 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriangle Splatting SLAM
May 29, 2026We present a dense RGB-D SLAM system using differentiable triangles as the 3D map representation. While 3D Gaussian Splatting has emerged as the leading method for novel-view synthesis, triangles remain the standard primitive for traditional rendering hardware, game engines, and downstream tasks requiring explicit geometry such as simulation, collision, and editing. Recent offline methods have demonstrated that an unstructured 'triangle soup' can be optimised into a photorealistic mesh via Delaunay triangulation across a set of posed images. Building upon this insight, we present the first dense SLAM system to employ Triangle Splatting to perform both tracking and mapping through online differentiable rendering of a triangle soup. The map can be converted into a connected mesh on-the-fly via restricted Delaunay triangulation, enabling new online capabilities such as mesh deformation and collision checking. On Replica and TUM-RGBD, our system outperforms baselines on 3D geometry, matches the camera-tracking accuracy, and enables online mesh-based scene editing.
KV-Tracker: Real-Time Pose Tracking with Transformers
Dec 27, 2025Multi-view 3D geometry networks offer a powerful prior but are prohibitively slow for real-time applications. We propose a novel way to adapt them for online use, enabling real-time 6-DoF pose tracking and online reconstruction of objects and scenes from monocular RGB videos. Our method rapidly selects and manages a set of images as keyframes to map a scene or object via $π^3$ with full bidirectional attention. We then cache the global self-attention block's key-value (KV) pairs and use them as the sole scene representation for online tracking. This allows for up to $15\times$ speedup during inference without the fear of drift or catastrophic forgetting. Our caching strategy is model-agnostic and can be applied to other off-the-shelf multi-view networks without retraining. We demonstrate KV-Tracker on both scene-level tracking and the more challenging task of on-the-fly object tracking and reconstruction without depth measurements or object priors. Experiments on the TUM RGB-D, 7-Scenes, Arctic and OnePose datasets show the strong performance of our system while maintaining high frame-rates up to ${\sim}27$ FPS.
4D Primitive-Mâché: Glueing Primitives for Persistent 4D Scene Reconstruction
Dec 18, 2025We present a dynamic reconstruction system that receives a casual monocular RGB video as input, and outputs a complete and persistent reconstruction of the scene. In other words, we reconstruct not only the the currently visible parts of the scene, but also all previously viewed parts, which enables replaying the complete reconstruction across all timesteps. Our method decomposes the scene into a set of rigid 3D primitives, which are assumed to be moving throughout the scene. Using estimated dense 2D correspondences, we jointly infer the rigid motion of these primitives through an optimisation pipeline, yielding a 4D reconstruction of the scene, i.e. providing 3D geometry dynamically moving through time. To achieve this, we also introduce a mechanism to extrapolate motion for objects that become invisible, employing motion-grouping techniques to maintain continuity. The resulting system enables 4D spatio-temporal awareness, offering capabilities such as replayable 3D reconstructions of articulated objects through time, multi-object scanning, and object permanence. On object scanning and multi-object datasets, our system significantly outperforms existing methods both quantitatively and qualitatively.
SuperPrimitive: Scene Reconstruction at a Primitive Level
Dec 10, 2023
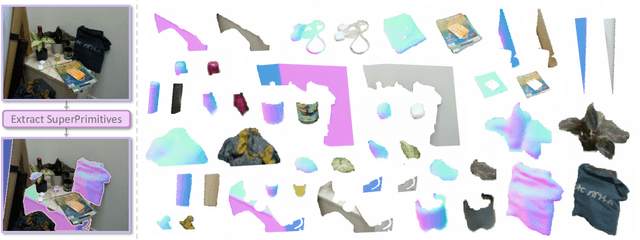
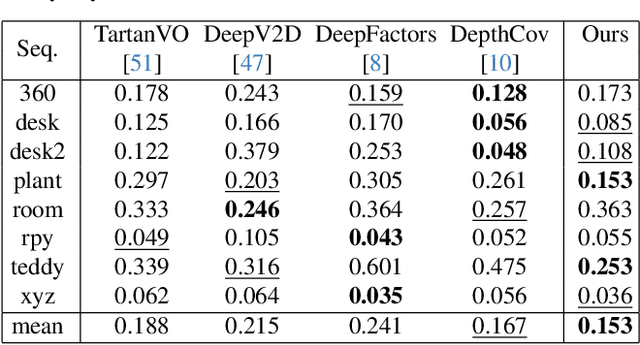
Joint camera pose and dense geometry estimation from a set of images or a monocular video remains a challenging problem due to its computational complexity and inherent visual ambiguities. Most dense incremental reconstruction systems operate directly on image pixels and solve for their 3D positions using multi-view geometry cues. Such pixel-level approaches suffer from ambiguities or violations of multi-view consistency (e.g. caused by textureless or specular surfaces). We address this issue with a new image representation which we call a SuperPrimitive. SuperPrimitives are obtained by splitting images into semantically correlated local regions and enhancing them with estimated surface normal directions, both of which are predicted by state-of-the-art single image neural networks. This provides a local geometry estimate per SuperPrimitive, while their relative positions are adjusted based on multi-view observations. We demonstrate the versatility of our new representation by addressing three 3D reconstruction tasks: depth completion, few-view structure from motion, and monocular dense visual odometry.
