 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGH: Dynamic Gaussian Hair
Dec 18, 2025The creation of photorealistic dynamic hair remains a major challenge in digital human modeling because of the complex motions, occlusions, and light scattering. Existing methods often resort to static capture and physics-based models that do not scale as they require manual parameter fine-tuning to handle the diversity of hairstyles and motions, and heavy computation to obtain high-quality appearance. In this paper, we present Dynamic Gaussian Hair (DGH), a novel framework that efficiently learns hair dynamics and appearance. We propose: (1) a coarse-to-fine model that learns temporally coherent hair motion dynamics across diverse hairstyles; (2) a strand-guided optimization module that learns a dynamic 3D Gaussian representation for hair appearance with support for differentiable rendering, enabling gradient-based learning of view-consistent appearance under motion. Unlike prior simulation-based pipelines, our approach is fully data-driven, scales with training data, and generalizes across various hairstyles and head motion sequences. Additionally, DGH can be seamlessly integrated into a 3D Gaussian avatar framework, enabling realistic, animatable hair for high-fidelity avatar representation. DGH achieves promising geometry and appearance results, providing a scalable, data-driven alternative to physics-based simulation and rendering.
GigaEmbeddings: Efficient Russian Language Embedding Model
Oct 25, 2025



We introduce GigaEmbeddings, a novel framework for training high-performance Russian-focused text embeddings through hierarchical instruction tuning of the decoder-only LLM designed specifically for Russian language (GigaChat-3B). Our three-stage pipeline, comprising large-scale contrastive pre-training in web-scale corpora, fine-tuning with hard negatives, and multitask generalization across retrieval, classification, and clustering tasks, addresses key limitations of existing methods by unifying diverse objectives and leveraging synthetic data generation. Architectural innovations include bidirectional attention for contextual modeling, latent attention pooling for robust sequence aggregation, and strategic pruning of 25% of transformer layers to enhance efficiency without compromising performance. Evaluated on the ruMTEB benchmark spanning 23 multilingual tasks, GigaEmbeddings achieves state-of-the-art results (69.1 avg. score), outperforming strong baselines with a larger number of parameters.
