 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-SRAM Radiant Foam Rendering on a Graph Processor
Jan 07, 2026Many emerging many-core accelerators replace a single large device memory with hundreds to thousands of lightweight cores, each owning only a small local SRAM and exchanging data via explicit on-chip communication. This organization offers high aggregate bandwidth, but it breaks a key assumption behind many volumetric rendering techniques: that rays can randomly access a large, unified scene representation. Rendering efficiently on such hardware therefore requires distributing both data and computation, keeping ray traversal mostly local, and structuring communication into predictable routes. We present a fully in-SRAM, distributed renderer for the \emph{Radiant Foam} Voronoi-cell volumetric representation on the Graphcore Mk2 IPU, a many-core accelerator with tile-local SRAM and explicit inter-tile communication. Our system shards the scene across tiles and forwards rays between shards through a hierarchical routing overlay, enabling ray marching entirely from on-chip SRAM with predictable communication. On Mip-NeRF~360 scenes, the system attains near-interactive throughput (\(\approx\)1\,fps at \mbox{$640\times480$}) with image and depth quality close to the original GPU-based Radiant Foam implementation, while keeping all scene data and ray state in on-chip SRAM. Beyond demonstrating feasibility, we analyze routing, memory, and scheduling bottlenecks that inform how future distributed-memory accelerators can better support irregular, data-movement-heavy rendering workloads.
KV-Tracker: Real-Time Pose Tracking with Transformers
Dec 27, 2025Multi-view 3D geometry networks offer a powerful prior but are prohibitively slow for real-time applications. We propose a novel way to adapt them for online use, enabling real-time 6-DoF pose tracking and online reconstruction of objects and scenes from monocular RGB videos. Our method rapidly selects and manages a set of images as keyframes to map a scene or object via $π^3$ with full bidirectional attention. We then cache the global self-attention block's key-value (KV) pairs and use them as the sole scene representation for online tracking. This allows for up to $15\times$ speedup during inference without the fear of drift or catastrophic forgetting. Our caching strategy is model-agnostic and can be applied to other off-the-shelf multi-view networks without retraining. We demonstrate KV-Tracker on both scene-level tracking and the more challenging task of on-the-fly object tracking and reconstruction without depth measurements or object priors. Experiments on the TUM RGB-D, 7-Scenes, Arctic and OnePose datasets show the strong performance of our system while maintaining high frame-rates up to ${\sim}27$ FPS.
4D Primitive-Mâché: Glueing Primitives for Persistent 4D Scene Reconstruction
Dec 18, 2025We present a dynamic reconstruction system that receives a casual monocular RGB video as input, and outputs a complete and persistent reconstruction of the scene. In other words, we reconstruct not only the the currently visible parts of the scene, but also all previously viewed parts, which enables replaying the complete reconstruction across all timesteps. Our method decomposes the scene into a set of rigid 3D primitives, which are assumed to be moving throughout the scene. Using estimated dense 2D correspondences, we jointly infer the rigid motion of these primitives through an optimisation pipeline, yielding a 4D reconstruction of the scene, i.e. providing 3D geometry dynamically moving through time. To achieve this, we also introduce a mechanism to extrapolate motion for objects that become invisible, employing motion-grouping techniques to maintain continuity. The resulting system enables 4D spatio-temporal awareness, offering capabilities such as replayable 3D reconstructions of articulated objects through time, multi-object scanning, and object permanence. On object scanning and multi-object datasets, our system significantly outperforms existing methods both quantitatively and qualitatively.