Feature-Realistic Neural Fusion for Real-Time, Open Set Scene Understanding
Oct 06, 2022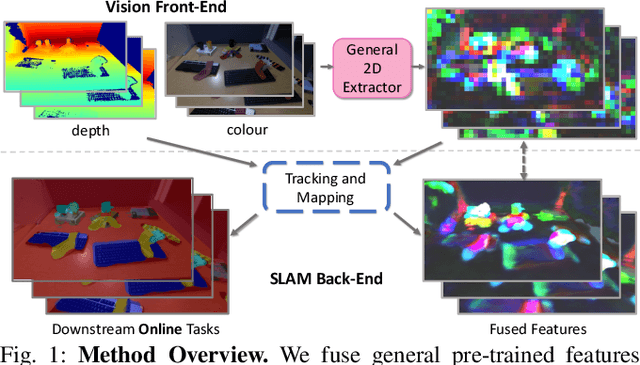


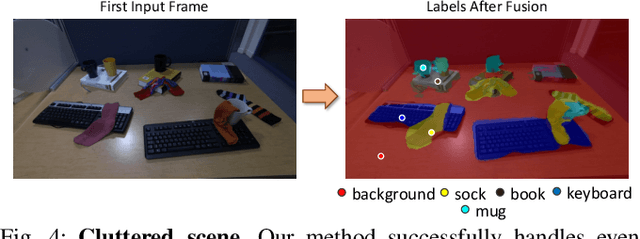
General scene understanding for robotics requires flexible semantic representation, so that novel objects and structures which may not have been known at training time can be identified, segmented and grouped. We present an algorithm which fuses general learned features from a standard pre-trained network into a highly efficient 3D geometric neural field representation during real-time SLAM. The fused 3D feature maps inherit the coherence of the neural field's geometry representation. This means that tiny amounts of human labelling interacting at runtime enable objects or even parts of objects to be robustly and accurately segmented in an open set manner.
Point-Based Modeling of Human Clothing
Apr 22, 2021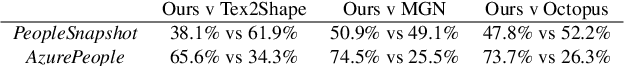
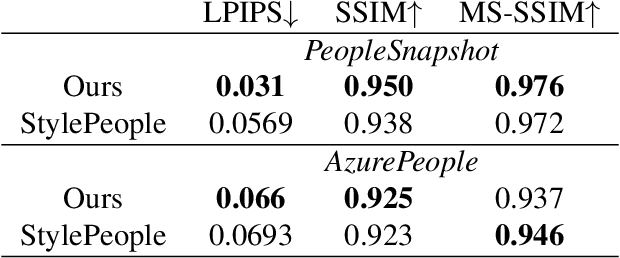
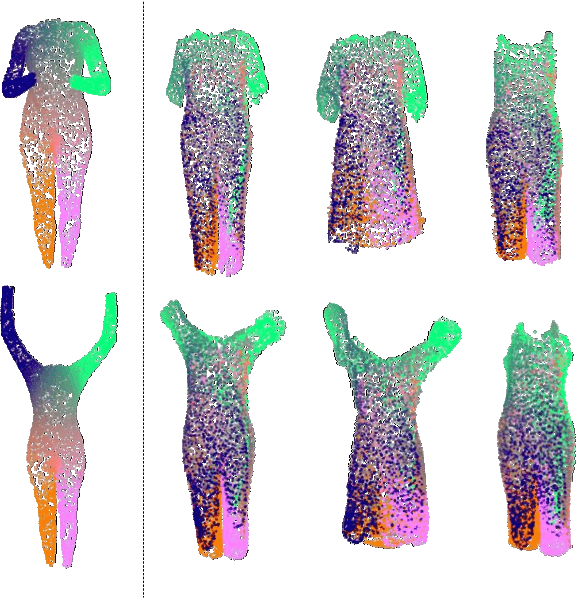
We propose a new approach to human clothing modeling based on point clouds. Within this approach, we learn a deep model that can predict point clouds of various outfits, for various human poses and for various human body shapes. Notably, outfits of various types and topologies can be handled by the same model. Using the learned model, we can infer geometry of new outfits from as little as a singe image, and perform outfit retargeting to new bodies in new poses. We complement our geometric model with appearance modeling that uses the point cloud geometry as a geometric scaffolding, and employs neural point-based graphics to capture outfit appearance from videos and to re-render the captured outfits. We validate both geometric modeling and appearance modeling aspects of the proposed approach against recently proposed methods, and establish the viability of point-based clothing modeling.