BodyMap: Learning Full-Body Dense Correspondence Map
May 18, 2022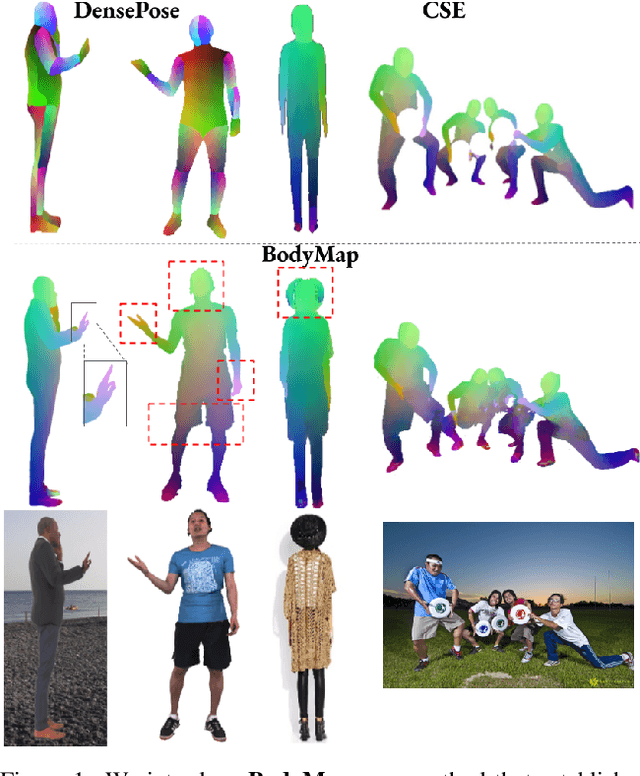
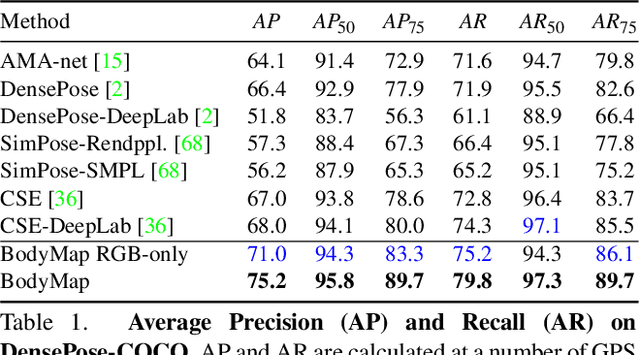
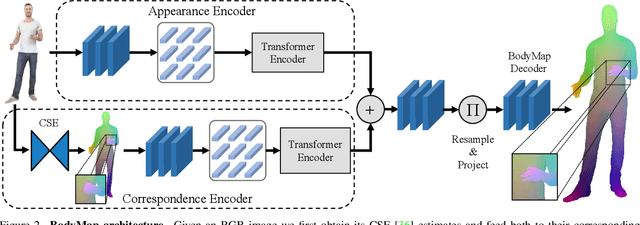
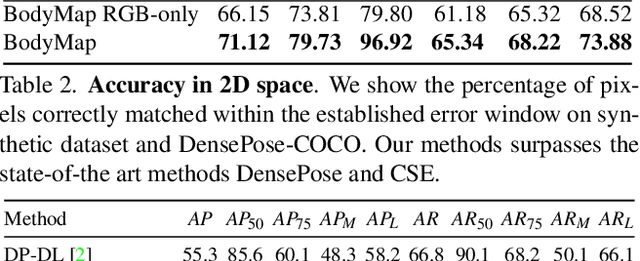
Dense correspondence between humans carries powerful semantic information that can be utilized to solve fundamental problems for full-body understanding such as in-the-wild surface matching, tracking and reconstruction. In this paper we present BodyMap, a new framework for obtaining high-definition full-body and continuous dense correspondence between in-the-wild images of clothed humans and the surface of a 3D template model. The correspondences cover fine details such as hands and hair, while capturing regions far from the body surface, such as loose clothing. Prior methods for estimating such dense surface correspondence i) cut a 3D body into parts which are unwrapped to a 2D UV space, producing discontinuities along part seams, or ii) use a single surface for representing the whole body, but none handled body details. Here, we introduce a novel network architecture with Vision Transformers that learn fine-level features on a continuous body surface. BodyMap outperforms prior work on various metrics and datasets, including DensePose-COCO by a large margin. Furthermore, we show various applications ranging from multi-layer dense cloth correspondence, neural rendering with novel-view synthesis and appearance swapping.
StylePeople: A Generative Model of Fullbody Human Avatars
Apr 16, 2021
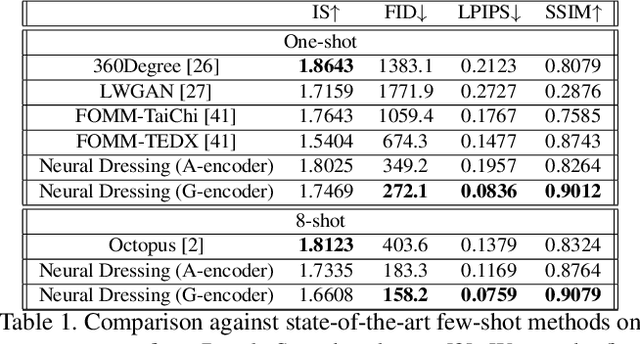

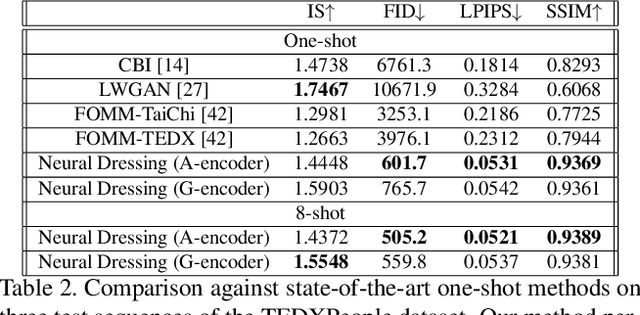
We propose a new type of full-body human avatars, which combines parametric mesh-based body model with a neural texture. We show that with the help of neural textures, such avatars can successfully model clothing and hair, which usually poses a problem for mesh-based approaches. We also show how these avatars can be created from multiple frames of a video using backpropagation. We then propose a generative model for such avatars that can be trained from datasets of images and videos of people. The generative model allows us to sample random avatars as well as to create dressed avatars of people from one or few images. The code for the project is available at saic-violet.github.io/style-people.
