 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Keypoints for the Two-View Geometry Estimation Problem
Mar 24, 2025



Local features are essential to many modern downstream applications. Therefore, it is of interest to determine the properties of local features that contribute to the downstream performance for a better design of feature detectors and descriptors. In our work, we propose a new theoretical model for scoring feature points (keypoints) in the context of the two-view geometry estimation problem. The model determines two properties that a good keypoint for solving the homography estimation problem should have: be repeatable and have a small expected measurement error. This result provides key insights into why maximizing the number of correspondences doesn't always lead to better homography estimation accuracy. We use the developed model to design a method that detects keypoints that benefit the homography estimation introducing the Bounded NeSS-ST (BoNeSS-ST) keypoint detector. The novelty of BoNeSS-ST comes from strong theoretical foundations, a more accurate keypoint scoring due to subpixel refinement and a cost designed for superior robustness to low saliency keypoints. As a result, BoNeSS-ST outperforms prior self-supervised local feature detectors in both planar homography and epipolar geometry estimation problems.
Shi-NeSS: Detecting Good and Stable Keypoints with a Neural Stability Score
Jul 03, 2023
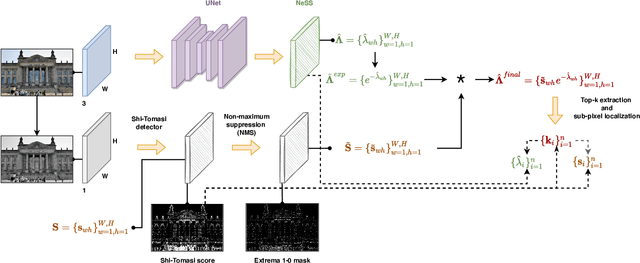

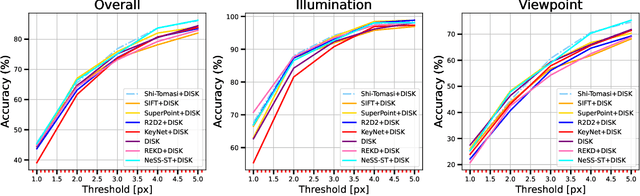
Learning a feature point detector presents a challenge both due to the ambiguity of the definition of a keypoint and correspondingly the need for a specially prepared ground truth labels for such points. In our work, we address both of these issues by utilizing a combination of a hand-crafted Shi detector and a neural network. We build on the principled and localized keypoints provided by the Shi detector and perform their selection using the keypoint stability score regressed by the neural network - Neural Stability Score (NeSS). Therefore, our method is named Shi-NeSS since it combines the Shi detector and the properties of the keypoint stability score, and it only requires for training sets of images without dataset pre-labeling or the need for reconstructed correspondence labels. We evaluate Shi-NeSS on HPatches, ScanNet, MegaDepth and IMC-PT, demonstrating state-of-the-art performance and good generalization on downstream tasks.
SeMLaPS: Real-time Semantic Mapping with Latent Prior Networks and Quasi-Planar Segmentation
Jun 28, 2023



The availability of real-time semantics greatly improves the core geometric functionality of SLAM systems, enabling numerous robotic and AR/VR applications. We present a new methodology for real-time semantic mapping from RGB-D sequences that combines a 2D neural network and a 3D network based on a SLAM system with 3D occupancy mapping. When segmenting a new frame we perform latent feature re-projection from previous frames based on differentiable rendering. Fusing re-projected feature maps from previous frames with current-frame features greatly improves image segmentation quality, compared to a baseline that processes images independently. For 3D map processing, we propose a novel geometric quasi-planar over-segmentation method that groups 3D map elements likely to belong to the same semantic classes, relying on surface normals. We also describe a novel neural network design for lightweight semantic map post-processing. Our system achieves state-of-the-art semantic mapping quality within 2D-3D networks-based systems and matches the performance of 3D convolutional networks on three real indoor datasets, while working in real-time. Moreover, it shows better cross-sensor generalization abilities compared to 3D CNNs, enabling training and inference with different depth sensors. Code and data will be released on project page: http://jingwenwang95.github.io/SeMLaPS
Self-Supervised Depth Completion for Active Stereo
Oct 07, 2021


