 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperPrimitive: Scene Reconstruction at a Primitive Level
Paper and Code

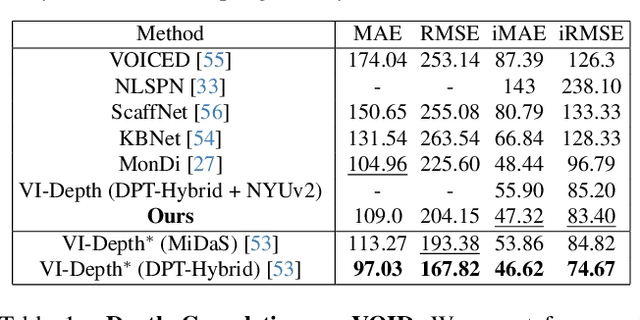
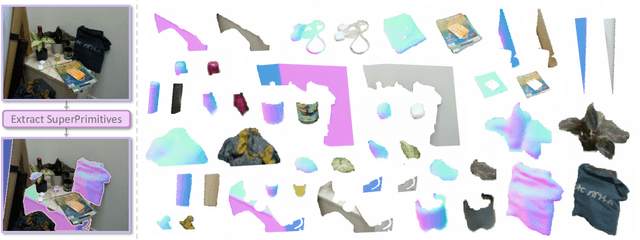
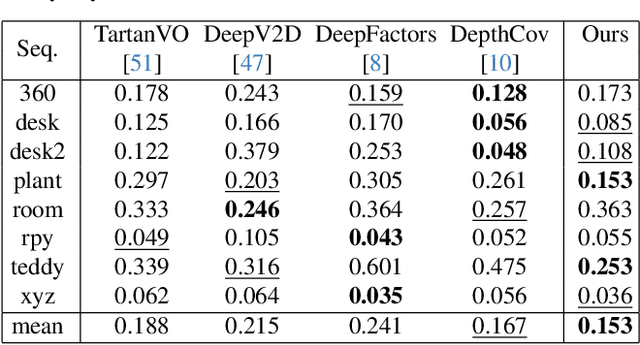
Joint camera pose and dense geometry estimation from a set of images or a monocular video remains a challenging problem due to its computational complexity and inherent visual ambiguities. Most dense incremental reconstruction systems operate directly on image pixels and solve for their 3D positions using multi-view geometry cues. Such pixel-level approaches suffer from ambiguities or violations of multi-view consistency (e.g. caused by textureless or specular surfaces). We address this issue with a new image representation which we call a SuperPrimitive. SuperPrimitives are obtained by splitting images into semantically correlated local regions and enhancing them with estimated surface normal directions, both of which are predicted by state-of-the-art single image neural networks. This provides a local geometry estimate per SuperPrimitive, while their relative positions are adjusted based on multi-view observations. We demonstrate the versatility of our new representation by addressing three 3D reconstruction tasks: depth completion, few-view structure from motion, and monocular dense visual odometry.