 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRF: Mobile Realistic Fullbody Avatars from a Monocular Video
Mar 17, 2023
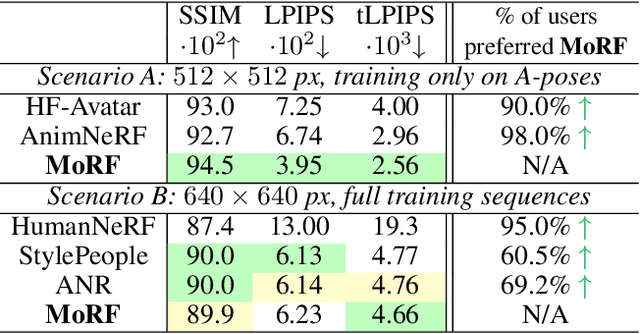
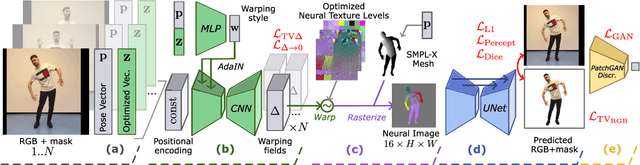
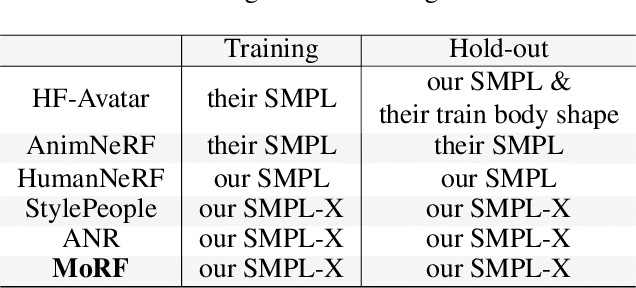
We present a new approach for learning Mobile Realistic Fullbody (MoRF) avatars. MoRF avatars can be rendered in real-time on mobile phones, have high realism, and can be learned from monocular videos. As in previous works, we use a combination of neural textures and the mesh-based body geometry modeling SMPL-X. We improve on prior work, by learning per-frame warping fields in the neural texture space, allowing to better align the training signal between different frames. We also apply existing SMPL-X fitting procedure refinements for videos to improve overall avatar quality. In the comparisons to other monocular video-based avatar systems, MoRF avatars achieve higher image sharpness and temporal consistency. Participants of our user study also preferred avatars generated by MoRF.
Point-Based Modeling of Human Clothing
Apr 22, 2021
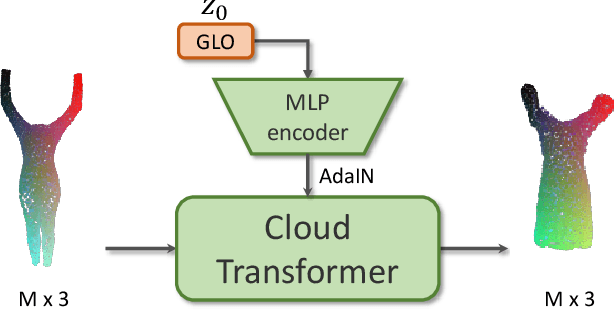
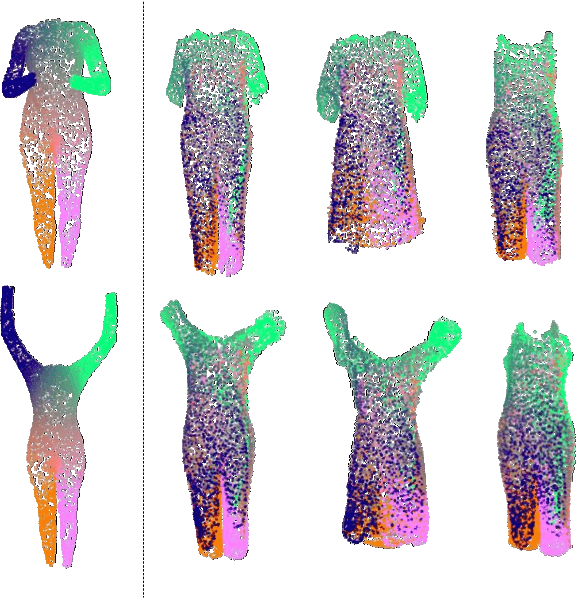
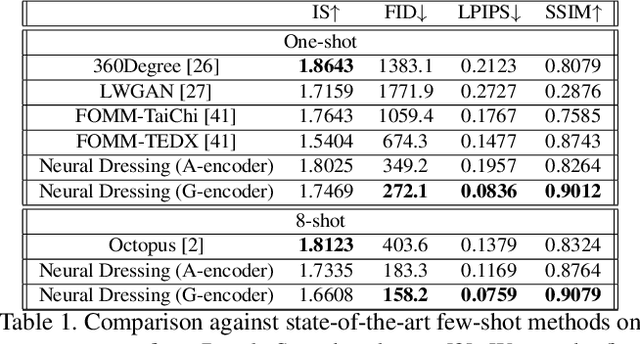
We propose a new approach to human clothing modeling based on point clouds. Within this approach, we learn a deep model that can predict point clouds of various outfits, for various human poses and for various human body shapes. Notably, outfits of various types and topologies can be handled by the same model. Using the learned model, we can infer geometry of new outfits from as little as a singe image, and perform outfit retargeting to new bodies in new poses. We complement our geometric model with appearance modeling that uses the point cloud geometry as a geometric scaffolding, and employs neural point-based graphics to capture outfit appearance from videos and to re-render the captured outfits. We validate both geometric modeling and appearance modeling aspects of the proposed approach against recently proposed methods, and establish the viability of point-based clothing modeling.
StylePeople: A Generative Model of Fullbody Human Avatars
Apr 16, 2021

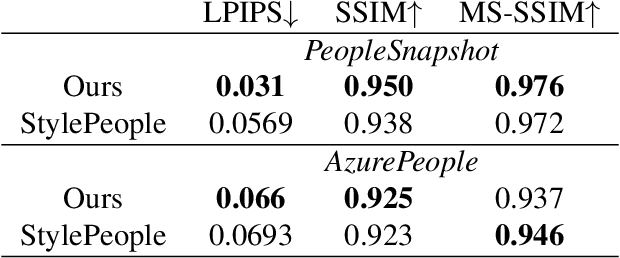
We propose a new type of full-body human avatars, which combines parametric mesh-based body model with a neural texture. We show that with the help of neural textures, such avatars can successfully model clothing and hair, which usually poses a problem for mesh-based approaches. We also show how these avatars can be created from multiple frames of a video using backpropagation. We then propose a generative model for such avatars that can be trained from datasets of images and videos of people. The generative model allows us to sample random avatars as well as to create dressed avatars of people from one or few images. The code for the project is available at saic-violet.github.io/style-people.
ZoomTouch: Multi-User Remote Robot Control in Zoom by DNN-based Gesture Recognition
Nov 07, 2020
We present ZoomTouch - a breakthrough technology for multi-user control of robot from Zoom in real-time by DNN-based gesture recognition. The users from digital world can have a video conferencing and manipulate the robot to make the dexterous manipulations with tangible objects. As the scenario, we proposed the remote COVID-19 test Laboratory to considerably reduce the time to receive the data and substitute medical assistant working in protective gear in close proximity with infected cells. The proposed technology suggests a new type of reality, where multi-users can jointly interact with remote object, e.g. make a new building design, joint cooking in robotic kitchen, etc, and discuss/modify the results at the same time.