 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Comprehension as Natural Language Inference: A Semantic Analysis
Paper and Code
Oct 04, 2020
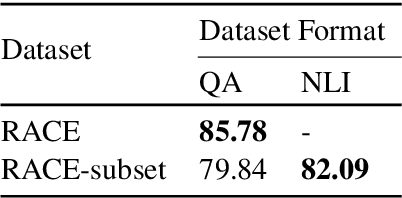
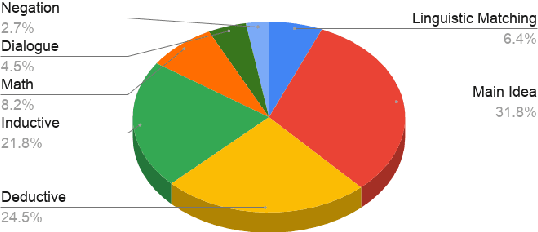
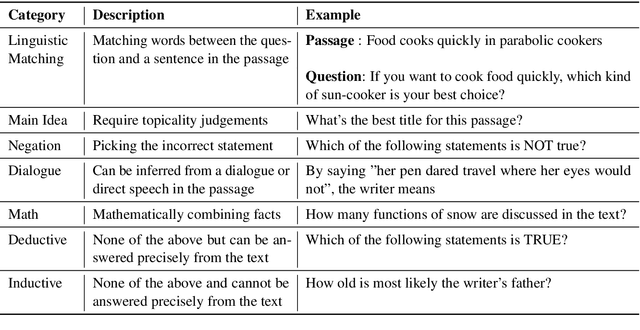
In the recent past, Natural language Inference (NLI) has gained significant attention, particularly given its promise for downstream NLP tasks. However, its true impact is limited and has not been well studied. Therefore, in this paper, we explore the utility of NLI for one of the most prominent downstream tasks, viz. Question Answering (QA). We transform the one of the largest available MRC dataset (RACE) to an NLI form, and compare the performances of a state-of-the-art model (RoBERTa) on both these forms. We propose new characterizations of questions, and evaluate the performance of QA and NLI models on these categories. We highlight clear categories for which the model is able to perform better when the data is presented in a coherent entailment form, and a structured question-answer concatenation form, respectively.