ACE-SLAM: Scene Coordinate Regression for Neural Implicit Real-Time SLAM
Dec 16, 2025We present a novel neural RGB-D Simultaneous Localization And Mapping (SLAM) system that learns an implicit map of the scene in real time. For the first time, we explore the use of Scene Coordinate Regression (SCR) as the core implicit map representation in a neural SLAM pipeline, a paradigm that trains a lightweight network to directly map 2D image features to 3D global coordinates. SCR networks provide efficient, low-memory 3D map representations, enable extremely fast relocalization, and inherently preserve privacy, making them particularly suitable for neural implicit SLAM. Our system is the first one to achieve strict real-time in neural implicit RGB-D SLAM by relying on a SCR-based representation. We introduce a novel SCR architecture specifically tailored for this purpose and detail the critical design choices required to integrate SCR into a live SLAM pipeline. The resulting framework is simple yet flexible, seamlessly supporting both sparse and dense features, and operates reliably in dynamic environments without special adaptation. We evaluate our approach on established synthetic and real-world benchmarks, demonstrating competitive performance against the state of the art. Project Page: https://github.com/ialzugaray/ace-slam
DANCeRS: A Distributed Algorithm for Negotiating Consensus in Robot Swarms with Gaussian Belief Propagation
Aug 25, 2025Robot swarms require cohesive collective behaviour to address diverse challenges, including shape formation and decision-making. Existing approaches often treat consensus in discrete and continuous decision spaces as distinct problems. We present DANCeRS, a unified, distributed algorithm leveraging Gaussian Belief Propagation (GBP) to achieve consensus in both domains. By representing a swarm as a factor graph our method ensures scalability and robustness in dynamic environments, relying on purely peer-to-peer message passing. We demonstrate the effectiveness of our general framework through two applications where agents in a swarm must achieve consensus on global behaviour whilst relying on local communication. In the first, robots must perform path planning and collision avoidance to create shape formations. In the second, we show how the same framework can be used by a group of robots to form a consensus over a set of discrete decisions. Experimental results highlight our method's scalability and efficiency compared to recent approaches to these problems making it a promising solution for multi-robot systems requiring distributed consensus. We encourage the reader to see the supplementary video demo.
4DTAM: Non-Rigid Tracking and Mapping via Dynamic Surface Gaussians
May 28, 2025We propose the first 4D tracking and mapping method that jointly performs camera localization and non-rigid surface reconstruction via differentiable rendering. Our approach captures 4D scenes from an online stream of color images with depth measurements or predictions by jointly optimizing scene geometry, appearance, dynamics, and camera ego-motion. Although natural environments exhibit complex non-rigid motions, 4D-SLAM remains relatively underexplored due to its inherent challenges; even with 2.5D signals, the problem is ill-posed because of the high dimensionality of the optimization space. To overcome these challenges, we first introduce a SLAM method based on Gaussian surface primitives that leverages depth signals more effectively than 3D Gaussians, thereby achieving accurate surface reconstruction. To further model non-rigid deformations, we employ a warp-field represented by a multi-layer perceptron (MLP) and introduce a novel camera pose estimation technique along with surface regularization terms that facilitate spatio-temporal reconstruction. In addition to these algorithmic challenges, a significant hurdle in 4D SLAM research is the lack of reliable ground truth and evaluation protocols, primarily due to the difficulty of 4D capture using commodity sensors. To address this, we present a novel open synthetic dataset of everyday objects with diverse motions, leveraging large-scale object models and animation modeling. In summary, we open up the modern 4D-SLAM research by introducing a novel method and evaluation protocols grounded in modern vision and rendering techniques.
MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors
Dec 16, 2024



We present a real-time monocular dense SLAM system designed bottom-up from MASt3R, a two-view 3D reconstruction and matching prior. Equipped with this strong prior, our system is robust on in-the-wild video sequences despite making no assumption on a fixed or parametric camera model beyond a unique camera centre. We introduce efficient methods for pointmap matching, camera tracking and local fusion, graph construction and loop closure, and second-order global optimisation. With known calibration, a simple modification to the system achieves state-of-the-art performance across various benchmarks. Altogether, we propose a plug-and-play monocular SLAM system capable of producing globally-consistent poses and dense geometry while operating at 15 FPS.
COMO: Compact Mapping and Odometry
Apr 04, 2024



We present COMO, a real-time monocular mapping and odometry system that encodes dense geometry via a compact set of 3D anchor points. Decoding anchor point projections into dense geometry via per-keyframe depth covariance functions guarantees that depth maps are joined together at visible anchor points. The representation enables joint optimization of camera poses and dense geometry, intrinsic 3D consistency, and efficient second-order inference. To maintain a compact yet expressive map, we introduce a frontend that leverages the covariance function for tracking and initializing potentially visually indistinct 3D points across frames. Altogether, we introduce a real-time system capable of estimating accurate poses and consistent geometry.
