 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-axis Analysis of Image Manipulation Localization
May 19, 2026Advanced image editing software enables easy creation of highly convincing image manipulations, which has been made even more accessible in recent years due to advances in generative AI. Manipulated images, while often harmless, could spread misinformation, create false narratives, and influence people's opinions on important issues. Despite this growing threat, there is limited research on detecting advanced manipulations across different visual domains. Thus, we introduce Analysis Under Domain-shifts, qualIty, Type, and Size (AUDITS), a comprehensive benchmark designed for studying axes of analysis in image manipulation detection. AUDITS comprises over 530K images from two distinct sources (user and news photos). We curate our dataset to support analysis across multiple axes using recent diffusion-based inpaintings, spanning a diverse range of manipulation types and sizes. We conduct experiments under different types of domain shift to evaluate robustness of existing image manipulation detection methods. Our goal is to drive further research in this area by offering new insights that would help develop more reliable and generalizable image manipulation detection methods.
Pre-training Auto-regressive Robotic Models with 4D Representations
Feb 18, 2025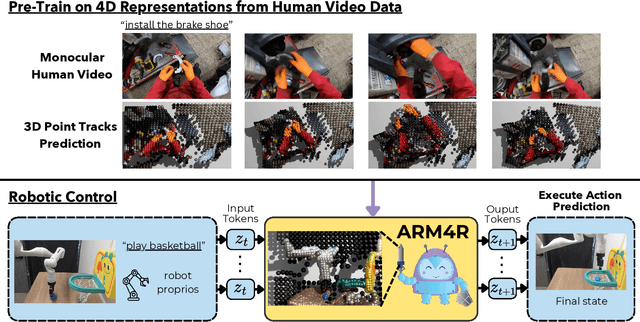
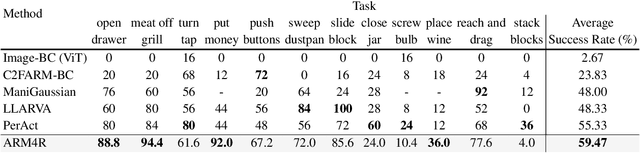
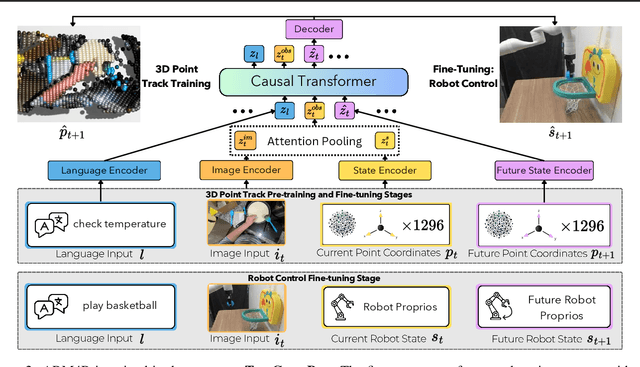
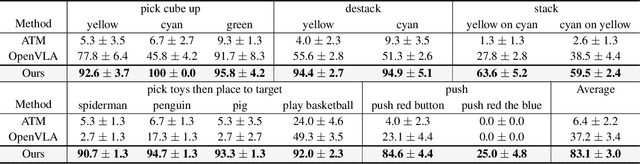
Foundation models pre-trained on massive unlabeled datasets have revolutionized natural language and computer vision, exhibiting remarkable generalization capabilities, thus highlighting the importance of pre-training. Yet, efforts in robotics have struggled to achieve similar success, limited by either the need for costly robotic annotations or the lack of representations that effectively model the physical world. In this paper, we introduce ARM4R, an Auto-regressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better pre-trained robotic model. Specifically, we focus on utilizing 3D point tracking representations from videos derived by lifting 2D representations into 3D space via monocular depth estimation across time. These 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, enabling efficient transfer learning from human video data to low-level robotic control. Our experiments show that ARM4R can transfer efficiently from human video data to robotics and consistently improves performance on tasks across various robot environments and configurations.
Visual Haystacks: Answering Harder Questions About Sets of Images
Jul 18, 2024



