 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINER: MLLMs Hallucinate under Fine-grained Negative Queries
Mar 18, 2026Multimodal large language models (MLLMs) struggle with hallucinations, particularly with fine-grained queries, a challenge underrepresented by existing benchmarks that focus on coarse image-related questions. We introduce FIne-grained NEgative queRies (FINER), alongside two benchmarks: FINER-CompreCap and FINER-DOCCI. Using FINER, we analyze hallucinations across four settings: multi-object, multi-attribute, multi-relation, and ``what'' questions. Our benchmarks reveal that MLLMs hallucinate when fine-grained mismatches co-occur with genuinely present elements in the image. To address this, we propose FINER-Tuning, leveraging Direct Preference Optimization (DPO) on FINER-inspired data. Finetuning four frontier MLLMs with FINER-Tuning yields up to 24.2\% gains (InternVL3.5-14B) on hallucinations from our benchmarks, while simultaneously improving performance on eight existing hallucination suites, and enhancing general multimodal capabilities across six benchmarks. Code, benchmark, and models are available at \href{https://explainableml.github.io/finer-project/}{https://explainableml.github.io/finer-project/}.
Training-free Uncertainty Guidance for Complex Visual Tasks with MLLMs
Oct 01, 2025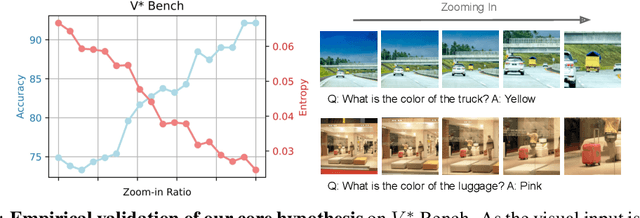
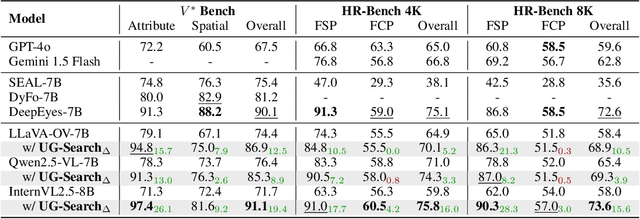
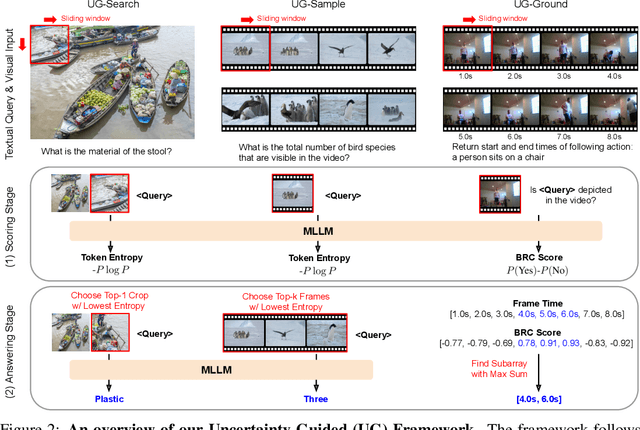
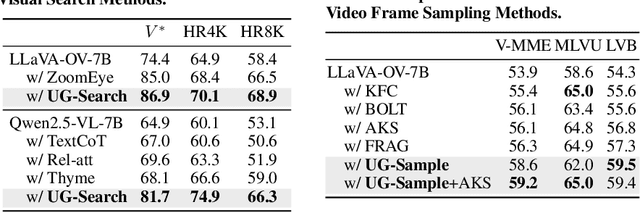
Multimodal Large Language Models (MLLMs) often struggle with fine-grained perception, such as identifying small objects in high-resolution images or finding key moments in long videos. Existing works typically rely on complicated, task-specific fine-tuning, which limits their generalizability and increases model complexity. In this work, we propose an effective, training-free framework that uses an MLLM's intrinsic uncertainty as a proactive guidance signal. Our core insight is that a model's output entropy decreases when presented with relevant visual information. We introduce a unified mechanism that scores candidate visual inputs by response uncertainty, enabling the model to autonomously focus on the most salient data. We apply this simple principle to three complex visual tasks: Visual Search, Long Video Understanding, and Temporal Grounding, allowing off-the-shelf MLLMs to achieve performance competitive with specialized, fine-tuned methods. Our work validates that harnessing intrinsic uncertainty is a powerful, general strategy for enhancing fine-grained multimodal performance.
Omnia de EgoTempo: Benchmarking Temporal Understanding of Multi-Modal LLMs in Egocentric Videos
Mar 17, 2025

