 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProt42: a Novel Family of Protein Language Models for Target-aware Protein Binder Generation
Apr 06, 2025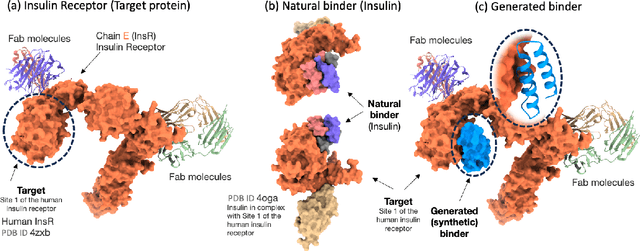
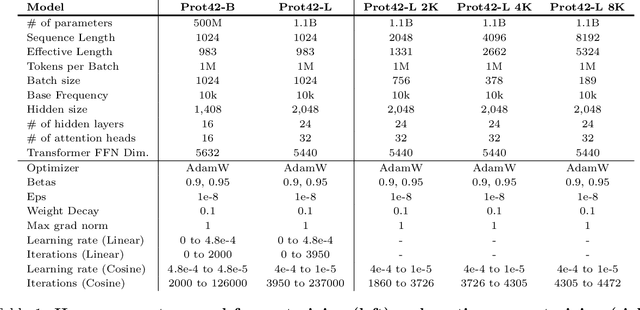

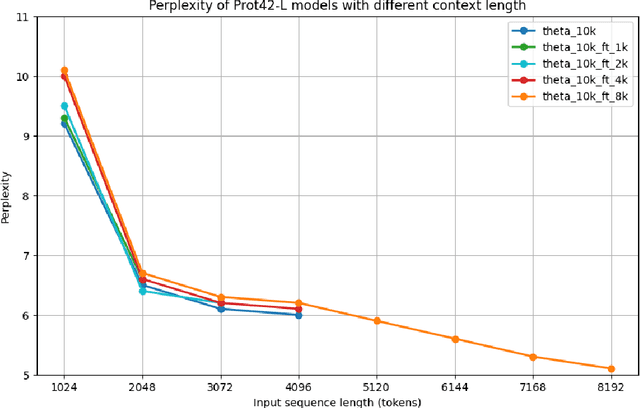
Unlocking the next generation of biotechnology and therapeutic innovation demands overcoming the inherent complexity and resource-intensity of conventional protein engineering methods. Recent GenAI-powered computational techniques often rely on the availability of the target protein's 3D structures and specific binding sites to generate high-affinity binders, constraints exhibited by models such as AlphaProteo and RFdiffusion. In this work, we explore the use of Protein Language Models (pLMs) for high-affinity binder generation. We introduce Prot42, a novel family of Protein Language Models (pLMs) pretrained on vast amounts of unlabeled protein sequences. By capturing deep evolutionary, structural, and functional insights through an advanced auto-regressive, decoder-only architecture inspired by breakthroughs in natural language processing, Prot42 dramatically expands the capabilities of computational protein design based on language only. Remarkably, our models handle sequences up to 8,192 amino acids, significantly surpassing standard limitations and enabling precise modeling of large proteins and complex multi-domain sequences. Demonstrating powerful practical applications, Prot42 excels in generating high-affinity protein binders and sequence-specific DNA-binding proteins. Our innovative models are publicly available, offering the scientific community an efficient and precise computational toolkit for rapid protein engineering.
Chem42: a Family of chemical Language Models for Target-aware Ligand Generation
Mar 20, 2025Revolutionizing drug discovery demands more than just understanding molecular interactions - it requires generative models that can design novel ligands tailored to specific biological targets. While chemical Language Models (cLMs) have made strides in learning molecular properties, most fail to incorporate target-specific insights, restricting their ability to drive de-novo ligand generation. Chem42, a cutting-edge family of generative chemical Language Models, is designed to bridge this gap. By integrating atomic-level interactions with multimodal inputs from Prot42, a complementary protein Language Model, Chem42 achieves a sophisticated cross-modal representation of molecular structures, interactions, and binding patterns. This innovative framework enables the creation of structurally valid, synthetically accessible ligands with enhanced target specificity. Evaluations across diverse protein targets confirm that Chem42 surpasses existing approaches in chemical validity, target-aware design, and predicted binding affinity. By reducing the search space of viable drug candidates, Chem42 could accelerate the drug discovery pipeline, offering a powerful generative AI tool for precision medicine. Our Chem42 models set a new benchmark in molecule property prediction, conditional molecule generation, and target-aware ligand design. The models are publicly available at huggingface.co/inceptionai.
