 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Feb 20, 2025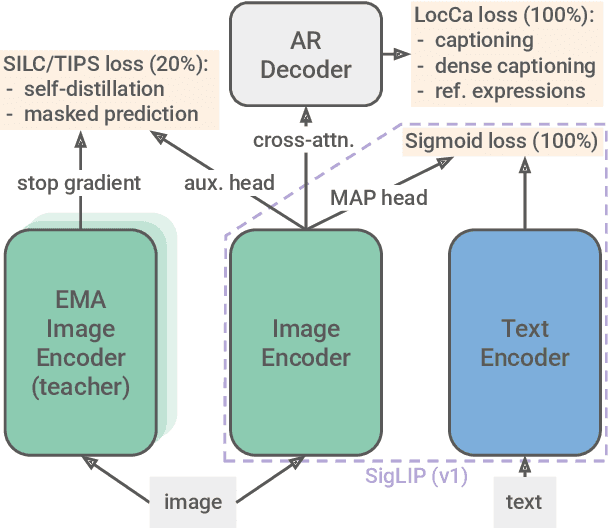
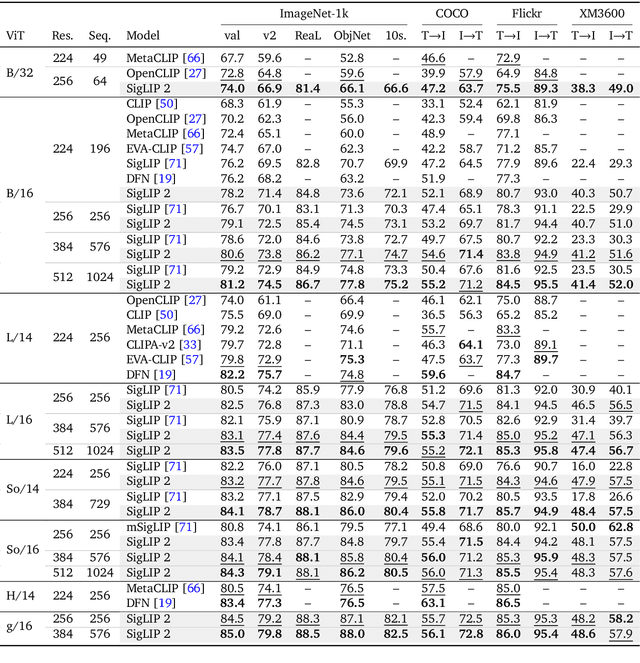
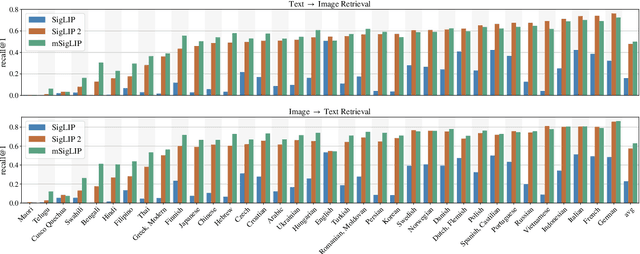
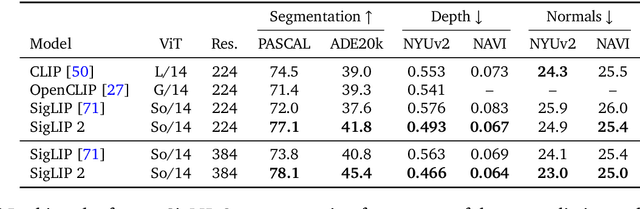
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
Active Data Curation Effectively Distills Large-Scale Multimodal Models
Nov 27, 2024Knowledge distillation (KD) is the de facto standard for compressing large-scale models into smaller ones. Prior works have explored ever more complex KD strategies involving different objective functions, teacher-ensembles, and weight inheritance. In this work we explore an alternative, yet simple approach -- active data curation as effective distillation for contrastive multimodal pretraining. Our simple online batch selection method, ACID, outperforms strong KD baselines across various model-, data- and compute-configurations. Further, we find such an active data curation strategy to in fact be complementary to standard KD, and can be effectively combined to train highly performant inference-efficient models. Our simple and scalable pretraining framework, ACED, achieves state-of-the-art results across 27 zero-shot classification and retrieval tasks with upto 11% less inference FLOPs. We further demonstrate that our ACED models yield strong vision-encoders for training generative multimodal models in the LiT-Decoder setting, outperforming larger vision encoders for image-captioning and visual question-answering tasks.
Data curation via joint example selection further accelerates multimodal learning
Jun 25, 2024



Data curation is an essential component of large-scale pretraining. In this work, we demonstrate that jointly selecting batches of data is more effective for learning than selecting examples independently. Multimodal contrastive objectives expose the dependencies between data and thus naturally yield criteria for measuring the joint learnability of a batch. We derive a simple and tractable algorithm for selecting such batches, which significantly accelerate training beyond individually-prioritized data points. As performance improves by selecting from larger super-batches, we also leverage recent advances in model approximation to reduce the associated computational overhead. As a result, our approach--multimodal contrastive learning with joint example selection (JEST)--surpasses state-of-the-art models with up to 13$\times$ fewer iterations and 10$\times$ less computation. Essential to the performance of JEST is the ability to steer the data selection process towards the distribution of smaller, well-curated datasets via pretrained reference models, exposing the level of data curation as a new dimension for neural scaling laws.
Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding
Dec 12, 2023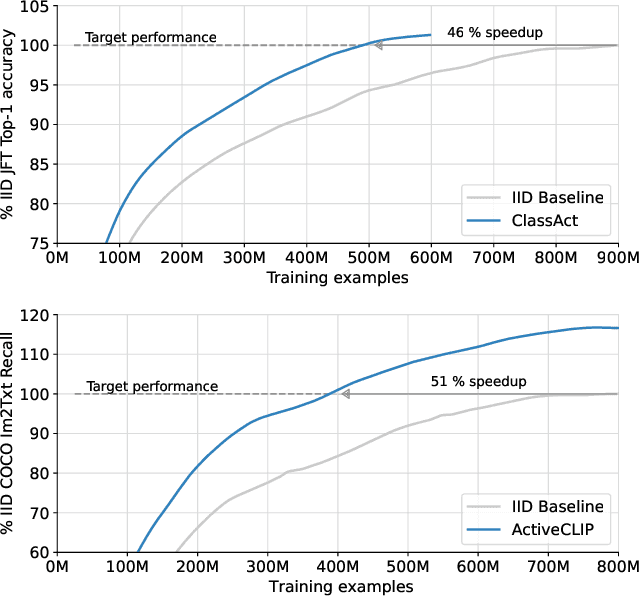



We propose a method for accelerating large-scale pre-training with online data selection policies. For the first time, we demonstrate that model-based data selection can reduce the total computation needed to reach the performance of models trained with uniform sampling. The key insight which enables this "compute-positive" regime is that small models provide good proxies for the loss of much larger models, such that computation spent on scoring data can be drastically scaled down but still significantly accelerate training of the learner.. These data selection policies also strongly generalize across datasets and tasks, opening an avenue for further amortizing the overhead of data scoring by re-using off-the-shelf models and training sequences. Our methods, ClassAct and ActiveCLIP, require 46% and 51% fewer training updates and up to 25% less total computation when training visual classifiers on JFT and multimodal models on ALIGN, respectively. Finally, our paradigm seamlessly applies to the curation of large-scale image-text datasets, yielding a new state-of-the-art in several multimodal transfer tasks and pre-training regimes.
Incremental Abstraction in Distributed Probabilistic SLAM Graphs
Sep 13, 2021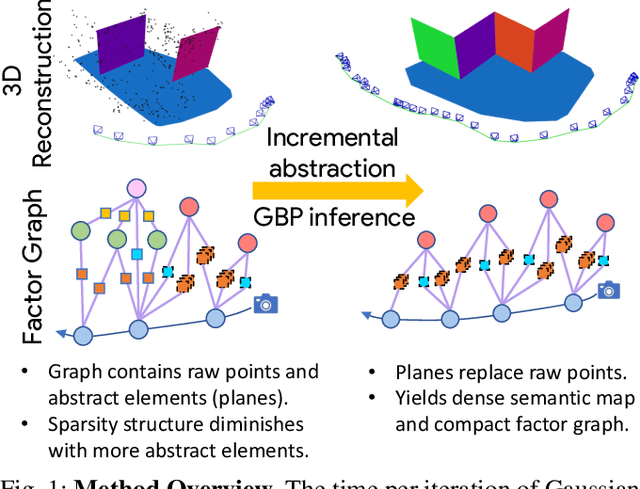
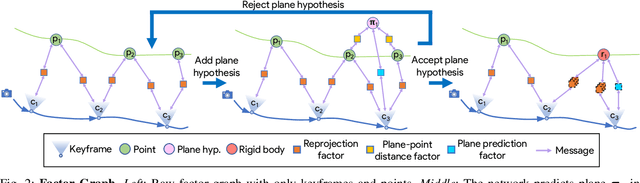
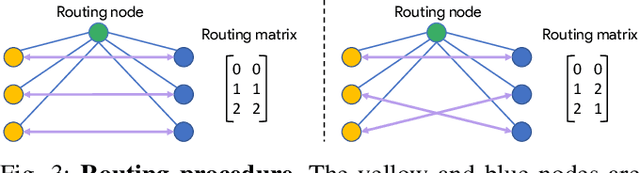
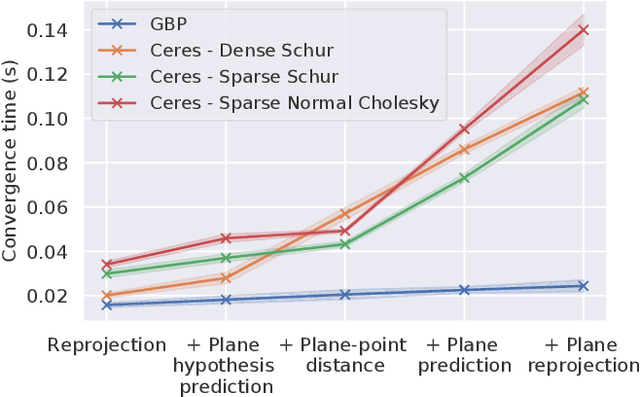
Scene graphs represent the key components of a scene in a compact and semantically rich way, but are difficult to build during incremental SLAM operation because of the challenges of robustly identifying abstract scene elements and optimising continually changing, complex graphs. We present a distributed, graph-based SLAM framework for incrementally building scene graphs based on two novel components. First, we propose an incremental abstraction framework in which a neural network proposes abstract scene elements that are incorporated into the factor graph of a feature-based monocular SLAM system. Scene elements are confirmed or rejected through optimisation and incrementally replace the points yielding a more dense, semantic and compact representation. Second, enabled by our novel routing procedure, we use Gaussian Belief Propagation (GBP) for distributed inference on a graph processor. The time per iteration of GBP is structure-agnostic and we demonstrate the speed advantages over direct methods for inference of heterogeneous factor graphs. We run our system on real indoor datasets using planar abstractions and recover the major planes with significant compression.
