 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: A Tendon-Driven Hand with Hybrid Hard-Soft Compliance
Mar 12, 2026We introduce CRAFT hand, a tendon-driven anthropomorphic hand with hybrid hard-soft compliance for contact-rich manipulation. The design is based on a simple idea: contact is not uniform across the hand. Impacts concentrate at joints, while links carry most of the load. CRAFT places soft material at joints and keeps links rigid, and uses rollingcontact joint surfaces to keep flexion on repeatable motion paths. Fifteen motors mounted on the fingers drive the hand through tendons, keeping the form factor compact and the fingers light. In structural tests, CRAFT improves strength and endurance while maintaining comparable repeatability. In teleoperation, CRAFT improves handling of fragile and low-friction items, and the hand covers 33/33 grasps in the Feix taxonomy. The full design costs under $600 and will be released open-source with visionbased teleoperation and simulation integration. Project page: http://craft-hand.github.io/
VISOR: VIsual Spatial Object Reasoning for Language-driven Object Navigation
Feb 07, 2026Language-driven object navigation requires agents to interpret natural language descriptions of target objects, which combine intrinsic and extrinsic attributes for instance recognition and commonsense navigation. Existing methods either (i) use end-to-end trained models with vision-language embeddings, which struggle to generalize beyond training data and lack action-level explainability, or (ii) rely on modular zero-shot pipelines with large language models (LLMs) and open-set object detectors, which suffer from error propagation, high computational cost, and difficulty integrating their reasoning back into the navigation policy. To this end, we propose a compact 3B-parameter Vision-Language-Action (VLA) agent that performs human-like embodied reasoning for both object recognition and action selection, removing the need for stitched multi-model pipelines. Instead of raw embedding matching, our agent employs explicit image-grounded reasoning to directly answer "Is this the target object?" and "Why should I take this action?" The reasoning process unfolds in three stages: "think", "think summary", and "action", yielding improved explainability, stronger generalization, and more efficient navigation. Code and dataset available upon acceptance.
ViPRA: Video Prediction for Robot Actions
Nov 11, 2025



Can we turn a video prediction model into a robot policy? Videos, including those of humans or teleoperated robots, capture rich physical interactions. However, most of them lack labeled actions, which limits their use in robot learning. We present Video Prediction for Robot Actions (ViPRA), a simple pretraining-finetuning framework that learns continuous robot control from these actionless videos. Instead of directly predicting actions, we train a video-language model to predict both future visual observations and motion-centric latent actions, which serve as intermediate representations of scene dynamics. We train these latent actions using perceptual losses and optical flow consistency to ensure they reflect physically grounded behavior. For downstream control, we introduce a chunked flow matching decoder that maps latent actions to robot-specific continuous action sequences, using only 100 to 200 teleoperated demonstrations. This approach avoids expensive action annotation, supports generalization across embodiments, and enables smooth, high-frequency continuous control upto 22 Hz via chunked action decoding. Unlike prior latent action works that treat pretraining as autoregressive policy learning, explicitly models both what changes and how. Our method outperforms strong baselines, with a 16% gain on the SIMPLER benchmark and a 13% improvement across real world manipulation tasks. We will release models and code at https://vipra-project.github.io
Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Jul 01, 2025This work introduces Robots Imitating Generated Videos (RIGVid), a system that enables robots to perform complex manipulation tasks--such as pouring, wiping, and mixing--purely by imitating AI-generated videos, without requiring any physical demonstrations or robot-specific training. Given a language command and an initial scene image, a video diffusion model generates potential demonstration videos, and a vision-language model (VLM) automatically filters out results that do not follow the command. A 6D pose tracker then extracts object trajectories from the video, and the trajectories are retargeted to the robot in an embodiment-agnostic fashion. Through extensive real-world evaluations, we show that filtered generated videos are as effective as real demonstrations, and that performance improves with generation quality. We also show that relying on generated videos outperforms more compact alternatives such as keypoint prediction using VLMs, and that strong 6D pose tracking outperforms other ways to extract trajectories, such as dense feature point tracking. These findings suggest that videos produced by a state-of-the-art off-the-shelf model can offer an effective source of supervision for robotic manipulation.
