 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUEval: A Benchmark for Unified Multimodal Generation
Jan 29, 2026We introduce UEval, a benchmark to evaluate unified models, i.e., models capable of generating both images and text. UEval comprises 1,000 expert-curated questions that require both images and text in the model output, sourced from 8 real-world tasks. Our curated questions cover a wide range of reasoning types, from step-by-step guides to textbook explanations. Evaluating open-ended multimodal generation is non-trivial, as simple LLM-as-a-judge methods can miss the subtleties. Different from previous works that rely on multimodal Large Language Models (MLLMs) to rate image quality or text accuracy, we design a rubric-based scoring system in UEval. For each question, reference images and text answers are provided to a MLLM to generate an initial rubric, consisting of multiple evaluation criteria, and human experts then refine and validate these rubrics. In total, UEval contains 10,417 validated rubric criteria, enabling scalable and fine-grained automatic scoring. UEval is challenging for current unified models: GPT-5-Thinking scores only 66.4 out of 100, while the best open-source model reaches merely 49.1. We observe that reasoning models often outperform non-reasoning ones, and transferring reasoning traces from a reasoning model to a non-reasoning model significantly narrows the gap. This suggests that reasoning may be important for tasks requiring complex multimodal understanding and generation.
Generative Modeling of Weights: Generalization or Memorization?
Jun 09, 2025Generative models, with their success in image and video generation, have recently been explored for synthesizing effective neural network weights. These approaches take trained neural network checkpoints as training data, and aim to generate high-performing neural network weights during inference. In this work, we examine four representative methods on their ability to generate novel model weights, i.e., weights that are different from the checkpoints seen during training. Surprisingly, we find that these methods synthesize weights largely by memorization: they produce either replicas, or at best simple interpolations, of the training checkpoints. Current methods fail to outperform simple baselines, such as adding noise to the weights or taking a simple weight ensemble, in obtaining different and simultaneously high-performing models. We further show that this memorization cannot be effectively mitigated by modifying modeling factors commonly associated with memorization in image diffusion models, or applying data augmentations. Our findings provide a realistic assessment of what types of data current generative models can model, and highlight the need for more careful evaluation of generative models in new domains. Our code is available at https://github.com/boyazeng/weight_memorization.
Idiosyncrasies in Large Language Models
Feb 17, 2025



In this work, we unveil and study idiosyncrasies in Large Language Models (LLMs) -- unique patterns in their outputs that can be used to distinguish the models. To do so, we consider a simple classification task: given a particular text output, the objective is to predict the source LLM that generates the text. We evaluate this synthetic task across various groups of LLMs and find that simply fine-tuning existing text embedding models on LLM-generated texts yields excellent classification accuracy. Notably, we achieve 97.1% accuracy on held-out validation data in the five-way classification problem involving ChatGPT, Claude, Grok, Gemini, and DeepSeek. Our further investigation reveals that these idiosyncrasies are rooted in word-level distributions. These patterns persist even when the texts are rewritten, translated, or summarized by an external LLM, suggesting that they are also encoded in the semantic content. Additionally, we leverage LLM as judges to generate detailed, open-ended descriptions of each model's idiosyncrasies. Finally, we discuss the broader implications of our findings, particularly for training on synthetic data and inferring model similarity. Code is available at https://github.com/locuslab/llm-idiosyncrasies.
Understanding Bias in Large-Scale Visual Datasets
Dec 02, 2024A recent study has shown that large-scale visual datasets are very biased: they can be easily classified by modern neural networks. However, the concrete forms of bias among these datasets remain unclear. In this study, we propose a framework to identify the unique visual attributes distinguishing these datasets. Our approach applies various transformations to extract semantic, structural, boundary, color, and frequency information from datasets, and assess how much each type of information reflects their bias. We further decompose their semantic bias with object-level analysis, and leverage natural language methods to generate detailed, open-ended descriptions of each dataset's characteristics. Our work aims to help researchers understand the bias in existing large-scale pre-training datasets, and build more diverse and representative ones in the future. Our project page and code are available at http://boyazeng.github.io/understand_bias .
In-Context Learning Enables Robot Action Prediction in LLMs
Oct 16, 2024Recently, Large Language Models (LLMs) have achieved remarkable success using in-context learning (ICL) in the language domain. However, leveraging the ICL capabilities within LLMs to directly predict robot actions remains largely unexplored. In this paper, we introduce RoboPrompt, a framework that enables off-the-shelf text-only LLMs to directly predict robot actions through ICL without training. Our approach first heuristically identifies keyframes that capture important moments from an episode. Next, we extract end-effector actions from these keyframes as well as the estimated initial object poses, and both are converted into textual descriptions. Finally, we construct a structured template to form ICL demonstrations from these textual descriptions and a task instruction. This enables an LLM to directly predict robot actions at test time. Through extensive experiments and analysis, RoboPrompt shows stronger performance over zero-shot and ICL baselines in simulated and real-world settings.
MATRIX: Multi-Agent Trajectory Generation with Diverse Contexts
Mar 09, 2024



