 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloud Transformers
Paper and Code
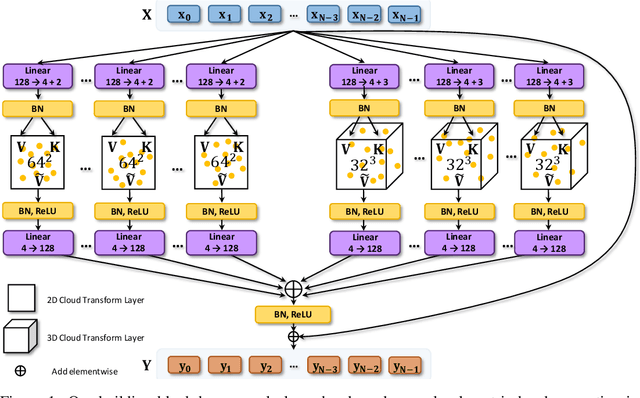
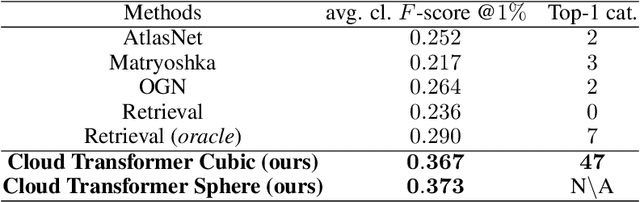
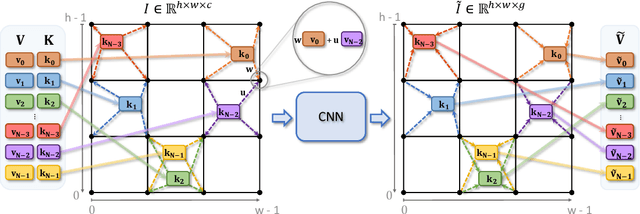
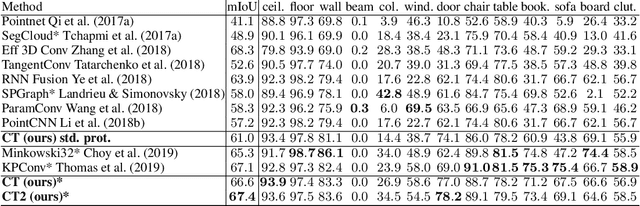
We present a new versatile building block for deep point cloud processing architectures. This building block combines the ideas of self-attention layers from the transformer architecture with the efficiency of standard convolutional layers in two and three-dimensional dense grids. The new block operates via multiple parallel heads, whereas each head projects feature representations of individual points into a low-dimensional space, treats the first two or three dimensions as spatial coordinates and then uses dense convolution to propagate information across points. The results of the processing of individual heads are then combined together resulting in the update of point features. Using the new block, we build architectures for point cloud segmentation as well as for image-based point cloud reconstruction. We show that despite the dissimilarity between these tasks, the resulting architectures achieve state-of-the-art performance for both of them demonstrating the versatility of the new block.