 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Implicit Visual Reasoning
Dec 24, 2025While Large Multimodal Models (LMMs) have made significant progress, they remain largely text-centric, relying on language as their core reasoning modality. As a result, they are limited in their ability to handle reasoning tasks that are predominantly visual. Recent approaches have sought to address this by supervising intermediate visual steps with helper images, depth maps, or image crops. However, these strategies impose restrictive priors on what "useful" visual abstractions look like, add heavy annotation costs, and struggle to generalize across tasks. To address this critical limitation, we propose a task-agnostic mechanism that trains LMMs to discover and use visual reasoning tokens without explicit supervision. These tokens attend globally and re-encode the image in a task-adaptive way, enabling the model to extract relevant visual information without hand-crafted supervision. Our approach outperforms direct fine-tuning and achieves state-of-the-art results on a diverse range of vision-centric tasks -- including those where intermediate abstractions are hard to specify -- while also generalizing to multi-task instruction tuning.
DAVE: A VLM Vision Encoder for Document Understanding and Web Agents
Dec 19, 2025While Vision-language models (VLMs) have demonstrated remarkable performance across multi-modal tasks, their choice of vision encoders presents a fundamental weakness: their low-level features lack the robust structural and spatial information essential for document understanding and web agents. To bridge this gap, we introduce DAVE, a vision encoder purpose-built for VLMs and tailored for these tasks. Our training pipeline is designed to leverage abundant unlabeled data to bypass the need for costly large-scale annotations for document and web images. We begin with a self-supervised pretraining stage on unlabeled images, followed by a supervised autoregressive pretraining stage, where the model learns tasks like parsing and localization from limited, high-quality data. Within the supervised stage, we adopt two strategies to improve our encoder's alignment with both general visual knowledge and diverse document and web agentic tasks: (i) We introduce a novel model-merging scheme, combining encoders trained with different text decoders to ensure broad compatibility with different web agentic architectures. (ii) We use ensemble training to fuse features from pretrained generalist encoders (e.g., SigLIP2) with our own document and web-specific representations. Extensive experiments on classic document tasks, VQAs, web localization, and agent-based benchmarks validate the effectiveness of our approach, establishing DAVE as a strong vision encoder for document and web applications.
Activation Reward Models for Few-Shot Model Alignment
Jul 02, 2025Aligning Large Language Models (LLMs) and Large Multimodal Models (LMMs) to human preferences is a central challenge in improving the quality of the models' generative outputs for real-world applications. A common approach is to use reward modeling to encode preferences, enabling alignment via post-training using reinforcement learning. However, traditional reward modeling is not easily adaptable to new preferences because it requires a separate reward model, commonly trained on large preference datasets. To address this, we introduce Activation Reward Models (Activation RMs) -- a novel few-shot reward modeling method that leverages activation steering to construct well-aligned reward signals using minimal supervision and no additional model finetuning. Activation RMs outperform existing few-shot reward modeling approaches such as LLM-as-a-judge with in-context learning, voting-based scoring, and token probability scoring on standard reward modeling benchmarks. Furthermore, we demonstrate the effectiveness of Activation RMs in mitigating reward hacking behaviors, highlighting their utility for safety-critical applications. Toward this end, we propose PreferenceHack, a novel few-shot setting benchmark, the first to test reward models on reward hacking in a paired preference format. Finally, we show that Activation RM achieves state-of-the-art performance on this benchmark, surpassing even GPT-4o.
