 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDA: Reward Design Agent for Reinforcement Learning
Jun 01, 2026Reinforcement learning has enabled the acquisition of impressive robotic skills, but typically requires hand-crafted reward functions that are slow to design and difficult to align with human intentions. Recent work, such as Eureka, automates reward design by using an LLM to iteratively generate and refine reward code from task descriptions. However, they rely on coarse feedback signals such as success rate, which provide little semantic insight into the learned behavior. As a result, their trained policies achieve the final goal but are frequently poorly aligned with task instructions. We introduce the Reward Design Agent (RDA), a VLM-based agentic framework that injects semantic understanding into reward design. RDA decomposes tasks, visually evaluates trajectories, summarizes failure modes, and iteratively revises reward code to better align with task instructions. Across 12 tabletop manipulation tasks from ManiSkill and 4 whole-body manipulation tasks from HumanoidBench, RDA produces policies substantially more instruction-aligned than those of other baselines, while achieving comparable task success rates. Videos and the generated reward code are available on https://nitinkamra1992.github.io/reward-design-agent.
DigiData: Training and Evaluating General-Purpose Mobile Control Agents
Nov 11, 2025AI agents capable of controlling user interfaces have the potential to transform human interaction with digital devices. To accelerate this transformation, two fundamental building blocks are essential: high-quality datasets that enable agents to achieve complex and human-relevant goals, and robust evaluation methods that allow researchers and practitioners to rapidly enhance agent performance. In this paper, we introduce DigiData, a large-scale, high-quality, diverse, multi-modal dataset designed for training mobile control agents. Unlike existing datasets, which derive goals from unstructured interactions, DigiData is meticulously constructed through comprehensive exploration of app features, resulting in greater diversity and higher goal complexity. Additionally, we present DigiData-Bench, a benchmark for evaluating mobile control agents on real-world complex tasks. We demonstrate that the commonly used step-accuracy metric falls short in reliably assessing mobile control agents and, to address this, we propose dynamic evaluation protocols and AI-powered evaluations as rigorous alternatives for agent assessment. Our contributions aim to significantly advance the development of mobile control agents, paving the way for more intuitive and effective human-device interactions.
Benchmarking Egocentric Multimodal Goal Inference for Assistive Wearable Agents
Oct 25, 2025There has been a surge of interest in assistive wearable agents: agents embodied in wearable form factors (e.g., smart glasses) who take assistive actions toward a user's goal/query (e.g. "Where did I leave my keys?"). In this work, we consider the important complementary problem of inferring that goal from multi-modal contextual observations. Solving this "goal inference" problem holds the promise of eliminating the effort needed to interact with such an agent. This work focuses on creating WAGIBench, a strong benchmark to measure progress in solving this problem using vision-language models (VLMs). Given the limited prior work in this area, we collected a novel dataset comprising 29 hours of multimodal data from 348 participants across 3,477 recordings, featuring ground-truth goals alongside accompanying visual, audio, digital, and longitudinal contextual observations. We validate that human performance exceeds model performance, achieving 93% multiple-choice accuracy compared with 84% for the best-performing VLM. Generative benchmark results that evaluate several families of modern vision-language models show that larger models perform significantly better on the task, yet remain far from practical usefulness, as they produce relevant goals only 55% of the time. Through a modality ablation, we show that models benefit from extra information in relevant modalities with minimal performance degradation from irrelevant modalities.
Human-Centered Planning
Nov 08, 2023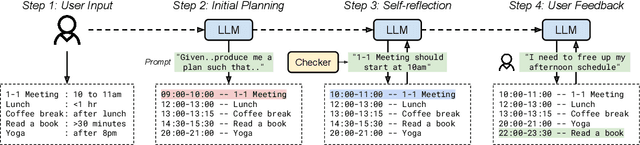
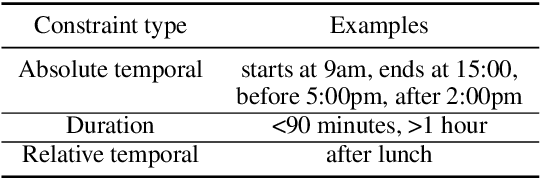
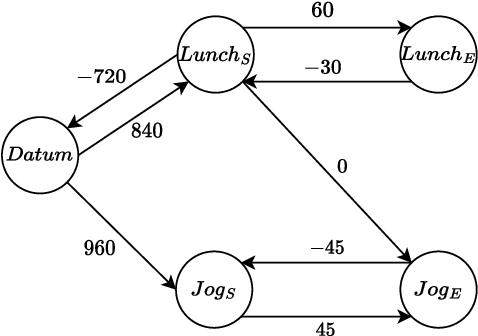

LLMs have recently made impressive inroads on tasks whose output is structured, such as coding, robotic planning and querying databases. The vision of creating AI-powered personal assistants also involves creating structured outputs, such as a plan for one's day, or for an overseas trip. Here, since the plan is executed by a human, the output doesn't have to satisfy strict syntactic constraints. A useful assistant should also be able to incorporate vague constraints specified by the user in natural language. This makes LLMs an attractive option for planning. We consider the problem of planning one's day. We develop an LLM-based planner (LLMPlan) extended with the ability to self-reflect on its output and a symbolic planner (SymPlan) with the ability to translate text constraints into a symbolic representation. Despite no formal specification of constraints, we find that LLMPlan performs explicit constraint satisfaction akin to the traditional symbolic planners on average (2% performance difference), while retaining the reasoning of implicit requirements. Consequently, LLM-based planners outperform their symbolic counterparts in user satisfaction (70.5% vs. 40.4%) during interactive evaluation with 40 users.
