 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGene42: Long-Range Genomic Foundation Model With Dense Attention
Mar 20, 2025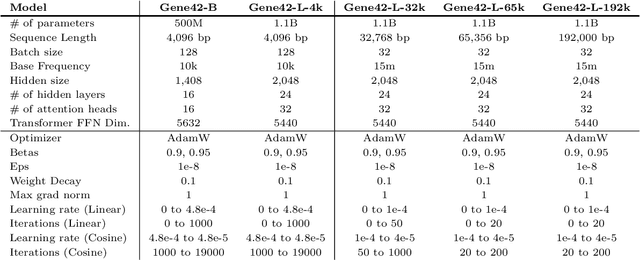
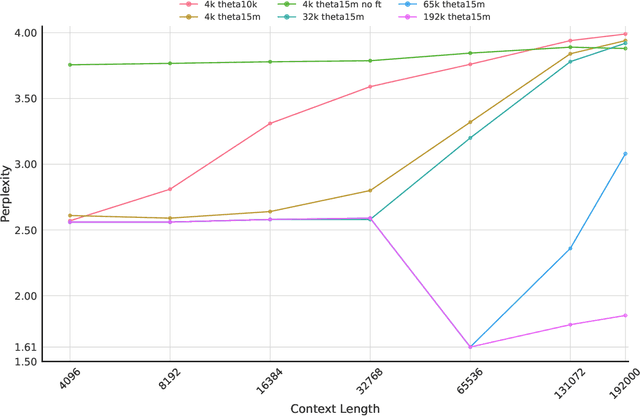
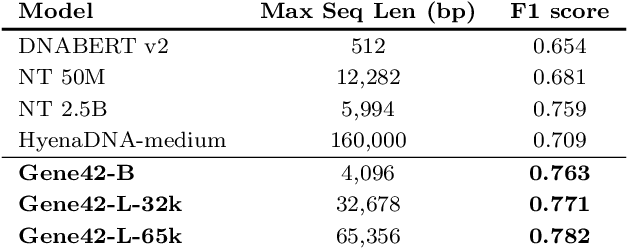
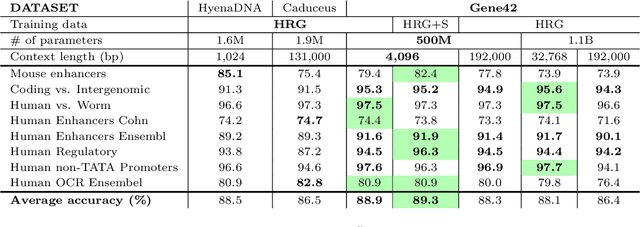
We introduce Gene42, a novel family of Genomic Foundation Models (GFMs) designed to manage context lengths of up to 192,000 base pairs (bp) at a single-nucleotide resolution. Gene42 models utilize a decoder-only (LLaMA-style) architecture with a dense self-attention mechanism. Initially trained on fixed-length sequences of 4,096 bp, our models underwent continuous pretraining to extend the context length to 192,000 bp. This iterative extension allowed for the comprehensive processing of large-scale genomic data and the capture of intricate patterns and dependencies within the human genome. Gene42 is the first dense attention model capable of handling such extensive long context lengths in genomics, challenging state-space models that often rely on convolutional operators among other mechanisms. Our pretrained models exhibit notably low perplexity values and high reconstruction accuracy, highlighting their strong ability to model genomic data. Extensive experiments on various genomic benchmarks have demonstrated state-of-the-art performance across multiple tasks, including biotype classification, regulatory region identification, chromatin profiling prediction, variant pathogenicity prediction, and species classification. The models are publicly available at huggingface.co/inceptionai.
Initializing Models with Larger Ones
Nov 30, 2023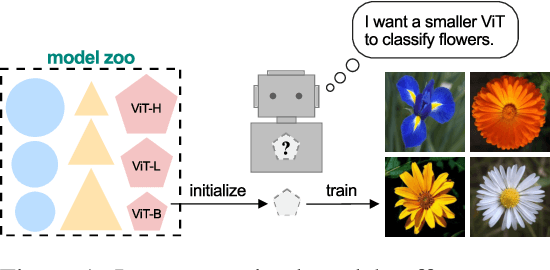



Weight initialization plays an important role in neural network training. Widely used initialization methods are proposed and evaluated for networks that are trained from scratch. However, the growing number of pretrained models now offers new opportunities for tackling this classical problem of weight initialization. In this work, we introduce weight selection, a method for initializing smaller models by selecting a subset of weights from a pretrained larger model. This enables the transfer of knowledge from pretrained weights to smaller models. Our experiments demonstrate that weight selection can significantly enhance the performance of small models and reduce their training time. Notably, it can also be used together with knowledge distillation. Weight selection offers a new approach to leverage the power of pretrained models in resource-constrained settings, and we hope it can be a useful tool for training small models in the large-model era. Code is available at https://github.com/OscarXZQ/weight-selection.