TULIP: Towards Unified Language-Image Pretraining
Mar 19, 2025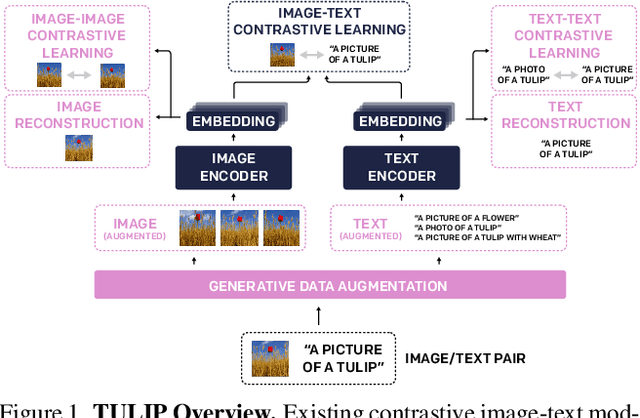
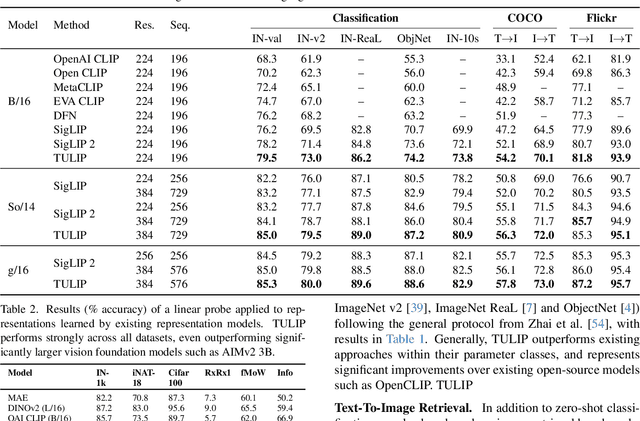
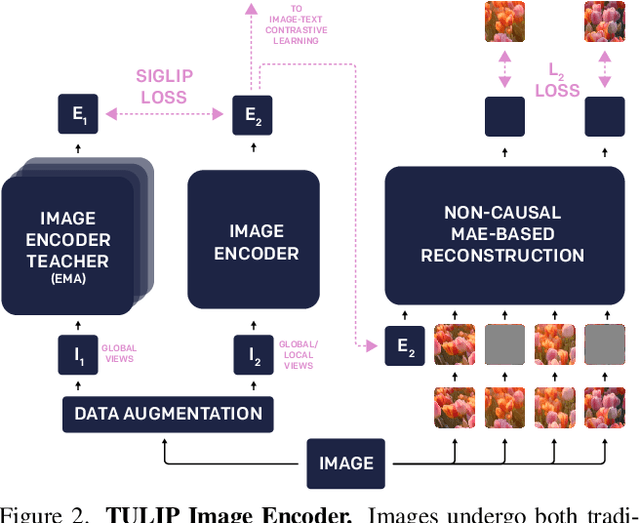
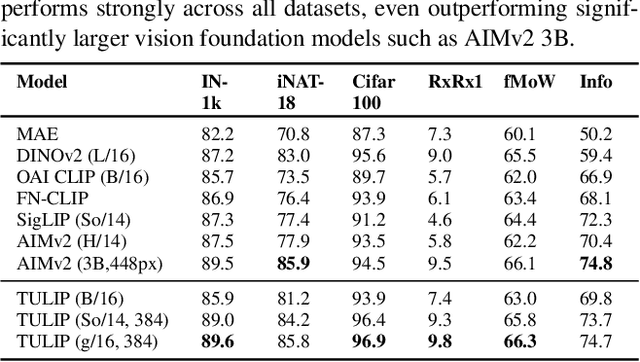
Despite the recent success of image-text contrastive models like CLIP and SigLIP, these models often struggle with vision-centric tasks that demand high-fidelity image understanding, such as counting, depth estimation, and fine-grained object recognition. These models, by performing language alignment, tend to prioritize high-level semantics over visual understanding, weakening their image understanding. On the other hand, vision-focused models are great at processing visual information but struggle to understand language, limiting their flexibility for language-driven tasks. In this work, we introduce TULIP, an open-source, drop-in replacement for existing CLIP-like models. Our method leverages generative data augmentation, enhanced image-image and text-text contrastive learning, and image/text reconstruction regularization to learn fine-grained visual features while preserving global semantic alignment. Our approach, scaling to over 1B parameters, outperforms existing state-of-the-art (SOTA) models across multiple benchmarks, establishing a new SOTA zero-shot performance on ImageNet-1K, delivering up to a $2\times$ enhancement over SigLIP on RxRx1 in linear probing for few-shot classification, and improving vision-language models, achieving over $3\times$ higher scores than SigLIP on MMVP. Our code/checkpoints are available at https://tulip-berkeley.github.io
Visualizing Thought: Conceptual Diagrams Enable Robust Planning in LMMs
Mar 14, 2025Human reasoning relies on constructing and manipulating mental models-simplified internal representations of situations that we use to understand and solve problems. Conceptual diagrams (for example, sketches drawn by humans to aid reasoning) externalize these mental models, abstracting irrelevant details to efficiently capture relational and spatial information. In contrast, Large Language Models (LLMs) and Large Multimodal Models (LMMs) predominantly reason through textual representations, limiting their effectiveness in complex multi-step combinatorial and planning tasks. In this paper, we propose a zero-shot fully automatic framework that enables LMMs to reason through multiple chains of self-generated intermediate conceptual diagrams, significantly enhancing their combinatorial planning capabilities. Our approach does not require any human initialization beyond a natural language description of the task. It integrates both textual and diagrammatic reasoning within an optimized graph-of-thought inference framework, enhanced by beam search and depth-wise backtracking. Evaluated on multiple challenging PDDL planning domains, our method substantially improves GPT-4o's performance (for example, from 35.5% to 90.2% in Blocksworld). On more difficult planning domains with solution depths up to 40, our approach outperforms even the o1-preview reasoning model (for example, over 13% improvement in Parking). These results highlight the value of conceptual diagrams as a complementary reasoning medium in LMMs.