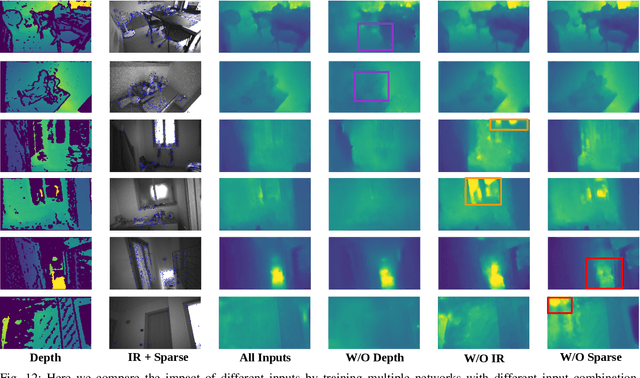
Active stereo systems are widely used in the robotics industry due to their low cost and high quality depth maps. These depth sensors, however, suffer from stereo artefacts and do not provide dense depth estimates. In this work, we present the first self-supervised depth completion method for active stereo systems that predicts accurate dense depth maps. Our system leverages a feature-based visual inertial SLAM system to produce motion estimates and accurate (but sparse) 3D landmarks. The 3D landmarks are used both as model input and as supervision during training. The motion estimates are used in our novel reconstruction loss that relies on a combination of passive and active stereo frames, resulting in significant improvements in textureless areas that are common in indoor environments. Due to the non-existence of publicly available active stereo datasets, we release a real dataset together with additional information for a publicly available synthetic dataset needed for active depth completion and prediction. Through rigorous evaluations we show that our method outperforms state of the art on both datasets. Additionally we show how our method obtains more complete, and therefore safer, 3D maps when used in a robotic platform
Uncertainty-Aware Camera Pose Estimation from Points and Lines
Jul 08, 2021
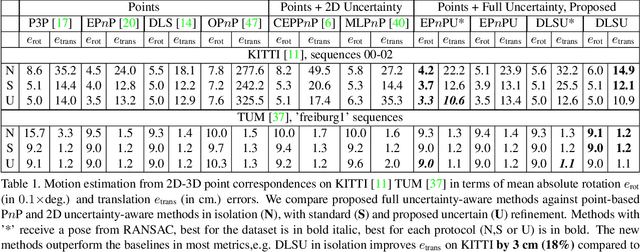
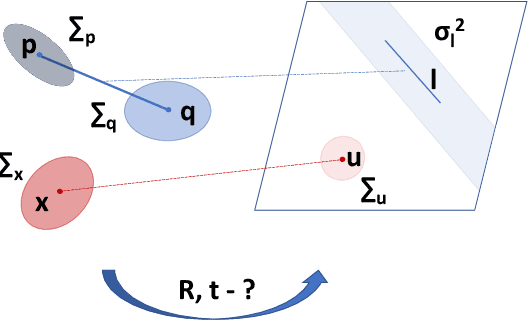
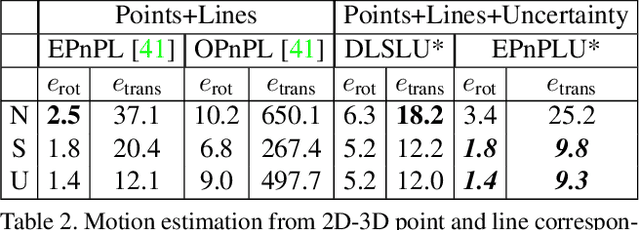
Perspective-n-Point-and-Line (P$n$PL) algorithms aim at fast, accurate, and robust camera localization with respect to a 3D model from 2D-3D feature correspondences, being a major part of modern robotic and AR/VR systems. Current point-based pose estimation methods use only 2D feature detection uncertainties, and the line-based methods do not take uncertainties into account. In our setup, both 3D coordinates and 2D projections of the features are considered uncertain. We propose PnP(L) solvers based on EPnP and DLS for the uncertainty-aware pose estimation. We also modify motion-only bundle adjustment to take 3D uncertainties into account. We perform exhaustive synthetic and real experiments on two different visual odometry datasets. The new PnP(L) methods outperform the state-of-the-art on real data in isolation, showing an increase in mean translation accuracy by 18% on a representative subset of KITTI, while the new uncertain refinement improves pose accuracy for most of the solvers, e.g. decreasing mean translation error for the EPnP by 16% compared to the standard refinement on the same dataset. The code is available at https://alexandervakhitov.github.io/uncertain-pnp/.
StylePeople: A Generative Model of Fullbody Human Avatars
Apr 16, 2021

