 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapTrace: Scalable Data Generation for Route Tracing on Maps
Dec 22, 2025While Multimodal Large Language Models have achieved human-like performance on many visual and textual reasoning tasks, their proficiency in fine-grained spatial understanding, such as route tracing on maps remains limited. Unlike humans, who can quickly learn to parse and navigate maps, current models often fail to respect fundamental path constraints, in part due to the prohibitive cost and difficulty of collecting large-scale, pixel-accurate path annotations. To address this, we introduce a scalable synthetic data generation pipeline that leverages synthetic map images and pixel-level parsing to automatically produce precise annotations for this challenging task. Using this pipeline, we construct a fine-tuning dataset of 23k path samples across 4k maps, enabling models to acquire more human-like spatial capabilities. Using this dataset, we fine-tune both open-source and proprietary MLLMs. Results on MapBench show that finetuning substantially improves robustness, raising success rates by up to 6.4 points, while also reducing path-tracing error (NDTW). These gains highlight that fine-grained spatial reasoning, absent in pretrained models, can be explicitly taught with synthetic supervision.
Steerable Chatbots: Personalizing LLMs with Preference-Based Activation Steering
May 07, 2025As large language models (LLMs) improve in their capacity to serve as personal AI assistants, their ability to output uniquely tailored, personalized responses that align with the soft preferences of their users is essential for enhancing user satisfaction and retention. However, untrained lay users have poor prompt specification abilities and often struggle with conveying their latent preferences to AI assistants. To address this, we leverage activation steering to guide LLMs to align with interpretable preference dimensions during inference. In contrast to memory-based personalization methods that require longer user history, steering is extremely lightweight and can be easily controlled by the user via an linear strength factor. We embed steering into three different interactive chatbot interfaces and conduct a within-subjects user study (n=14) to investigate how end users prefer to personalize their conversations. The results demonstrate the effectiveness of preference-based steering for aligning real-world conversations with hidden user preferences, and highlight further insights on how diverse values around control, usability, and transparency lead users to prefer different interfaces.
Omnia de EgoTempo: Benchmarking Temporal Understanding of Multi-Modal LLMs in Egocentric Videos
Mar 17, 2025Understanding fine-grained temporal dynamics is crucial in egocentric videos, where continuous streams capture frequent, close-up interactions with objects. In this work, we bring to light that current egocentric video question-answering datasets often include questions that can be answered using only few frames or commonsense reasoning, without being necessarily grounded in the actual video. Our analysis shows that state-of-the-art Multi-Modal Large Language Models (MLLMs) on these benchmarks achieve remarkably high performance using just text or a single frame as input. To address these limitations, we introduce EgoTempo, a dataset specifically designed to evaluate temporal understanding in the egocentric domain. EgoTempo emphasizes tasks that require integrating information across the entire video, ensuring that models would need to rely on temporal patterns rather than static cues or pre-existing knowledge. Extensive experiments on EgoTempo show that current MLLMs still fall short in temporal reasoning on egocentric videos, and thus we hope EgoTempo will catalyze new research in the field and inspire models that better capture the complexity of temporal dynamics. Dataset and code are available at https://github.com/google-research-datasets/egotempo.git.
I Know What I Don't Know: Improving Model Cascades Through Confidence Tuning
Feb 26, 2025Large-scale machine learning models deliver strong performance across a wide range of tasks but come with significant computational and resource constraints. To mitigate these challenges, local smaller models are often deployed alongside larger models, relying on routing and deferral mechanisms to offload complex tasks. However, existing approaches inadequately balance the capabilities of these models, often resulting in unnecessary deferrals or sub-optimal resource usage. In this work we introduce a novel loss function called Gatekeeper for calibrating smaller models in cascade setups. Our approach fine-tunes the smaller model to confidently handle tasks it can perform correctly while deferring complex tasks to the larger model. Moreover, it incorporates a mechanism for managing the trade-off between model performance and deferral accuracy, and is broadly applicable across various tasks and domains without any architectural changes. We evaluate our method on encoder-only, decoder-only, and encoder-decoder architectures. Experiments across image classification, language modeling, and vision-language tasks show that our approach substantially improves deferral performance.