Pre-training Auto-regressive Robotic Models with 4D Representations
Feb 18, 2025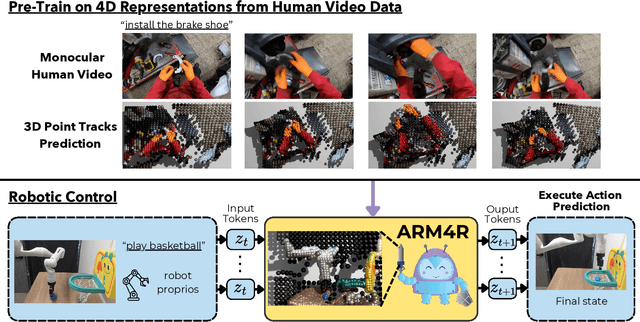
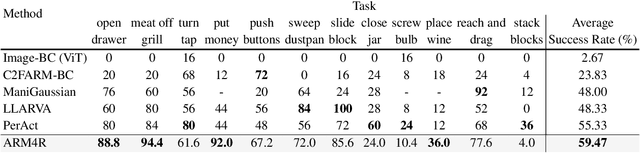
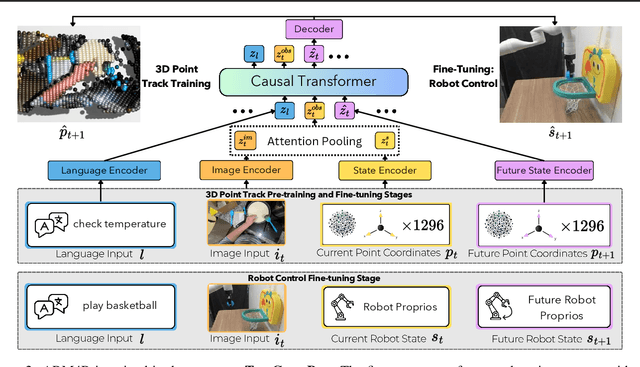
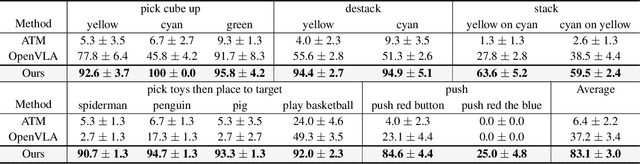
Foundation models pre-trained on massive unlabeled datasets have revolutionized natural language and computer vision, exhibiting remarkable generalization capabilities, thus highlighting the importance of pre-training. Yet, efforts in robotics have struggled to achieve similar success, limited by either the need for costly robotic annotations or the lack of representations that effectively model the physical world. In this paper, we introduce ARM4R, an Auto-regressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better pre-trained robotic model. Specifically, we focus on utilizing 3D point tracking representations from videos derived by lifting 2D representations into 3D space via monocular depth estimation across time. These 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, enabling efficient transfer learning from human video data to low-level robotic control. Our experiments show that ARM4R can transfer efficiently from human video data to robotics and consistently improves performance on tasks across various robot environments and configurations.