A visual introduction to Gaussian Belief Propagation
Jul 05, 2021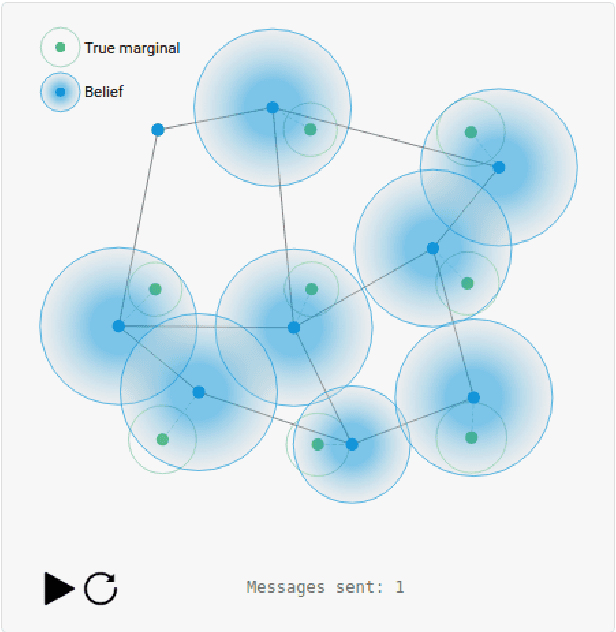
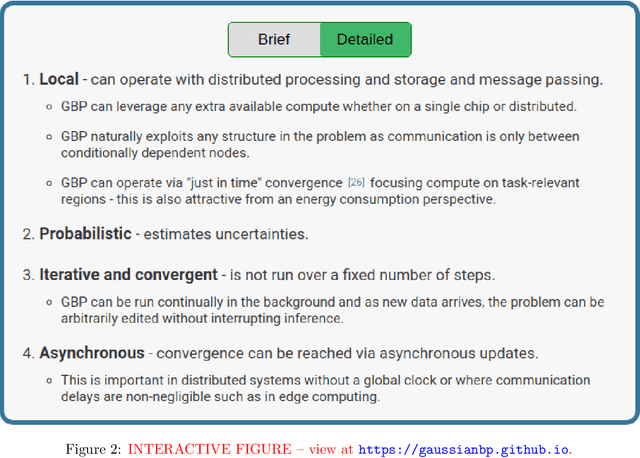

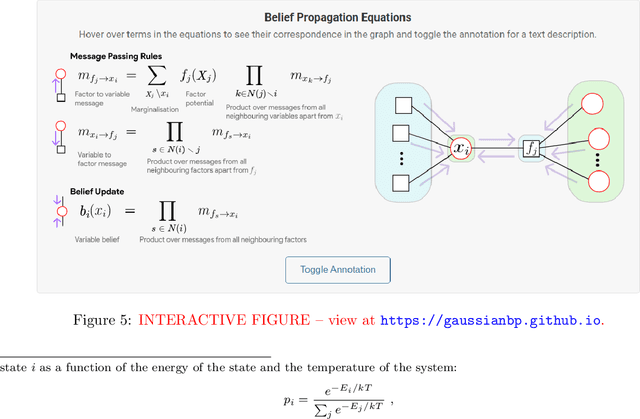
In this article, we present a visual introduction to Gaussian Belief Propagation (GBP), an approximate probabilistic inference algorithm that operates by passing messages between the nodes of arbitrarily structured factor graphs. A special case of loopy belief propagation, GBP updates rely only on local information and will converge independently of the message schedule. Our key argument is that, given recent trends in computing hardware, GBP has the right computational properties to act as a scalable distributed probabilistic inference framework for future machine learning systems.