U-ARE-ME: Uncertainty-Aware Rotation Estimation in Manhattan Environments
Mar 22, 2024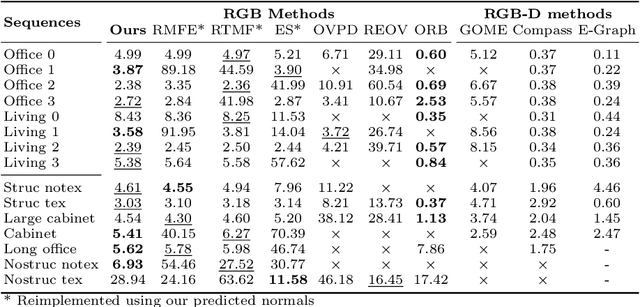


Camera rotation estimation from a single image is a challenging task, often requiring depth data and/or camera intrinsics, which are generally not available for in-the-wild videos. Although external sensors such as inertial measurement units (IMUs) can help, they often suffer from drift and are not applicable in non-inertial reference frames. We present U-ARE-ME, an algorithm that estimates camera rotation along with uncertainty from uncalibrated RGB images. Using a Manhattan World assumption, our method leverages the per-pixel geometric priors encoded in single-image surface normal predictions and performs optimisation over the SO(3) manifold. Given a sequence of images, we can use the per-frame rotation estimates and their uncertainty to perform multi-frame optimisation, achieving robustness and temporal consistency. Our experiments demonstrate that U-ARE-ME performs comparably to RGB-D methods and is more robust than sparse feature-based SLAM methods. We encourage the reader to view the accompanying video at https://callum-rhodes.github.io/U-ARE-ME for a visual overview of our method.
Rethinking Inductive Biases for Surface Normal Estimation
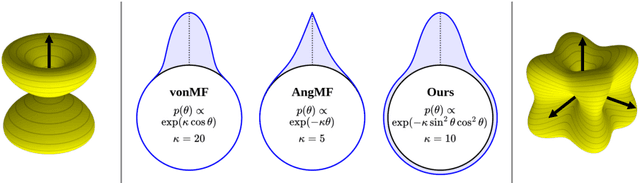
Mar 01, 2024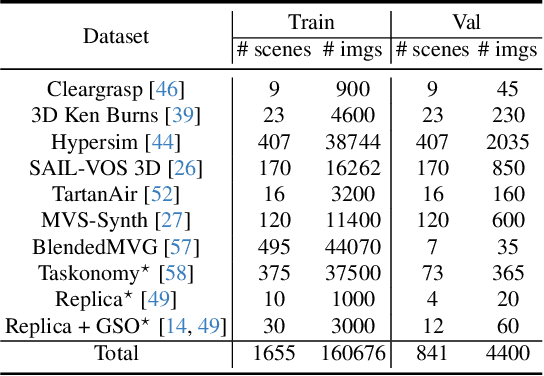
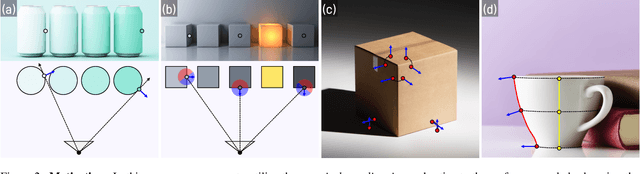
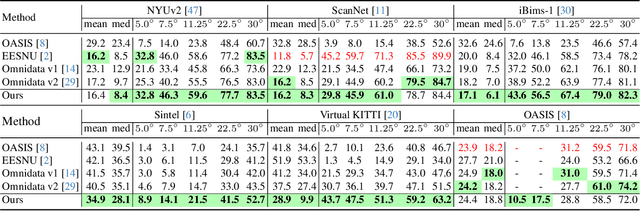

Despite the growing demand for accurate surface normal estimation models, existing methods use general-purpose dense prediction models, adopting the same inductive biases as other tasks. In this paper, we discuss the inductive biases needed for surface normal estimation and propose to (1) utilize the per-pixel ray direction and (2) encode the relationship between neighboring surface normals by learning their relative rotation. The proposed method can generate crisp - yet, piecewise smooth - predictions for challenging in-the-wild images of arbitrary resolution and aspect ratio. Compared to a recent ViT-based state-of-the-art model, our method shows a stronger generalization ability, despite being trained on an orders of magnitude smaller dataset. The code is available at https://github.com/baegwangbin/DSINE.