Gene42: Long-Range Genomic Foundation Model With Dense Attention
Mar 20, 2025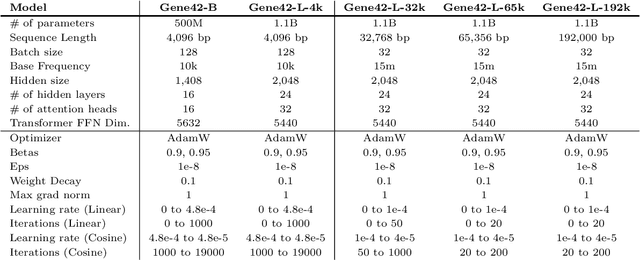
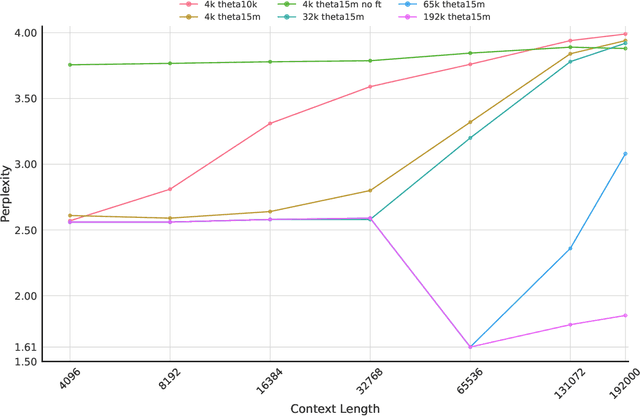
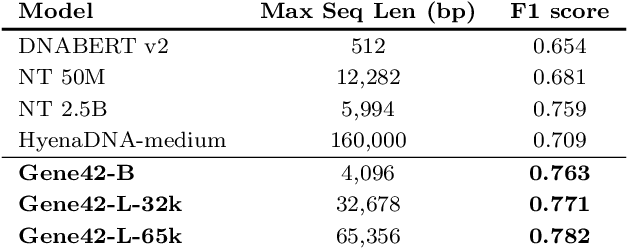
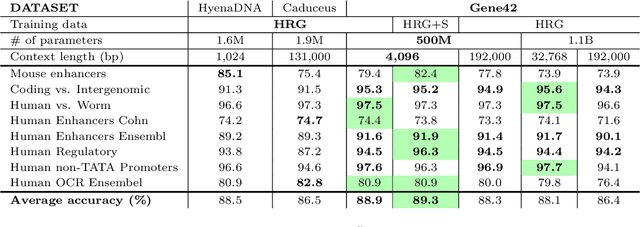
We introduce Gene42, a novel family of Genomic Foundation Models (GFMs) designed to manage context lengths of up to 192,000 base pairs (bp) at a single-nucleotide resolution. Gene42 models utilize a decoder-only (LLaMA-style) architecture with a dense self-attention mechanism. Initially trained on fixed-length sequences of 4,096 bp, our models underwent continuous pretraining to extend the context length to 192,000 bp. This iterative extension allowed for the comprehensive processing of large-scale genomic data and the capture of intricate patterns and dependencies within the human genome. Gene42 is the first dense attention model capable of handling such extensive long context lengths in genomics, challenging state-space models that often rely on convolutional operators among other mechanisms. Our pretrained models exhibit notably low perplexity values and high reconstruction accuracy, highlighting their strong ability to model genomic data. Extensive experiments on various genomic benchmarks have demonstrated state-of-the-art performance across multiple tasks, including biotype classification, regulatory region identification, chromatin profiling prediction, variant pathogenicity prediction, and species classification. The models are publicly available at huggingface.co/inceptionai.
Effective Baselines for Multiple Object Rearrangement Planning in Partially Observable Mapped Environments
Jan 24, 2023
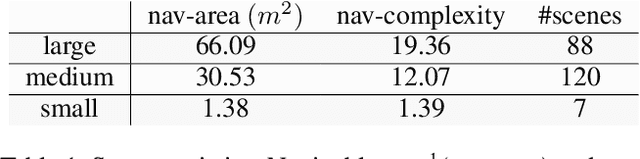

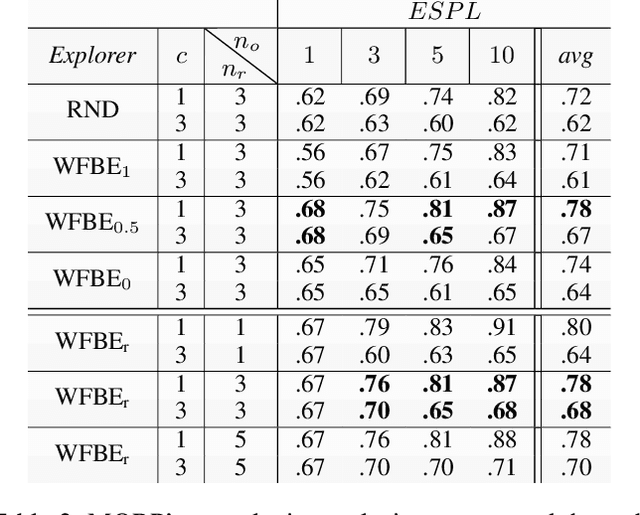
Many real-world tasks, from house-cleaning to cooking, can be formulated as multi-object rearrangement problems -- where an agent needs to get specific objects into appropriate goal states. For such problems, we focus on the setting that assumes a pre-specified goal state, availability of perfect manipulation and object recognition capabilities, and a static map of the environment but unknown initial location of objects to be rearranged. Our goal is to enable home-assistive intelligent agents to efficiently plan for rearrangement under such partial observability. This requires efficient trade-offs between exploration of the environment and planning for rearrangement, which is challenging because of long-horizon nature of the problem. To make progress on this problem, we first analyze the effects of various factors such as number of objects and receptacles, agent carrying capacity, environment layouts etc. on exploration and planning for rearrangement using classical methods. We then investigate both monolithic and modular deep reinforcement learning (DRL) methods for planning in our setting. We find that monolithic DRL methods do not succeed at long-horizon planning needed for multi-object rearrangement. Instead, modular greedy approaches surprisingly perform reasonably well and emerge as competitive baselines for planning with partial observability in multi-object rearrangement problems. We also show that our greedy modular agents are empirically optimal when the objects that need to be rearranged are uniformly distributed in the environment -- thereby contributing baselines with strong performance for future work on multi-object rearrangement planning in partially observable settings.