Sparse Attention Vectors: Generative Multimodal Model Features Are Discriminative Vision-Language Classifiers
Nov 28, 2024



Generative Large Multimodal Models (LMMs) like LLaVA and Qwen-VL excel at a wide variety of vision-language (VL) tasks such as image captioning or visual question answering. Despite strong performance, LMMs are not directly suited for foundational discriminative vision-language tasks (i.e., tasks requiring discrete label predictions) such as image classification and multiple-choice VQA. One key challenge in utilizing LMMs for discriminative tasks is the extraction of useful features from generative models. To overcome this issue, we propose an approach for finding features in the model's latent space to more effectively leverage LMMs for discriminative tasks. Toward this end, we present Sparse Attention Vectors (SAVs) -- a finetuning-free method that leverages sparse attention head activations (fewer than 1\% of the heads) in LMMs as strong features for VL tasks. With only few-shot examples, SAVs demonstrate state-of-the-art performance compared to a variety of few-shot and finetuned baselines on a collection of discriminative tasks. Our experiments also imply that SAVs can scale in performance with additional examples and generalize to similar tasks, establishing SAVs as both effective and robust multimodal feature representations.
In-Context Learning Enables Robot Action Prediction in LLMs
Oct 16, 2024Recently, Large Language Models (LLMs) have achieved remarkable success using in-context learning (ICL) in the language domain. However, leveraging the ICL capabilities within LLMs to directly predict robot actions remains largely unexplored. In this paper, we introduce RoboPrompt, a framework that enables off-the-shelf text-only LLMs to directly predict robot actions through ICL without training. Our approach first heuristically identifies keyframes that capture important moments from an episode. Next, we extract end-effector actions from these keyframes as well as the estimated initial object poses, and both are converted into textual descriptions. Finally, we construct a structured template to form ICL demonstrations from these textual descriptions and a task instruction. This enables an LLM to directly predict robot actions at test time. Through extensive experiments and analysis, RoboPrompt shows stronger performance over zero-shot and ICL baselines in simulated and real-world settings.
Multimodal Task Vectors Enable Many-Shot Multimodal In-Context Learning
Jun 21, 2024The recent success of interleaved Large Multimodal Models (LMMs) in few-shot learning suggests that in-context learning (ICL) with many examples can be promising for learning new tasks. However, this many-shot multimodal ICL setting has one crucial problem: it is fundamentally limited by the model's context length set at pretraining. The problem is especially prominent in the multimodal domain, which processes both text and images, requiring additional tokens. This motivates the need for a multimodal method to compress many shots into fewer tokens without finetuning. In this work, we enable LMMs to perform multimodal, many-shot in-context learning by leveraging Multimodal Task Vectors (MTV)--compact implicit representations of in-context examples compressed in the model's attention heads. Specifically, we first demonstrate the existence of such MTV in LMMs and then leverage these extracted MTV to enable many-shot in-context learning for various vision-and-language tasks. Our experiments suggest that MTV can scale in performance with the number of compressed shots and generalize to similar out-of-domain tasks without additional context length for inference.
Navigating the Labyrinth: Evaluating and Enhancing LLMs' Ability to Reason About Search Problems
Jun 18, 2024Recently, Large Language Models (LLMs) attained impressive performance in math and reasoning benchmarks. However, they still often struggle with logic problems and puzzles that are relatively easy for humans. To further investigate this, we introduce a new benchmark, SearchBench, containing 11 unique search problem types, each equipped with automated pipelines to generate an arbitrary number of instances and analyze the feasibility, correctness, and optimality of LLM-generated solutions. We show that even the most advanced LLMs fail to solve these problems end-to-end in text, e.g. GPT4 solves only 1.4%. SearchBench problems require considering multiple pathways to the solution as well as backtracking, posing a significant challenge to auto-regressive models. Instructing LLMs to generate code that solves the problem helps, but only slightly, e.g., GPT4's performance rises to 11.7%. In this work, we show that in-context learning with A* algorithm implementations enhances performance. The full potential of this promoting approach emerges when combined with our proposed Multi-Stage-Multi-Try method, which breaks down the algorithm implementation into two stages and verifies the first stage against unit tests, raising GPT-4's performance above 57%.