 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Thinking Makes LLMs Stronger Reasoners
Nov 29, 2024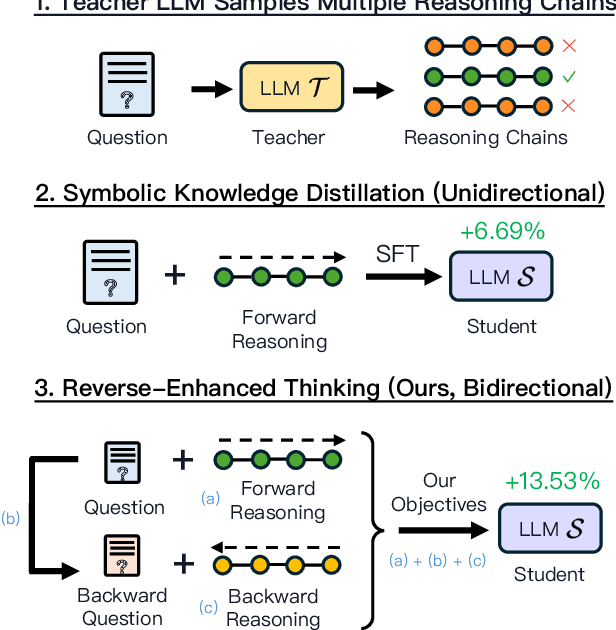
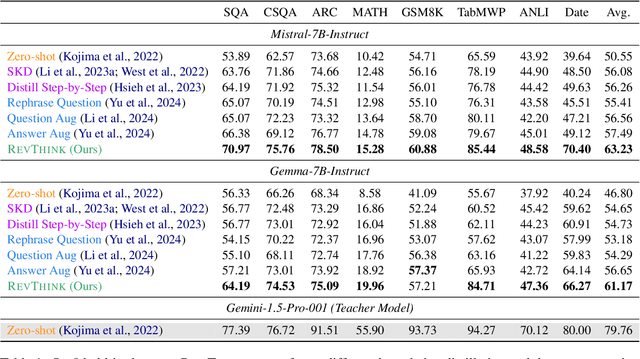
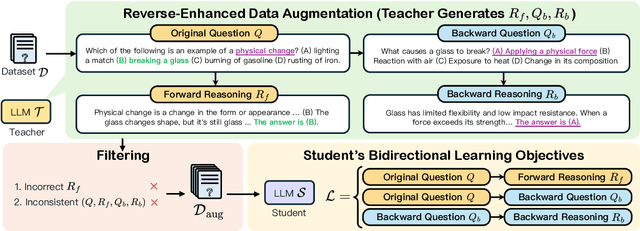
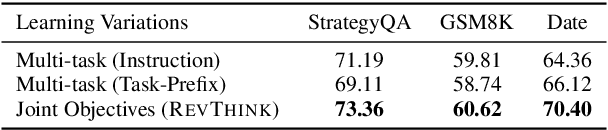
Reverse thinking plays a crucial role in human reasoning. Humans can reason not only from a problem to a solution but also in reverse, i.e., start from the solution and reason towards the problem. This often enhances overall reasoning performance as it enables consistency checks between their forward and backward thinking. To enable Large Language Models (LLMs) to perform reverse thinking, we introduce Reverse-Enhanced Thinking (RevThink), a framework composed of data augmentation and learning objectives. In RevThink, we augment the dataset by collecting structured forward-backward reasoning from a teacher model, consisting of: (1) the original question, (2) forward reasoning, (3) backward question, and (4) backward reasoning. We then employ three objectives to train a smaller student model in a multi-task learning fashion: (a) generate forward reasoning from a question, (b) generate a backward question from a question, and (c) generate backward reasoning from the backward question. Experiments across 12 datasets covering commonsense, math, and logical reasoning show an average 13.53% improvement over the student model's zero-shot performance and a 6.84% improvement over the strongest knowledge distillation baselines. Moreover, our method demonstrates sample efficiency -- using only 10% of the correct forward reasoning from the training data, it outperforms a standard fine-tuning method trained on 10x more forward reasoning. RevThink also exhibits strong generalization to out-of-distribution held-out datasets.
