 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training Auto-regressive Robotic Models with 4D Representations
Feb 18, 2025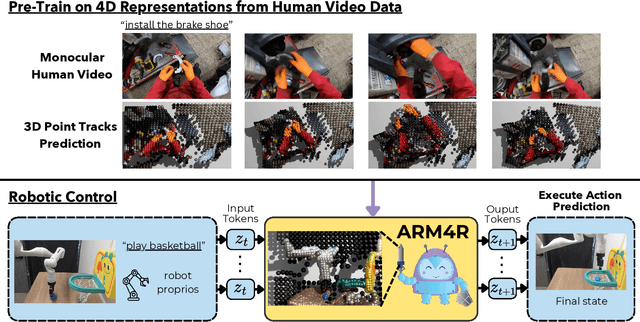
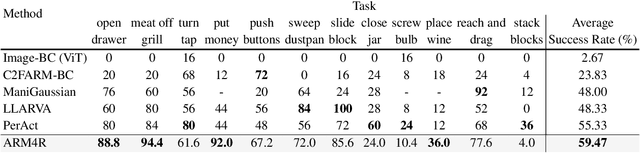
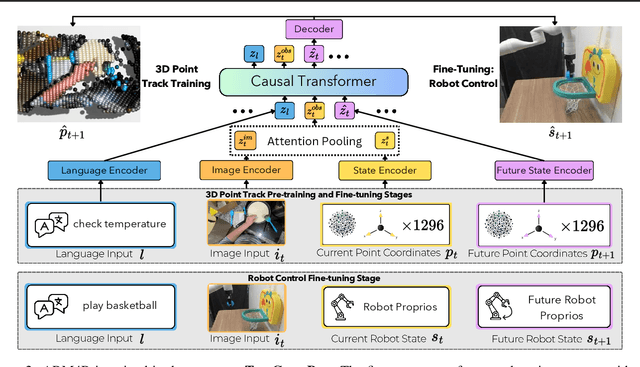
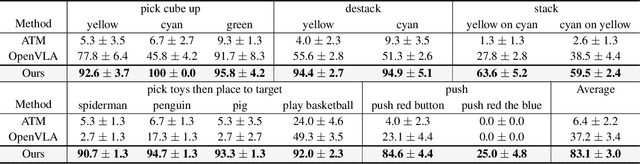
Foundation models pre-trained on massive unlabeled datasets have revolutionized natural language and computer vision, exhibiting remarkable generalization capabilities, thus highlighting the importance of pre-training. Yet, efforts in robotics have struggled to achieve similar success, limited by either the need for costly robotic annotations or the lack of representations that effectively model the physical world. In this paper, we introduce ARM4R, an Auto-regressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better pre-trained robotic model. Specifically, we focus on utilizing 3D point tracking representations from videos derived by lifting 2D representations into 3D space via monocular depth estimation across time. These 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, enabling efficient transfer learning from human video data to low-level robotic control. Our experiments show that ARM4R can transfer efficiently from human video data to robotics and consistently improves performance on tasks across various robot environments and configurations.
In-Context Learning Enables Robot Action Prediction in LLMs
Oct 16, 2024Recently, Large Language Models (LLMs) have achieved remarkable success using in-context learning (ICL) in the language domain. However, leveraging the ICL capabilities within LLMs to directly predict robot actions remains largely unexplored. In this paper, we introduce RoboPrompt, a framework that enables off-the-shelf text-only LLMs to directly predict robot actions through ICL without training. Our approach first heuristically identifies keyframes that capture important moments from an episode. Next, we extract end-effector actions from these keyframes as well as the estimated initial object poses, and both are converted into textual descriptions. Finally, we construct a structured template to form ICL demonstrations from these textual descriptions and a task instruction. This enables an LLM to directly predict robot actions at test time. Through extensive experiments and analysis, RoboPrompt shows stronger performance over zero-shot and ICL baselines in simulated and real-world settings.
LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning
Jun 17, 2024



In recent years, instruction-tuned Large Multimodal Models (LMMs) have been successful at several tasks, including image captioning and visual question answering; yet leveraging these models remains an open question for robotics. Prior LMMs for robotics applications have been extensively trained on language and action data, but their ability to generalize in different settings has often been less than desired. To address this, we introduce LLARVA, a model trained with a novel instruction tuning method that leverages structured prompts to unify a range of robotic learning tasks, scenarios, and environments. Additionally, we show that predicting intermediate 2-D representations, which we refer to as "visual traces", can help further align vision and action spaces for robot learning. We generate 8.5M image-visual trace pairs from the Open X-Embodiment dataset in order to pre-train our model, and we evaluate on 12 different tasks in the RLBench simulator as well as a physical Franka Emika Panda 7-DoF robot. Our experiments yield strong performance, demonstrating that LLARVA - using 2-D and language representations - performs well compared to several contemporary baselines, and can generalize across various robot environments and configurations.