An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels
Jun 13, 2024This work does not introduce a new method. Instead, we present an interesting finding that questions the necessity of the inductive bias -- locality in modern computer vision architectures. Concretely, we find that vanilla Transformers can operate by directly treating each individual pixel as a token and achieve highly performant results. This is substantially different from the popular design in Vision Transformer, which maintains the inductive bias from ConvNets towards local neighborhoods (e.g. by treating each 16x16 patch as a token). We mainly showcase the effectiveness of pixels-as-tokens across three well-studied tasks in computer vision: supervised learning for object classification, self-supervised learning via masked autoencoding, and image generation with diffusion models. Although directly operating on individual pixels is less computationally practical, we believe the community must be aware of this surprising piece of knowledge when devising the next generation of neural architectures for computer vision.
Exploitation-Guided Exploration for Semantic Embodied Navigation
Nov 06, 2023In the recent progress in embodied navigation and sim-to-robot transfer, modular policies have emerged as a de facto framework. However, there is more to compositionality beyond the decomposition of the learning load into modular components. In this work, we investigate a principled way to syntactically combine these components. Particularly, we propose Exploitation-Guided Exploration (XGX) where separate modules for exploration and exploitation come together in a novel and intuitive manner. We configure the exploitation module to take over in the deterministic final steps of navigation i.e. when the goal becomes visible. Crucially, an exploitation module teacher-forces the exploration module and continues driving an overridden policy optimization. XGX, with effective decomposition and novel guidance, improves the state-of-the-art performance on the challenging object navigation task from 70% to 73%. Along with better accuracy, through targeted analysis, we show that XGX is also more efficient at goal-conditioned exploration. Finally, we show sim-to-real transfer to robot hardware and XGX performs over two-fold better than the best baseline from simulation benchmarking. Project page: xgxvisnav.github.io
Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots
Oct 19, 2023



We present Habitat 3.0: a simulation platform for studying collaborative human-robot tasks in home environments. Habitat 3.0 offers contributions across three dimensions: (1) Accurate humanoid simulation: addressing challenges in modeling complex deformable bodies and diversity in appearance and motion, all while ensuring high simulation speed. (2) Human-in-the-loop infrastructure: enabling real human interaction with simulated robots via mouse/keyboard or a VR interface, facilitating evaluation of robot policies with human input. (3) Collaborative tasks: studying two collaborative tasks, Social Navigation and Social Rearrangement. Social Navigation investigates a robot's ability to locate and follow humanoid avatars in unseen environments, whereas Social Rearrangement addresses collaboration between a humanoid and robot while rearranging a scene. These contributions allow us to study end-to-end learned and heuristic baselines for human-robot collaboration in-depth, as well as evaluate them with humans in the loop. Our experiments demonstrate that learned robot policies lead to efficient task completion when collaborating with unseen humanoid agents and human partners that might exhibit behaviors that the robot has not seen before. Additionally, we observe emergent behaviors during collaborative task execution, such as the robot yielding space when obstructing a humanoid agent, thereby allowing the effective completion of the task by the humanoid agent. Furthermore, our experiments using the human-in-the-loop tool demonstrate that our automated evaluation with humanoids can provide an indication of the relative ordering of different policies when evaluated with real human collaborators. Habitat 3.0 unlocks interesting new features in simulators for Embodied AI, and we hope it paves the way for a new frontier of embodied human-AI interaction capabilities.