Pretrained Language Models as Visual Planners for Human Assistance
Apr 27, 2023To make progress towards multi-modal AI assistants which can guide users to achieve complex multi-step goals, we propose the task of Visual Planning for Assistance (VPA). Given a goal briefly described in natural language, e.g., "make a shelf", and a video of the user's progress so far, the aim of VPA is to obtain a plan, i.e., a sequence of actions such as "sand shelf", "paint shelf", etc., to achieve the goal. This requires assessing the user's progress from the untrimmed video, and relating it to the requirements of underlying goal, i.e., relevance of actions and ordering dependencies amongst them. Consequently, this requires handling long video history, and arbitrarily complex action dependencies. To address these challenges, we decompose VPA into video action segmentation and forecasting. We formulate the forecasting step as a multi-modal sequence modeling problem and present Visual Language Model based Planner (VLaMP), which leverages pre-trained LMs as the sequence model. We demonstrate that VLaMP performs significantly better than baselines w.r.t all metrics that evaluate the generated plan. Moreover, through extensive ablations, we also isolate the value of language pre-training, visual observations, and goal information on the performance. We will release our data, model, and code to enable future research on visual planning for assistance.
EgoTV: Egocentric Task Verification from Natural Language Task Descriptions
Apr 17, 2023To enable progress towards egocentric agents capable of understanding everyday tasks specified in natural language, we propose a benchmark and a synthetic dataset called Egocentric Task Verification (EgoTV). EgoTV contains multi-step tasks with multiple sub-task decompositions, state changes, object interactions, and sub-task ordering constraints, in addition to abstracted task descriptions that contain only partial details about ways to accomplish a task. We also propose a novel Neuro-Symbolic Grounding (NSG) approach to enable the causal, temporal, and compositional reasoning of such tasks. We demonstrate NSG's capability towards task tracking and verification on our EgoTV dataset and a real-world dataset derived from CrossTask (CTV). Our contributions include the release of the EgoTV and CTV datasets, and the NSG model for future research on egocentric assistive agents.
Effective Baselines for Multiple Object Rearrangement Planning in Partially Observable Mapped Environments
Jan 24, 2023
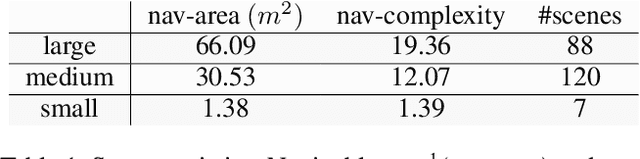

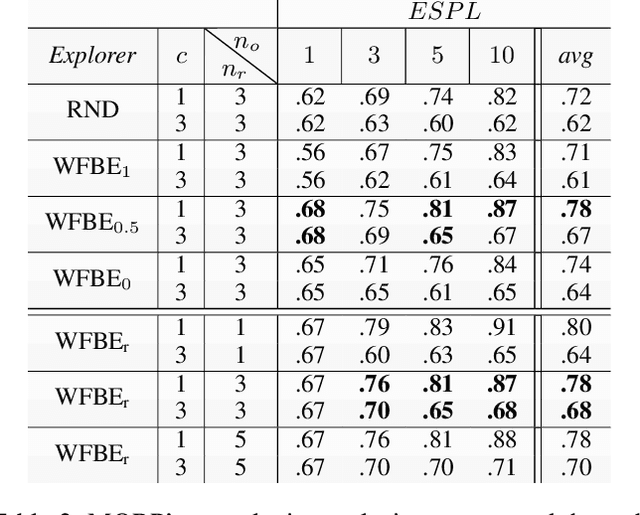
Many real-world tasks, from house-cleaning to cooking, can be formulated as multi-object rearrangement problems -- where an agent needs to get specific objects into appropriate goal states. For such problems, we focus on the setting that assumes a pre-specified goal state, availability of perfect manipulation and object recognition capabilities, and a static map of the environment but unknown initial location of objects to be rearranged. Our goal is to enable home-assistive intelligent agents to efficiently plan for rearrangement under such partial observability. This requires efficient trade-offs between exploration of the environment and planning for rearrangement, which is challenging because of long-horizon nature of the problem. To make progress on this problem, we first analyze the effects of various factors such as number of objects and receptacles, agent carrying capacity, environment layouts etc. on exploration and planning for rearrangement using classical methods. We then investigate both monolithic and modular deep reinforcement learning (DRL) methods for planning in our setting. We find that monolithic DRL methods do not succeed at long-horizon planning needed for multi-object rearrangement. Instead, modular greedy approaches surprisingly perform reasonably well and emerge as competitive baselines for planning with partial observability in multi-object rearrangement problems. We also show that our greedy modular agents are empirically optimal when the objects that need to be rearranged are uniformly distributed in the environment -- thereby contributing baselines with strong performance for future work on multi-object rearrangement planning in partially observable settings.