ConvNet vs Transformer, Supervised vs CLIP: Beyond ImageNet Accuracy
Nov 15, 2023Modern computer vision offers a great variety of models to practitioners, and selecting a model from multiple options for specific applications can be challenging. Conventionally, competing model architectures and training protocols are compared by their classification accuracy on ImageNet. However, this single metric does not fully capture performance nuances critical for specialized tasks. In this work, we conduct an in-depth comparative analysis of model behaviors beyond ImageNet accuracy, for both ConvNet and Vision Transformer architectures, each across supervised and CLIP training paradigms. Although our selected models have similar ImageNet accuracies and compute requirements, we find that they differ in many other aspects: types of mistakes, output calibration, transferability, and feature invariance, among others. This diversity in model characteristics, not captured by traditional metrics, highlights the need for more nuanced analysis when choosing among different models. Our code is available at https://github.com/kirill-vish/Beyond-INet.
MixMask: Revisiting Masked Siamese Self-supervised Learning in Asymmetric Distance
Oct 20, 2022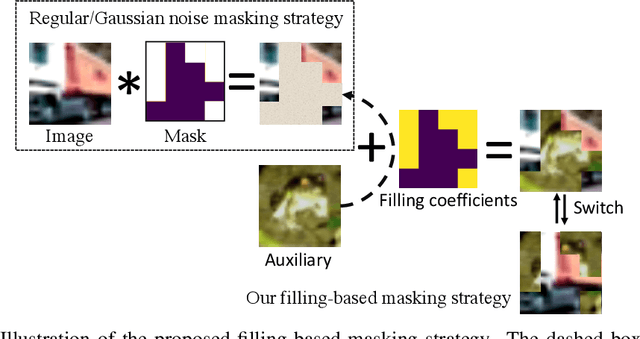
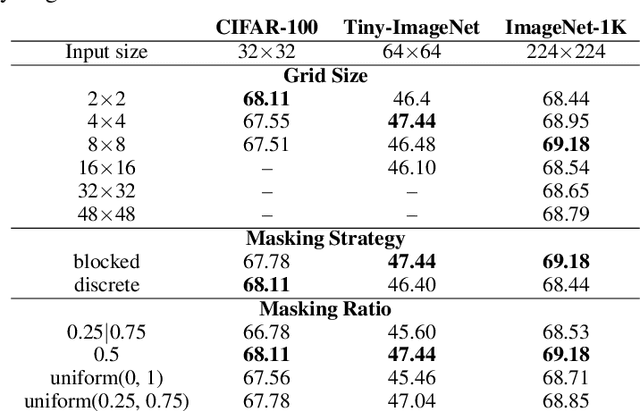
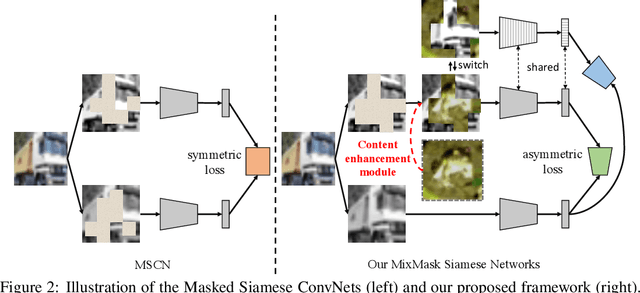

Recent advances in self-supervised learning integrate Masked Modeling and Siamese Networks into a single framework to fully reap the advantages of both the two techniques. However, previous erasing-based masking scheme in masked image modeling is not originally designed for siamese networks. Existing approaches simply inherit the default loss design from previous siamese networks, and ignore the information loss and distance change after employing masking operation in the frameworks. In this paper, we propose a filling-based masking strategy called MixMask to prevent information loss due to the randomly erased areas of an image in vanilla masking method. We further introduce a dynamic loss function design with soft distance to adapt the integrated architecture and avoid mismatches between transformed input and objective in Masked Siamese ConvNets (MSCN). The dynamic loss distance is calculated according to the proposed mix-masking scheme. Extensive experiments are conducted on various datasets of CIFAR-100, Tiny-ImageNet and ImageNet-1K. The results demonstrate that the proposed framework can achieve better accuracy on linear probing, semi-supervised and {supervised finetuning}, which outperforms the state-of-the-art MSCN by a significant margin. We also show the superiority on downstream tasks of object detection and segmentation. Our source code is available at https://github.com/LightnessOfBeing/MixMask.