Recent advancements in Large Multimodal Models (LMMs) have made significant progress in the field of single-image visual question answering. However, these models face substantial challenges when tasked with queries that span extensive collections of images, similar to real-world scenarios like searching through large photo albums, finding specific information across the internet, or monitoring environmental changes through satellite imagery. This paper explores the task of Multi-Image Visual Question Answering (MIQA): given a large set of images and a natural language query, the task is to generate a relevant and grounded response. We propose a new public benchmark, dubbed "Visual Haystacks (VHs)," specifically designed to evaluate LMMs' capabilities in visual retrieval and reasoning over sets of unrelated images, where we perform comprehensive evaluations demonstrating that even robust closed-source models struggle significantly. Towards addressing these shortcomings, we introduce MIRAGE (Multi-Image Retrieval Augmented Generation), a novel retrieval/QA framework tailored for LMMs that confronts the challenges of MIQA with marked efficiency and accuracy improvements over baseline methods. Our evaluation shows that MIRAGE surpasses closed-source GPT-4o models by up to 11% on the VHs benchmark and offers up to 3.4x improvements in efficiency over text-focused multi-stage approaches.
LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning
Jun 17, 2024



In recent years, instruction-tuned Large Multimodal Models (LMMs) have been successful at several tasks, including image captioning and visual question answering; yet leveraging these models remains an open question for robotics. Prior LMMs for robotics applications have been extensively trained on language and action data, but their ability to generalize in different settings has often been less than desired. To address this, we introduce LLARVA, a model trained with a novel instruction tuning method that leverages structured prompts to unify a range of robotic learning tasks, scenarios, and environments. Additionally, we show that predicting intermediate 2-D representations, which we refer to as "visual traces", can help further align vision and action spaces for robot learning. We generate 8.5M image-visual trace pairs from the Open X-Embodiment dataset in order to pre-train our model, and we evaluate on 12 different tasks in the RLBench simulator as well as a physical Franka Emika Panda 7-DoF robot. Our experiments yield strong performance, demonstrating that LLARVA - using 2-D and language representations - performs well compared to several contemporary baselines, and can generalize across various robot environments and configurations.
See, Say, and Segment: Teaching LMMs to Overcome False Premises
Dec 13, 2023



Current open-source Large Multimodal Models (LMMs) excel at tasks such as open-vocabulary language grounding and segmentation but can suffer under false premises when queries imply the existence of something that is not actually present in the image. We observe that existing methods that fine-tune an LMM to segment images significantly degrade their ability to reliably determine ("see") if an object is present and to interact naturally with humans ("say"), a form of catastrophic forgetting. In this work, we propose a cascading and joint training approach for LMMs to solve this task, avoiding catastrophic forgetting of previous skills. Our resulting model can "see" by detecting whether objects are present in an image, "say" by telling the user if they are not, proposing alternative queries or correcting semantic errors in the query, and finally "segment" by outputting the mask of the desired objects if they exist. Additionally, we introduce a novel False Premise Correction benchmark dataset, an extension of existing RefCOCO(+/g) referring segmentation datasets (which we call FP-RefCOCO(+/g)). The results show that our method not only detects false premises up to 55% better than existing approaches, but under false premise conditions produces relative cIOU improvements of more than 31% over baselines, and produces natural language feedback judged helpful up to 67% of the time.
G^3: Geolocation via Guidebook Grounding
Nov 28, 2022



We demonstrate how language can improve geolocation: the task of predicting the location where an image was taken. Here we study explicit knowledge from human-written guidebooks that describe the salient and class-discriminative visual features humans use for geolocation. We propose the task of Geolocation via Guidebook Grounding that uses a dataset of StreetView images from a diverse set of locations and an associated textual guidebook for GeoGuessr, a popular interactive geolocation game. Our approach predicts a country for each image by attending over the clues automatically extracted from the guidebook. Supervising attention with country-level pseudo labels achieves the best performance. Our approach substantially outperforms a state-of-the-art image-only geolocation method, with an improvement of over 5% in Top-1 accuracy. Our dataset and code can be found at https://github.com/g-luo/geolocation_via_guidebook_grounding.
Twitter-COMMs: Detecting Climate, COVID, and Military Multimodal Misinformation
Dec 16, 2021