Data-driven methods have great advantages in modeling complicated human behavioral dynamics and dealing with many human-robot interaction applications. However, collecting massive and annotated real-world human datasets has been a laborious task, especially for highly interactive scenarios. On the other hand, algorithmic data generation methods are usually limited by their model capacities, making them unable to offer realistic and diverse data needed by various application users. In this work, we study trajectory-level data generation for multi-human or human-robot interaction scenarios and propose a learning-based automatic trajectory generation model, which we call Multi-Agent TRajectory generation with dIverse conteXts (MATRIX). MATRIX is capable of generating interactive human behaviors in realistic diverse contexts. We achieve this goal by modeling the explicit and interpretable objectives so that MATRIX can generate human motions based on diverse destinations and heterogeneous behaviors. We carried out extensive comparison and ablation studies to illustrate the effectiveness of our approach across various metrics. We also presented experiments that demonstrate the capability of MATRIX to serve as data augmentation for imitation-based motion planning.
Initializing Models with Larger Ones
Nov 30, 2023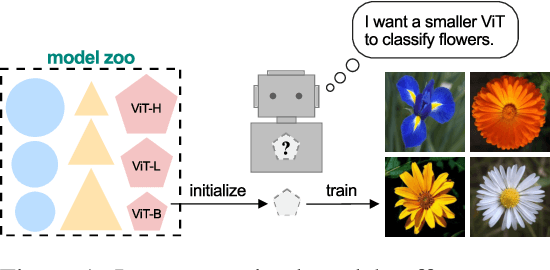



Weight initialization plays an important role in neural network training. Widely used initialization methods are proposed and evaluated for networks that are trained from scratch. However, the growing number of pretrained models now offers new opportunities for tackling this classical problem of weight initialization. In this work, we introduce weight selection, a method for initializing smaller models by selecting a subset of weights from a pretrained larger model. This enables the transfer of knowledge from pretrained weights to smaller models. Our experiments demonstrate that weight selection can significantly enhance the performance of small models and reduce their training time. Notably, it can also be used together with knowledge distillation. Weight selection offers a new approach to leverage the power of pretrained models in resource-constrained settings, and we hope it can be a useful tool for training small models in the large-model era. Code is available at https://github.com/OscarXZQ/weight-selection.
A Coefficient Makes SVRG Effective
Nov 09, 2023Stochastic Variance Reduced Gradient (SVRG), introduced by Johnson & Zhang (2013), is a theoretically compelling optimization method. However, as Defazio & Bottou (2019) highlights, its effectiveness in deep learning is yet to be proven. In this work, we demonstrate the potential of SVRG in optimizing real-world neural networks. Our analysis finds that, for deeper networks, the strength of the variance reduction term in SVRG should be smaller and decrease as training progresses. Inspired by this, we introduce a multiplicative coefficient $\alpha$ to control the strength and adjust it through a linear decay schedule. We name our method $\alpha$-SVRG. Our results show $\alpha$-SVRG better optimizes neural networks, consistently reducing training loss compared to both baseline and the standard SVRG across various architectures and image classification datasets. We hope our findings encourage further exploration into variance reduction techniques in deep learning. Code is available at https://github.com/davidyyd/alpha-SVRG.