Model Swarms: Collaborative Search to Adapt LLM Experts via Swarm Intelligence
Oct 15, 2024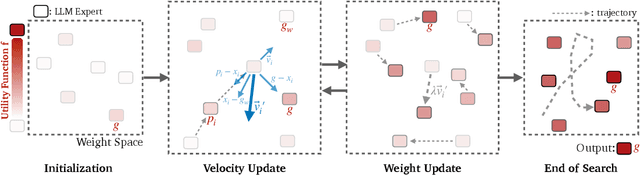
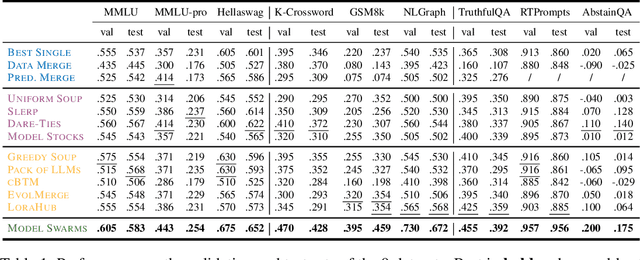
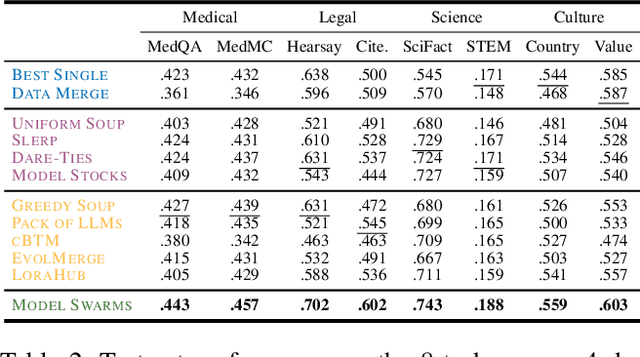
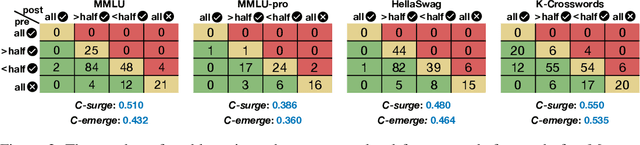
We propose Model Swarms, a collaborative search algorithm to adapt LLMs via swarm intelligence, the collective behavior guiding individual systems. Specifically, Model Swarms starts with a pool of LLM experts and a utility function. Guided by the best-found checkpoints across models, diverse LLM experts collaboratively move in the weight space and optimize a utility function representing model adaptation objectives. Compared to existing model composition approaches, Model Swarms offers tuning-free model adaptation, works in low-data regimes with as few as 200 examples, and does not require assumptions about specific experts in the swarm or how they should be composed. Extensive experiments demonstrate that Model Swarms could flexibly adapt LLM experts to a single task, multi-task domains, reward models, as well as diverse human interests, improving over 12 model composition baselines by up to 21.0% across tasks and contexts. Further analysis reveals that LLM experts discover previously unseen capabilities in initial checkpoints and that Model Swarms enable the weak-to-strong transition of experts through the collaborative search process.
CROME: Cross-Modal Adapters for Efficient Multimodal LLM
Aug 13, 2024Multimodal Large Language Models (MLLMs) demonstrate remarkable image-language capabilities, but their widespread use faces challenges in cost-effective training and adaptation. Existing approaches often necessitate expensive language model retraining and limited adaptability. Additionally, the current focus on zero-shot performance improvements offers insufficient guidance for task-specific tuning. We propose CROME, an efficient vision-language instruction tuning framework. It features a novel gated cross-modal adapter that effectively combines visual and textual representations prior to input into a frozen LLM. This lightweight adapter, trained with minimal parameters, enables efficient cross-modal understanding. Notably, CROME demonstrates superior zero-shot performance on standard visual question answering and instruction-following benchmarks. Moreover, it yields fine-tuning with exceptional parameter efficiency, competing with task-specific specialist state-of-the-art methods. CROME demonstrates the potential of pre-LM alignment for building scalable, adaptable, and parameter-efficient multimodal models.