Detecting out-of-context media, such as "miscaptioned" images on Twitter, often requires detecting inconsistencies between the two modalities. This paper describes our approach to the Image-Text Inconsistency Detection challenge of the DARPA Semantic Forensics (SemaFor) Program. First, we collect Twitter-COMMs, a large-scale multimodal dataset with 884k tweets relevant to the topics of Climate Change, COVID-19, and Military Vehicles. We train our approach, based on the state-of-the-art CLIP model, leveraging automatically generated random and hard negatives. Our method is then tested on a hidden human-generated evaluation set. We achieve the best result on the program leaderboard, with 11% detection improvement in a high precision regime over a zero-shot CLIP baseline.
Region-level Active Learning for Cluttered Scenes
Aug 20, 2021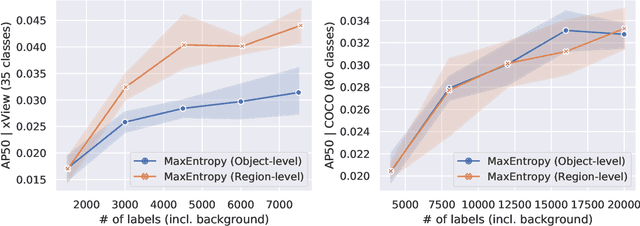
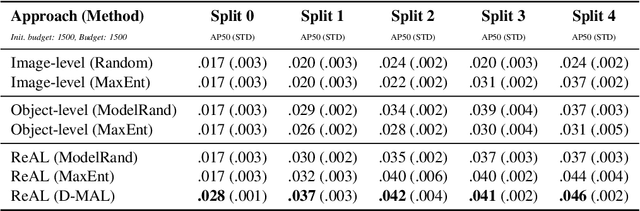
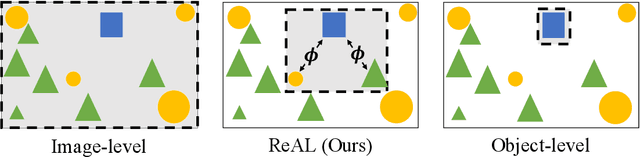
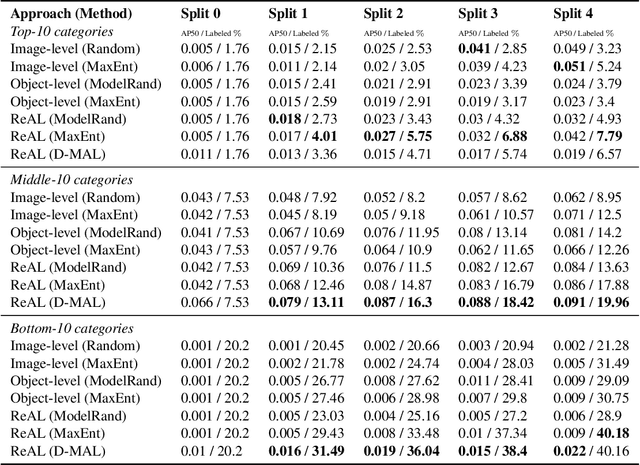
Active learning for object detection is conventionally achieved by applying techniques developed for classification in a way that aggregates individual detections into image-level selection criteria. This is typically coupled with the costly assumption that every image selected for labelling must be exhaustively annotated. This yields incremental improvements on well-curated vision datasets and struggles in the presence of data imbalance and visual clutter that occurs in real-world imagery. Alternatives to the image-level approach are surprisingly under-explored in the literature. In this work, we introduce a new strategy that subsumes previous Image-level and Object-level approaches into a generalized, Region-level approach that promotes spatial-diversity by avoiding nearby redundant queries from the same image and minimizes context-switching for the labeler. We show that this approach significantly decreases labeling effort and improves rare object search on realistic data with inherent class-imbalance and cluttered scenes.