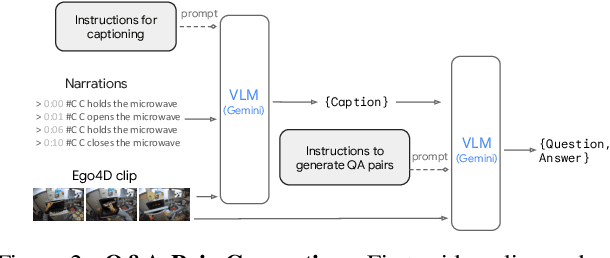
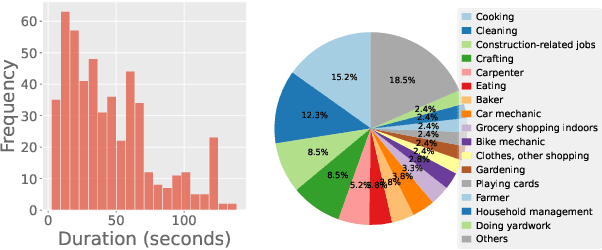
Understanding fine-grained temporal dynamics is crucial in egocentric videos, where continuous streams capture frequent, close-up interactions with objects. In this work, we bring to light that current egocentric video question-answering datasets often include questions that can be answered using only few frames or commonsense reasoning, without being necessarily grounded in the actual video. Our analysis shows that state-of-the-art Multi-Modal Large Language Models (MLLMs) on these benchmarks achieve remarkably high performance using just text or a single frame as input. To address these limitations, we introduce EgoTempo, a dataset specifically designed to evaluate temporal understanding in the egocentric domain. EgoTempo emphasizes tasks that require integrating information across the entire video, ensuring that models would need to rely on temporal patterns rather than static cues or pre-existing knowledge. Extensive experiments on EgoTempo show that current MLLMs still fall short in temporal reasoning on egocentric videos, and thus we hope EgoTempo will catalyze new research in the field and inspire models that better capture the complexity of temporal dynamics. Dataset and code are available at https://github.com/google-research-datasets/egotempo.git.
UIP2P: Unsupervised Instruction-based Image Editing via Cycle Edit Consistency
Dec 19, 2024



We propose an unsupervised model for instruction-based image editing that eliminates the need for ground-truth edited images during training. Existing supervised methods depend on datasets containing triplets of input image, edited image, and edit instruction. These are generated by either existing editing methods or human-annotations, which introduce biases and limit their generalization ability. Our method addresses these challenges by introducing a novel editing mechanism called Cycle Edit Consistency (CEC), which applies forward and backward edits in one training step and enforces consistency in image and attention spaces. This allows us to bypass the need for ground-truth edited images and unlock training for the first time on datasets comprising either real image-caption pairs or image-caption-edit triplets. We empirically show that our unsupervised technique performs better across a broader range of edits with high fidelity and precision. By eliminating the need for pre-existing datasets of triplets, reducing biases associated with supervised methods, and proposing CEC, our work represents a significant advancement in unblocking scaling of instruction-based image editing.
Active Data Curation Effectively Distills Large-Scale Multimodal Models
Nov 27, 2024Knowledge distillation (KD) is the de facto standard for compressing large-scale models into smaller ones. Prior works have explored ever more complex KD strategies involving different objective functions, teacher-ensembles, and weight inheritance. In this work we explore an alternative, yet simple approach -- active data curation as effective distillation for contrastive multimodal pretraining. Our simple online batch selection method, ACID, outperforms strong KD baselines across various model-, data- and compute-configurations. Further, we find such an active data curation strategy to in fact be complementary to standard KD, and can be effectively combined to train highly performant inference-efficient models. Our simple and scalable pretraining framework, ACED, achieves state-of-the-art results across 27 zero-shot classification and retrieval tasks with upto 11% less inference FLOPs. We further demonstrate that our ACED models yield strong vision-encoders for training generative multimodal models in the LiT-Decoder setting, outperforming larger vision encoders for image-captioning and visual question-answering tasks.
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
Oct 30, 2024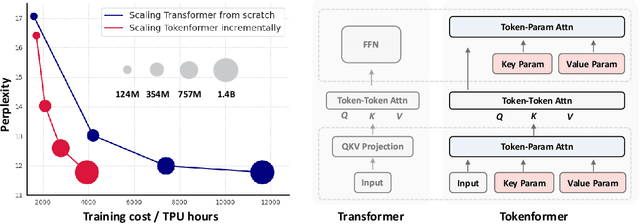
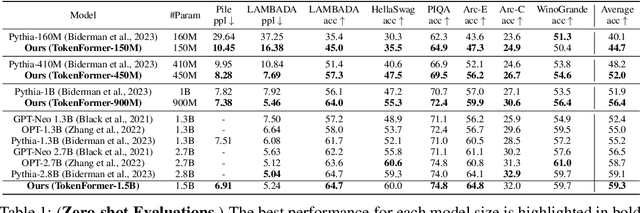
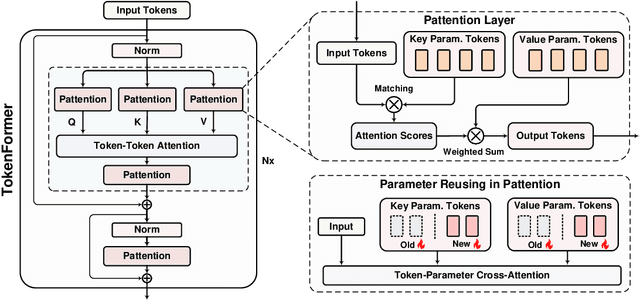
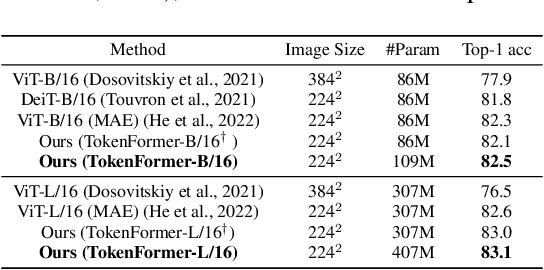
Transformers have become the predominant architecture in foundation models due to their excellent performance across various domains. However, the substantial cost of scaling these models remains a significant concern. This problem arises primarily from their dependence on a fixed number of parameters within linear projections. When architectural modifications (e.g., channel dimensions) are introduced, the entire model typically requires retraining from scratch. As model sizes continue growing, this strategy results in increasingly high computational costs and becomes unsustainable. To overcome this problem, we introduce TokenFormer, a natively scalable architecture that leverages the attention mechanism not only for computations among input tokens but also for interactions between tokens and model parameters, thereby enhancing architectural flexibility. By treating model parameters as tokens, we replace all the linear projections in Transformers with our token-parameter attention layer, where input tokens act as queries and model parameters as keys and values. This reformulation allows for progressive and efficient scaling without necessitating retraining from scratch. Our model scales from 124M to 1.4B parameters by incrementally adding new key-value parameter pairs, achieving performance comparable to Transformers trained from scratch while greatly reducing training costs. Code and models are available at \url{https://github.com/Haiyang-W/TokenFormer}.
Toward a Diffusion-Based Generalist for Dense Vision Tasks
Jun 29, 2024