An Unbiased Look at Datasets for Visuo-Motor Pre-Training
Oct 13, 2023Visual representation learning hold great promise for robotics, but is severely hampered by the scarcity and homogeneity of robotics datasets. Recent works address this problem by pre-training visual representations on large-scale but out-of-domain data (e.g., videos of egocentric interactions) and then transferring them to target robotics tasks. While the field is heavily focused on developing better pre-training algorithms, we find that dataset choice is just as important to this paradigm's success. After all, the representation can only learn the structures or priors present in the pre-training dataset. To this end, we flip the focus on algorithms, and instead conduct a dataset centric analysis of robotic pre-training. Our findings call into question some common wisdom in the field. We observe that traditional vision datasets (like ImageNet, Kinetics and 100 Days of Hands) are surprisingly competitive options for visuo-motor representation learning, and that the pre-training dataset's image distribution matters more than its size. Finally, we show that common simulation benchmarks are not a reliable proxy for real world performance and that simple regularization strategies can dramatically improve real world policy learning. https://data4robotics.github.io
Adaptive Coordination in Social Embodied Rearrangement
May 31, 2023
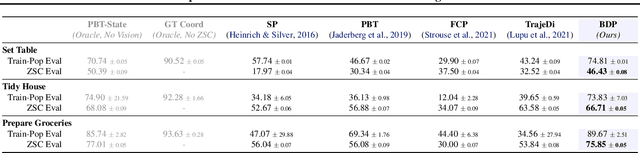
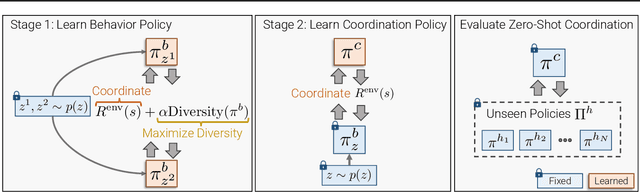
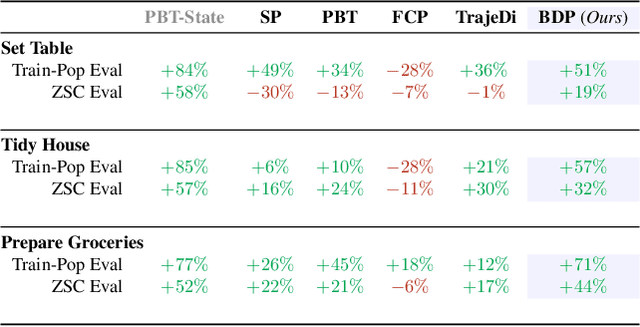
We present the task of "Social Rearrangement", consisting of cooperative everyday tasks like setting up the dinner table, tidying a house or unpacking groceries in a simulated multi-agent environment. In Social Rearrangement, two robots coordinate to complete a long-horizon task, using onboard sensing and egocentric observations, and no privileged information about the environment. We study zero-shot coordination (ZSC) in this task, where an agent collaborates with a new partner, emulating a scenario where a robot collaborates with a new human partner. Prior ZSC approaches struggle to generalize in our complex and visually rich setting, and on further analysis, we find that they fail to generate diverse coordination behaviors at training time. To counter this, we propose Behavior Diversity Play (BDP), a novel ZSC approach that encourages diversity through a discriminability objective. Our results demonstrate that BDP learns adaptive agents that can tackle visual coordination, and zero-shot generalize to new partners in unseen environments, achieving 35% higher success and 32% higher efficiency compared to baselines.
Pretrained Language Models as Visual Planners for Human Assistance
Apr 27, 2023To make progress towards multi-modal AI assistants which can guide users to achieve complex multi-step goals, we propose the task of Visual Planning for Assistance (VPA). Given a goal briefly described in natural language, e.g., "make a shelf", and a video of the user's progress so far, the aim of VPA is to obtain a plan, i.e., a sequence of actions such as "sand shelf", "paint shelf", etc., to achieve the goal. This requires assessing the user's progress from the untrimmed video, and relating it to the requirements of underlying goal, i.e., relevance of actions and ordering dependencies amongst them. Consequently, this requires handling long video history, and arbitrarily complex action dependencies. To address these challenges, we decompose VPA into video action segmentation and forecasting. We formulate the forecasting step as a multi-modal sequence modeling problem and present Visual Language Model based Planner (VLaMP), which leverages pre-trained LMs as the sequence model. We demonstrate that VLaMP performs significantly better than baselines w.r.t all metrics that evaluate the generated plan. Moreover, through extensive ablations, we also isolate the value of language pre-training, visual observations, and goal information on the performance. We will release our data, model, and code to enable future research on visual planning for assistance.