Multi-agent Trajectory Prediction with Fuzzy Query Attention
Oct 29, 2020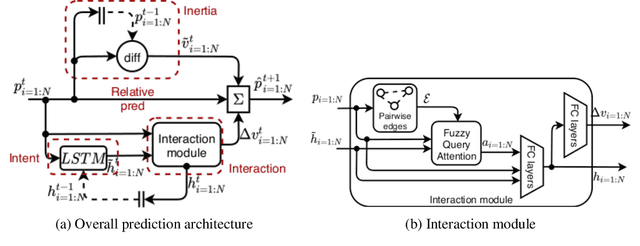
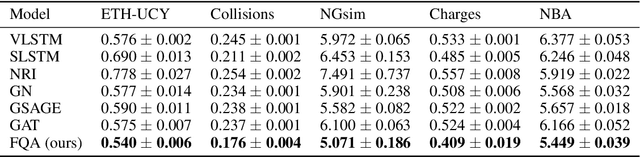
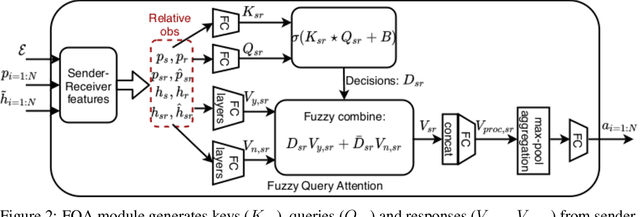

Trajectory prediction for scenes with multiple agents and entities is a challenging problem in numerous domains such as traffic prediction, pedestrian tracking and path planning. We present a general architecture to address this challenge which models the crucial inductive biases of motion, namely, inertia, relative motion, intents and interactions. Specifically, we propose a relational model to flexibly model interactions between agents in diverse environments. Since it is well-known that human decision making is fuzzy by nature, at the core of our model lies a novel attention mechanism which models interactions by making continuous-valued (fuzzy) decisions and learning the corresponding responses. Our architecture demonstrates significant performance gains over existing state-of-the-art predictive models in diverse domains such as human crowd trajectories, US freeway traffic, NBA sports data and physics datasets. We also present ablations and augmentations to understand the decision-making process and the source of gains in our model.
Deep Generative Dual Memory Network for Continual Learning
May 25, 2018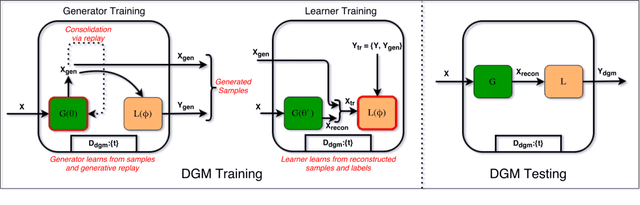
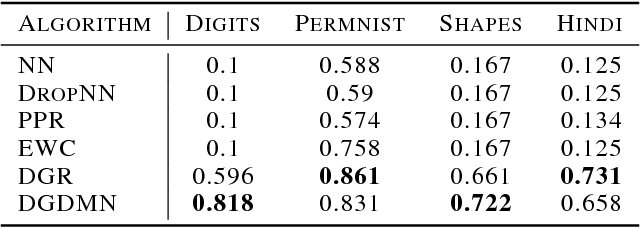

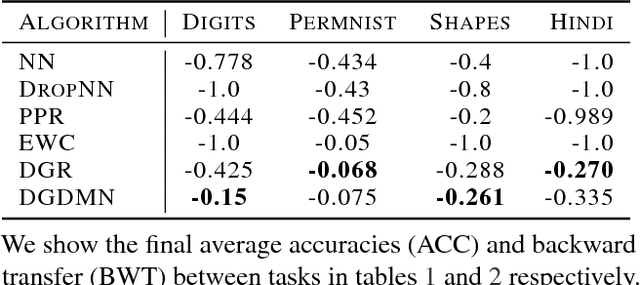
Despite advances in deep learning, neural networks can only learn multiple tasks when trained on them jointly. When tasks arrive sequentially, they lose performance on previously learnt tasks. This phenomenon called catastrophic forgetting is a fundamental challenge to overcome before neural networks can learn continually from incoming data. In this work, we derive inspiration from human memory to develop an architecture capable of learning continuously from sequentially incoming tasks, while averting catastrophic forgetting. Specifically, our contributions are: (i) a dual memory architecture emulating the complementary learning systems (hippocampus and the neocortex) in the human brain, (ii) memory consolidation via generative replay of past experiences, (iii) demonstrating advantages of generative replay and dual memories via experiments, and (iv) improved performance retention on challenging tasks even for low capacity models. Our architecture displays many characteristics of the mammalian memory and provides insights on the connection between sleep and learning.