Cloud Transformers
Jul 22, 2020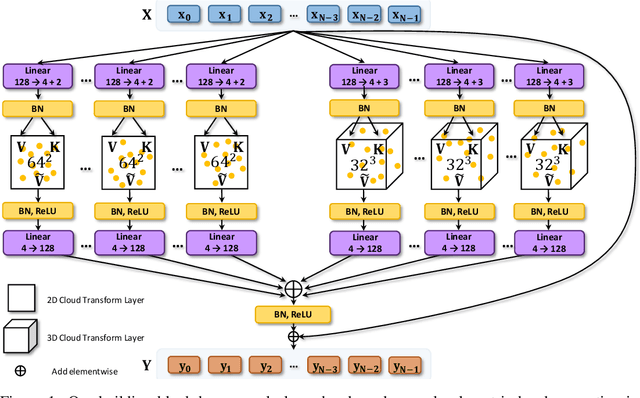
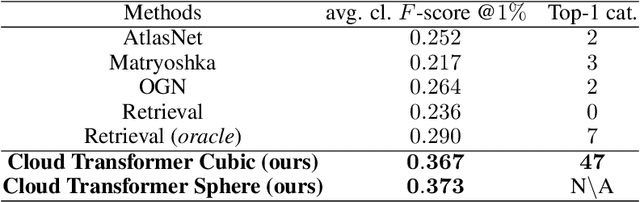
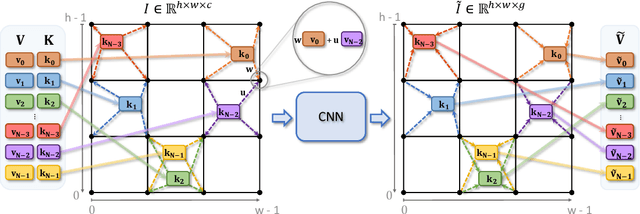
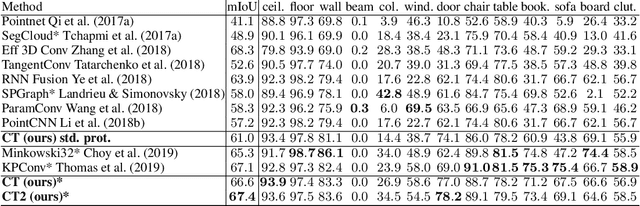
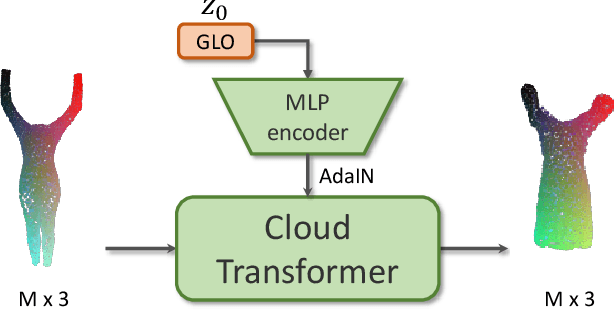
We present a new versatile building block for deep point cloud processing architectures. This building block combines the ideas of self-attention layers from the transformer architecture with the efficiency of standard convolutional layers in two and three-dimensional dense grids. The new block operates via multiple parallel heads, whereas each head projects feature representations of individual points into a low-dimensional space, treats the first two or three dimensions as spatial coordinates and then uses dense convolution to propagate information across points. The results of the processing of individual heads are then combined together resulting in the update of point features. Using the new block, we build architectures for point cloud segmentation as well as for image-based point cloud reconstruction. We show that despite the dissimilarity between these tasks, the resulting architectures achieve state-of-the-art performance for both of them demonstrating the versatility of the new block.