Mitigating Object Hallucination via Data Augmented Contrastive Tuning
May 28, 2024Despite their remarkable progress, Multimodal Large Language Models (MLLMs) tend to hallucinate factually inaccurate information. In this work, we address object hallucinations in MLLMs, where information is offered about an object that is not present in the model input. We introduce a contrastive tuning method that can be applied to a pretrained off-the-shelf MLLM for mitigating hallucinations while preserving its general vision-language capabilities. For a given factual token, we create a hallucinated token through generative data augmentation by selectively altering the ground-truth information. The proposed contrastive tuning is applied at the token level to improve the relative likelihood of the factual token compared to the hallucinated one. Our thorough evaluation confirms the effectiveness of contrastive tuning in mitigating hallucination. Moreover, the proposed contrastive tuning is simple, fast, and requires minimal training with no additional overhead at inference.
TextGenSHAP: Scalable Post-hoc Explanations in Text Generation with Long Documents
Dec 03, 2023



Large language models (LLMs) have attracted huge interest in practical applications given their increasingly accurate responses and coherent reasoning abilities. Given their nature as black-boxes using complex reasoning processes on their inputs, it is inevitable that the demand for scalable and faithful explanations for LLMs' generated content will continue to grow. There have been major developments in the explainability of neural network models over the past decade. Among them, post-hoc explainability methods, especially Shapley values, have proven effective for interpreting deep learning models. However, there are major challenges in scaling up Shapley values for LLMs, particularly when dealing with long input contexts containing thousands of tokens and autoregressively generated output sequences. Furthermore, it is often unclear how to effectively utilize generated explanations to improve the performance of LLMs. In this paper, we introduce TextGenSHAP, an efficient post-hoc explanation method incorporating LM-specific techniques. We demonstrate that this leads to significant increases in speed compared to conventional Shapley value computations, reducing processing times from hours to minutes for token-level explanations, and to just seconds for document-level explanations. In addition, we demonstrate how real-time Shapley values can be utilized in two important scenarios, providing better understanding of long-document question answering by localizing important words and sentences; and improving existing document retrieval systems through enhancing the accuracy of selected passages and ultimately the final responses.
Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs
Oct 18, 2023Large language models (LLMs) have recently shown great advances in a variety of tasks, including natural language understanding and generation. However, their use in high-stakes decision-making scenarios is still limited due to the potential for errors. Selective prediction is a technique that can be used to improve the reliability of the LLMs by allowing them to abstain from making predictions when they are unsure of the answer. In this work, we propose a novel framework for adaptation with self-evaluation to improve the selective prediction performance of LLMs. Our framework is based on the idea of using parameter-efficient tuning to adapt the LLM to the specific task at hand while improving its ability to perform self-evaluation. We evaluate our method on a variety of question-answering (QA) datasets and show that it outperforms state-of-the-art selective prediction methods. For example, on the CoQA benchmark, our method improves the AUACC from 91.23% to 92.63% and improves the AUROC from 74.61% to 80.25%.
PAITS: Pretraining and Augmentation for Irregularly-Sampled Time Series
Aug 25, 2023



Real-world time series data that commonly reflect sequential human behavior are often uniquely irregularly sampled and sparse, with highly nonuniform sampling over time and entities. Yet, commonly-used pretraining and augmentation methods for time series are not specifically designed for such scenarios. In this paper, we present PAITS (Pretraining and Augmentation for Irregularly-sampled Time Series), a framework for identifying suitable pretraining strategies for sparse and irregularly sampled time series datasets. PAITS leverages a novel combination of NLP-inspired pretraining tasks and augmentations, and a random search to identify an effective strategy for a given dataset. We demonstrate that different datasets benefit from different pretraining choices. Compared with prior methods, our approach is better able to consistently improve pretraining across multiple datasets and domains. Our code is available at \url{https://github.com/google-research/google-research/tree/master/irregular_timeseries_pretraining}.