We propose a new type of full-body human avatars, which combines parametric mesh-based body model with a neural texture. We show that with the help of neural textures, such avatars can successfully model clothing and hair, which usually poses a problem for mesh-based approaches. We also show how these avatars can be created from multiple frames of a video using backpropagation. We then propose a generative model for such avatars that can be trained from datasets of images and videos of people. The generative model allows us to sample random avatars as well as to create dressed avatars of people from one or few images. The code for the project is available at saic-violet.github.io/style-people.
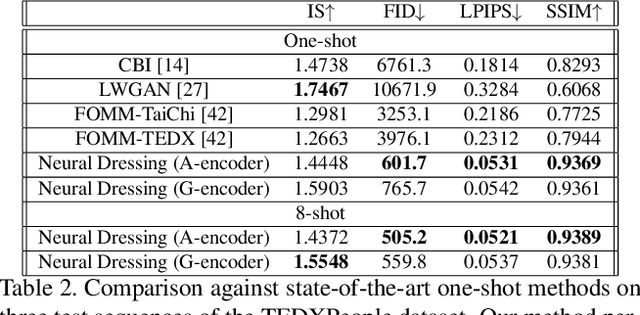
Real-time RGBD-based Extended Body Pose Estimation
Mar 05, 2021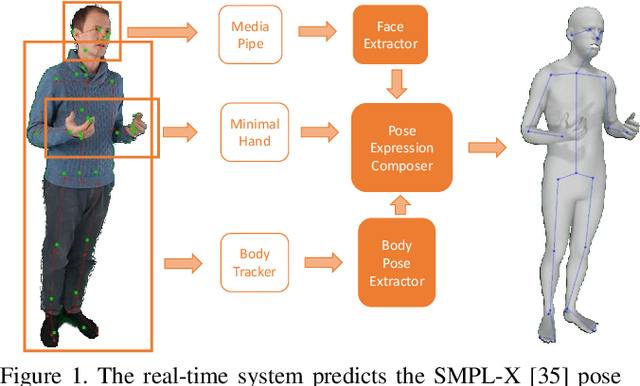
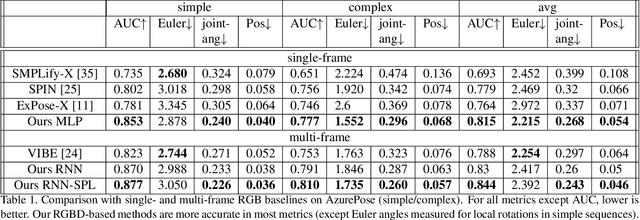
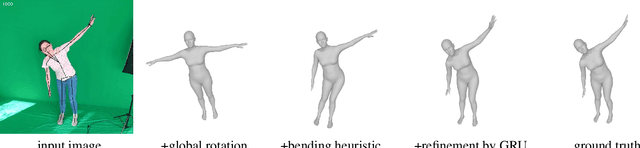
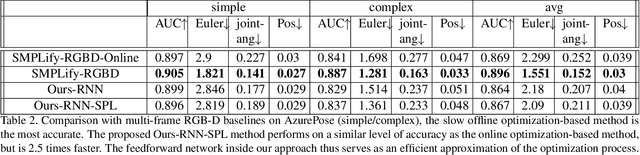
We present a system for real-time RGBD-based estimation of 3D human pose. We use parametric 3D deformable human mesh model (SMPL-X) as a representation and focus on the real-time estimation of parameters for the body pose, hands pose and facial expression from Kinect Azure RGB-D camera. We train estimators of body pose and facial expression parameters. Both estimators use previously published landmark extractors as input and custom annotated datasets for supervision, while hand pose is estimated directly by a previously published method. We combine the predictions of those estimators into a temporally-smooth human pose. We train the facial expression extractor on a large talking face dataset, which we annotate with facial expression parameters. For the body pose we collect and annotate a dataset of 56 people captured from a rig of 5 Kinect Azure RGB-D cameras and use it together with a large motion capture AMASS dataset. Our RGB-D body pose model outperforms the state-of-the-art RGB-only methods and works on the same level of accuracy compared to a slower RGB-D optimization-based solution. The combined system runs at 30 FPS on a server with a single GPU. The code will be available at https://saic-violet.github.io/rgbd-kinect-pose
Stereo relative pose from line and point feature triplets
Jun 29, 2019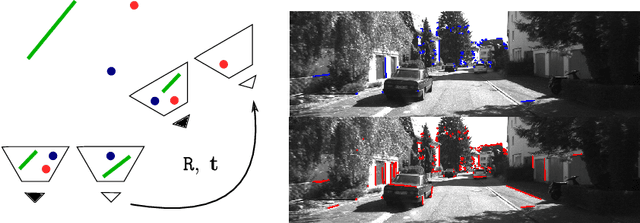
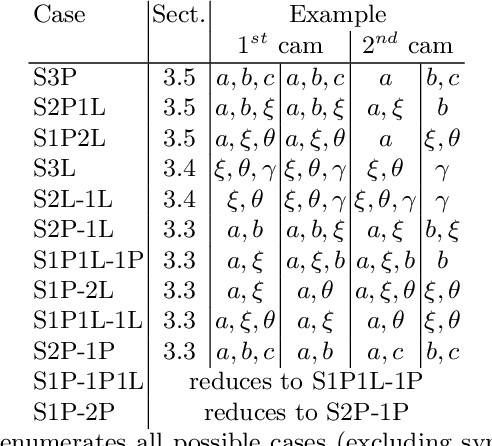