Real-time RGBD-based Extended Body Pose Estimation
Mar 05, 2021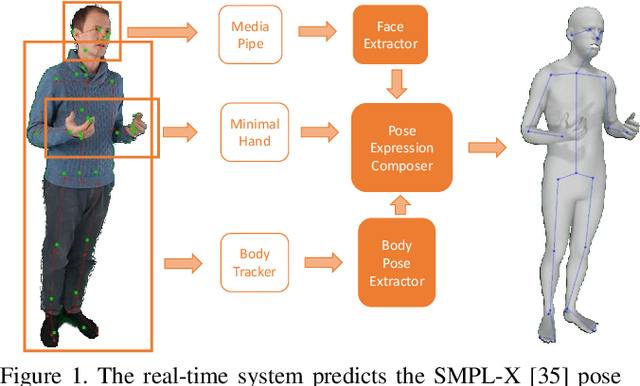
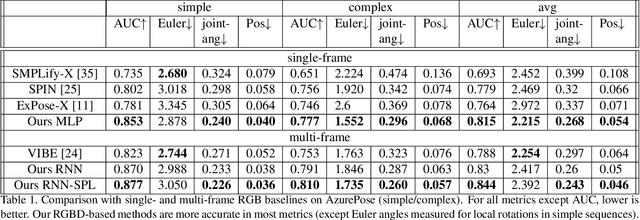
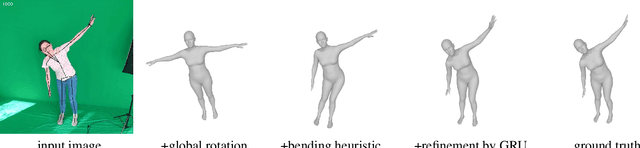
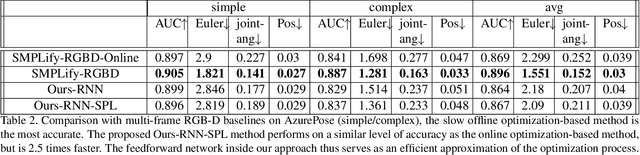
We present a system for real-time RGBD-based estimation of 3D human pose. We use parametric 3D deformable human mesh model (SMPL-X) as a representation and focus on the real-time estimation of parameters for the body pose, hands pose and facial expression from Kinect Azure RGB-D camera. We train estimators of body pose and facial expression parameters. Both estimators use previously published landmark extractors as input and custom annotated datasets for supervision, while hand pose is estimated directly by a previously published method. We combine the predictions of those estimators into a temporally-smooth human pose. We train the facial expression extractor on a large talking face dataset, which we annotate with facial expression parameters. For the body pose we collect and annotate a dataset of 56 people captured from a rig of 5 Kinect Azure RGB-D cameras and use it together with a large motion capture AMASS dataset. Our RGB-D body pose model outperforms the state-of-the-art RGB-only methods and works on the same level of accuracy compared to a slower RGB-D optimization-based solution. The combined system runs at 30 FPS on a server with a single GPU. The code will be available at https://saic-violet.github.io/rgbd-kinect-pose
Free-Lunch Saliency via Attention in Atari Agents
Aug 07, 2019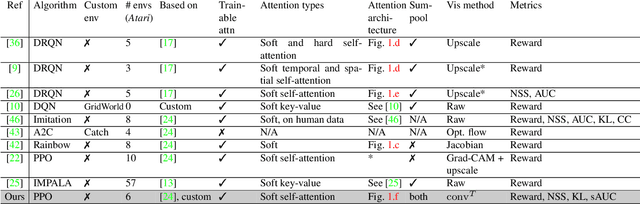
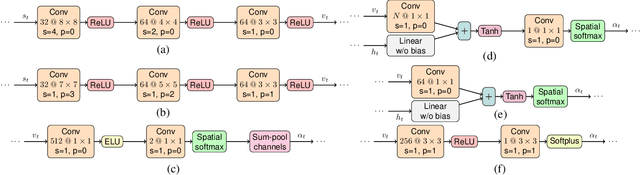
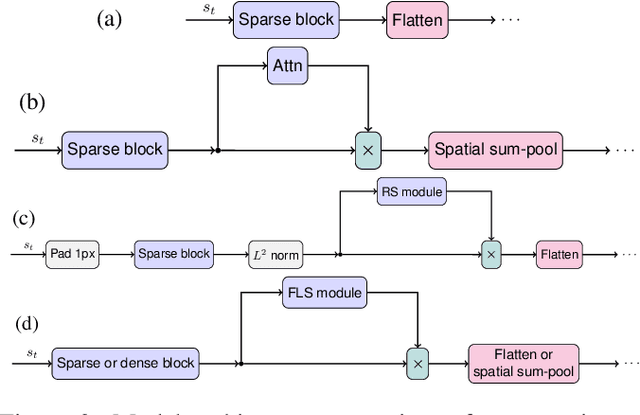
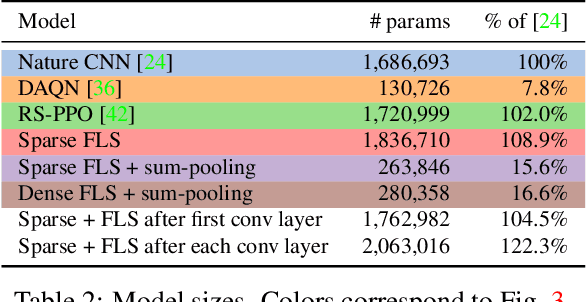
We propose a new approach to visualize saliency maps for deep neural network models and apply it to deep reinforcement learning agents trained on Atari environments. Our method adds an attention module that we call FLS (Free Lunch Saliency) to the feature extractor from an established baseline (Mnih et al., 2015). This addition results in a trainable model that can produce saliency maps, i.e., visualizations of the importance of different parts of the input for the agent's current decision making. We show experimentally that a network with an FLS module exhibits performance similar to the baseline (i.e., it is "free", with no performance cost) and can be used as a drop-in replacement for reinforcement learning agents. We also design another feature extractor that scores slightly lower but provides higher-fidelity visualizations. In addition to attained scores, we report saliency metrics evaluated on the Atari-HEAD dataset of human gameplay.