An End-to-end Deep Reinforcement Learning Approach for the Long-term Short-term Planning on the Frenet Space
Nov 26, 2020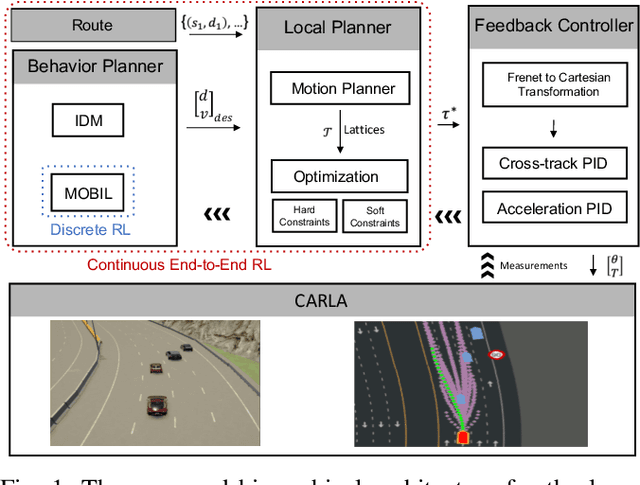

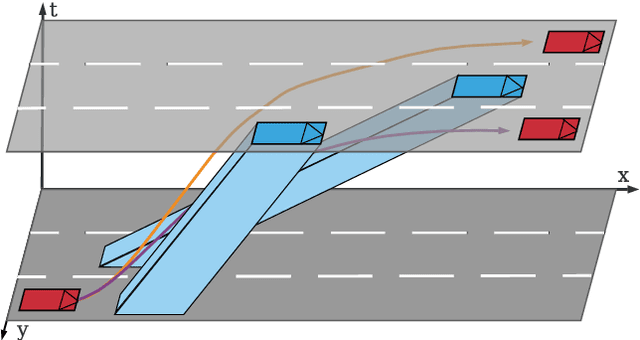
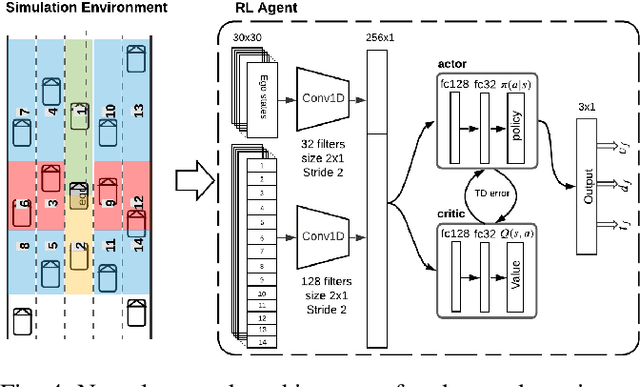
Tactical decision making and strategic motion planning for autonomous highway driving are challenging due to the complication of predicting other road users' behaviors, diversity of environments, and complexity of the traffic interactions. This paper presents a novel end-to-end continuous deep reinforcement learning approach towards autonomous cars' decision-making and motion planning. For the first time, we define both states and action spaces on the Frenet space to make the driving behavior less variant to the road curvatures than the surrounding actors' dynamics and traffic interactions. The agent receives time-series data of past trajectories of the surrounding vehicles and applies convolutional neural networks along the time channels to extract features in the backbone. The algorithm generates continuous spatiotemporal trajectories on the Frenet frame for the feedback controller to track. Extensive high-fidelity highway simulations on CARLA show the superiority of the presented approach compared with commonly used baselines and discrete reinforcement learning on various traffic scenarios. Furthermore, the proposed method's advantage is confirmed with a more comprehensive performance evaluation against 1000 randomly generated test scenarios.