natural Language Inference (NLI) task has garnered significant attention, with new datasets and models achieving near human-level performance on it. However, the full promise of NLI -- particularly that it learns knowledge that should be generalizable to other downstream NLP tasks -- has not been realized. In this paper, we study this unfulfilled promise from the lens of two downstream tasks: question answering (QA), and text summarization. We conjecture that a key difference between the NLI datasets and these downstream tasks concerns the length of the premise; and that creating new long premise NLI datasets out of existing QA datasets is a promising avenue for training a truly generalizable NLI model. We validate our conjecture by showing competitive results on the task of QA and obtaining the best reported results on the task of Checking Factual Correctness of Summaries.