LANISTR: Multimodal Learning from Structured and Unstructured Data
May 26, 2023



Multimodal large-scale pretraining has shown impressive performance gains for unstructured data including language, image, audio, and video. Yet, the scenario most prominent in real-world applications is the existence of combination of structured (including tabular and time-series) and unstructured data, and this has so far been understudied. Towards this end, we propose LANISTR, a novel attention-based framework to learn from LANguage, Image, and STRuctured data. We introduce a new multimodal fusion module with a similarity-based multimodal masking loss that enables LANISTR to learn cross-modal relations from large-scale multimodal data with missing modalities during training and test time. On two publicly available challenging datasets, MIMIC-IV and Amazon Product Review, LANISTR achieves absolute improvements of 6.47% (AUROC) and up to 17.69% (accuracy), respectively, compared to the state-of-the-art multimodal models while showing superior generalization capabilities.
ASPEST: Bridging the Gap Between Active Learning and Selective Prediction
Apr 07, 2023Selective prediction aims to learn a reliable model that abstains from making predictions when the model uncertainty is high. These predictions can then be deferred to a human expert for further evaluation. In many real-world scenarios, however, the distribution of test data is different from the training data. This results in more inaccurate predictions, necessitating increased human labeling, which is difficult and expensive in many scenarios. Active learning circumvents this difficulty by only querying the most informative examples and, in several cases, has been shown to lower the overall labeling effort. In this work, we bridge the gap between selective prediction and active learning, proposing a new learning paradigm called active selective prediction which learns to query more informative samples from the shifted target domain while increasing accuracy and coverage. For this new problem, we propose a simple but effective solution, ASPEST, that trains ensembles of model snapshots using self-training with their aggregated outputs as pseudo labels. Extensive experiments on several image, text and structured datasets with domain shifts demonstrate that active selective prediction can significantly outperform prior work on selective prediction and active learning (e.g. on the MNIST$\to$SVHN benchmark with the labeling budget of 100, ASPEST improves the AUC metric from 79.36% to 88.84%) and achieves more optimal utilization of humans in the loop.
Beyond Invariance: Test-Time Label-Shift Adaptation for Distributions with "Spurious" Correlations
Nov 28, 2022Spurious correlations, or correlations that change across domains where a model can be deployed, present significant challenges to real-world applications of machine learning models. However, such correlations are not always "spurious"; often, they provide valuable prior information for a prediction beyond what can be extracted from the input alone. Here, we present a test-time adaptation method that exploits the spurious correlation phenomenon, in contrast to recent approaches that attempt to eliminate spurious correlations through invariance. We consider situations where the prior distribution $p(y, z)$, which models the marginal dependence between the class label $y$ and the nuisance factors $z$, may change across domains, but the generative model for features $p(\mathbf{x}|y, z)$ is constant. We note that this is an expanded version of the label shift assumption, where the labels now also include the nuisance factors $z$. Based on this observation, we train a classifier to predict $p(y, z|\mathbf{x})$ on the source distribution, and implement a test-time label shift correction that adapts to changes in the marginal distribution $p(y, z)$ using unlabeled samples from the target domain. We call our method "Test-Time Label-Shift Adaptation" or TTLSA. We apply our method to two different image datasets -- the CheXpert chest X-ray dataset and the colored MNIST dataset -- and show that it gives better downstream results than methods that try to train classifiers which are invariant to the changes in prior distribution. Code reproducing experiments is available at https://github.com/nalzok/test-time-label-shift .