Building generalized models that can solve many computer vision tasks simultaneously is an intriguing direction. Recent works have shown image itself can be used as a natural interface for general-purpose visual perception and demonstrated inspiring results. In this paper, we explore diffusion-based vision generalists, where we unify different types of dense prediction tasks as conditional image generation and re-purpose pre-trained diffusion models for it. However, directly applying off-the-shelf latent diffusion models leads to a quantization issue. Thus, we propose to perform diffusion in pixel space and provide a recipe for finetuning pre-trained text-to-image diffusion models for dense vision tasks. In experiments, we evaluate our method on four different types of tasks and show competitive performance to the other vision generalists.
LocCa: Visual Pretraining with Location-aware Captioners
Mar 28, 2024



Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area with limited research. In this paper, we propose a simple visual pretraining method with location-aware captioners (LocCa). LocCa uses a simple image captioner task interface, to teach a model to read out rich information, i.e. bounding box coordinates, and captions, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can easily handle multiple tasks during pretraining. Our experiments demonstrate that LocCa outperforms standard captioners significantly on localization downstream tasks while maintaining comparable performance on holistic tasks.
Text-Conditioned Resampler For Long Form Video Understanding
Dec 19, 2023



Videos are highly redundant data source and it is often enough to identify a few key moments to solve any given task. In this paper, we present a text-conditioned video resampler (TCR) module that uses a pre-trained and frozen visual encoder and large language model (LLM) to process long video sequences for a task. TCR localises relevant visual features from the video given a text condition and provides them to a LLM to generate a text response. Due to its lightweight design and use of cross-attention, TCR can process more than 100 frames at a time allowing the model to use much longer chunks of video than earlier works. We make the following contributions: (i) we design a transformer-based sampling architecture that can process long videos conditioned on a task, together with a training method that enables it to bridge pre-trained visual and language models; (ii) we empirically validate its efficacy on a wide variety of evaluation tasks, and set a new state-of-the-art on NextQA, EgoSchema, and the EGO4D-LTA challenge; and (iii) we determine tasks which require longer video contexts and that can thus be used effectively for further evaluation of long-range video models.
LIME: Localized Image Editing via Attention Regularization in Diffusion Models
Dec 14, 2023



Diffusion models (DMs) have gained prominence due to their ability to generate high-quality, varied images, with recent advancements in text-to-image generation. The research focus is now shifting towards the controllability of DMs. A significant challenge within this domain is localized editing, where specific areas of an image are modified without affecting the rest of the content. This paper introduces LIME for localized image editing in diffusion models that do not require user-specified regions of interest (RoI) or additional text input. Our method employs features from pre-trained methods and a simple clustering technique to obtain precise semantic segmentation maps. Then, by leveraging cross-attention maps, it refines these segments for localized edits. Finally, we propose a novel cross-attention regularization technique that penalizes unrelated cross-attention scores in the RoI during the denoising steps, ensuring localized edits. Our approach, without re-training and fine-tuning, consistently improves the performance of existing methods in various editing benchmarks.