Model Swarms: Collaborative Search to Adapt LLM Experts via Swarm Intelligence
Oct 15, 2024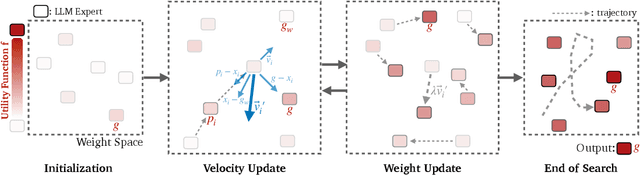
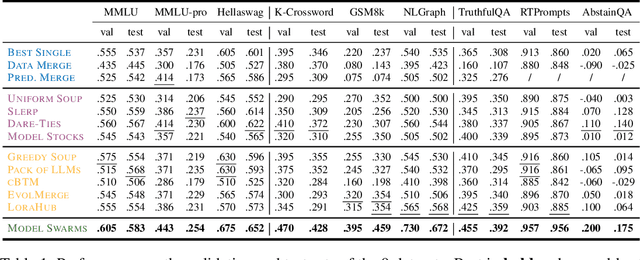
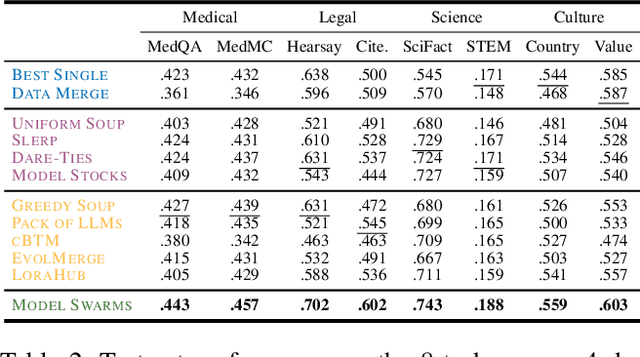
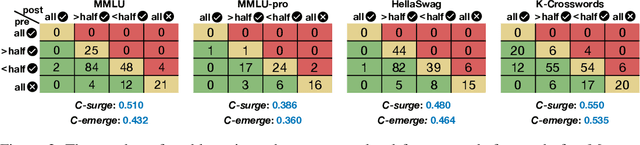
We propose Model Swarms, a collaborative search algorithm to adapt LLMs via swarm intelligence, the collective behavior guiding individual systems. Specifically, Model Swarms starts with a pool of LLM experts and a utility function. Guided by the best-found checkpoints across models, diverse LLM experts collaboratively move in the weight space and optimize a utility function representing model adaptation objectives. Compared to existing model composition approaches, Model Swarms offers tuning-free model adaptation, works in low-data regimes with as few as 200 examples, and does not require assumptions about specific experts in the swarm or how they should be composed. Extensive experiments demonstrate that Model Swarms could flexibly adapt LLM experts to a single task, multi-task domains, reward models, as well as diverse human interests, improving over 12 model composition baselines by up to 21.0% across tasks and contexts. Further analysis reveals that LLM experts discover previously unseen capabilities in initial checkpoints and that Model Swarms enable the weak-to-strong transition of experts through the collaborative search process.
BRAVE: Broadening the visual encoding of vision-language models
Apr 10, 2024Vision-language models (VLMs) are typically composed of a vision encoder, e.g. CLIP, and a language model (LM) that interprets the encoded features to solve downstream tasks. Despite remarkable progress, VLMs are subject to several shortcomings due to the limited capabilities of vision encoders, e.g. "blindness" to certain image features, visual hallucination, etc. To address these issues, we study broadening the visual encoding capabilities of VLMs. We first comprehensively benchmark several vision encoders with different inductive biases for solving VLM tasks. We observe that there is no single encoding configuration that consistently achieves top performance across different tasks, and encoders with different biases can perform surprisingly similarly. Motivated by this, we introduce a method, named BRAVE, that consolidates features from multiple frozen encoders into a more versatile representation that can be directly fed as the input to a frozen LM. BRAVE achieves state-of-the-art performance on a broad range of captioning and VQA benchmarks and significantly reduces the aforementioned issues of VLMs, while requiring a smaller number of trainable parameters than existing methods and having a more compressed representation. Our results highlight the potential of incorporating different visual biases for a more broad and contextualized visual understanding of VLMs.