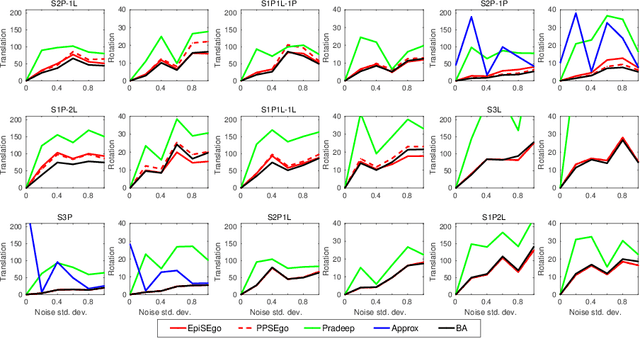
Stereo relative pose problem lies at the core of stereo visual odometry systems that are used in many applications. In this work, we present two minimal solvers for the stereo relative pose. We specifically consider the case when a minimal set consists of three point or line features and each of them has three known projections on two stereo cameras. We validate the importance of this formulation for practical purposes in our experiments with motion estimation. We then present a complete classification of minimal cases with three point or line correspondences each having three projections, and present two new solvers that can handle all such cases. We demonstrate a considerable effect from the integration of the new solvers into a visual SLAM system.
Textured Neural Avatars
May 21, 2019
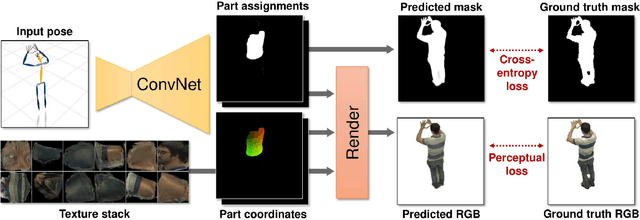


We present a system for learning full-body neural avatars, i.e. deep networks that produce full-body renderings of a person for varying body pose and camera position. Our system takes the middle path between the classical graphics pipeline and the recent deep learning approaches that generate images of humans using image-to-image translation. In particular, our system estimates an explicit two-dimensional texture map of the model surface. At the same time, it abstains from explicit shape modeling in 3D. Instead, at test time, the system uses a fully-convolutional network to directly map the configuration of body feature points w.r.t. the camera to the 2D texture coordinates of individual pixels in the image frame. We show that such a system is capable of learning to generate realistic renderings while being trained on videos annotated with 3D poses and foreground masks. We also demonstrate that maintaining an explicit texture representation helps our system to achieve better generalization compared to systems that use direct image-to-image translation.
Coordinate-based Texture Inpainting for Pose-Guided Image Generation
Nov 28, 2018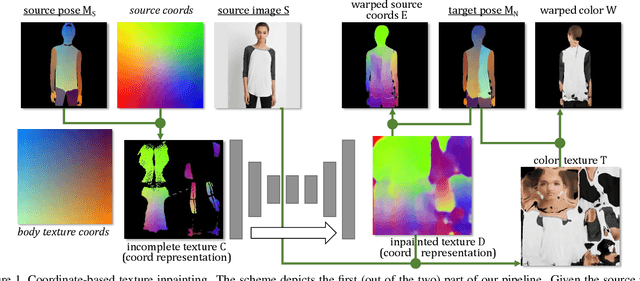



We present a new deep learning approach to pose-guided resynthesis of human photographs. At the heart of the new approach is the estimation of the complete body surface texture based on a single photograph. Since the input photograph always observes only a part of the surface, we suggest a new inpainting method that completes the texture of the human body. Rather than working directly with colors of texture elements, the inpainting network estimates an appropriate source location in the input image for each element of the body surface. This correspondence field between the input image and the texture is then further warped into the target image coordinate frame based on the desired pose, effectively establishing the correspondence between the source and the target view even when the pose change is drastic. The final convolutional network then uses the established correspondence and all other available information to synthesize the output image using a fully-convolutional architecture with deformable convolutions. We show the state-of-the-art result for pose-guided image synthesis. Additionally, we demonstrate the performance of our system for garment transfer and pose-guided face resynthesis.