 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Keypoints for the Two-View Geometry Estimation Problem
Mar 24, 2025



Local features are essential to many modern downstream applications. Therefore, it is of interest to determine the properties of local features that contribute to the downstream performance for a better design of feature detectors and descriptors. In our work, we propose a new theoretical model for scoring feature points (keypoints) in the context of the two-view geometry estimation problem. The model determines two properties that a good keypoint for solving the homography estimation problem should have: be repeatable and have a small expected measurement error. This result provides key insights into why maximizing the number of correspondences doesn't always lead to better homography estimation accuracy. We use the developed model to design a method that detects keypoints that benefit the homography estimation introducing the Bounded NeSS-ST (BoNeSS-ST) keypoint detector. The novelty of BoNeSS-ST comes from strong theoretical foundations, a more accurate keypoint scoring due to subpixel refinement and a cost designed for superior robustness to low saliency keypoints. As a result, BoNeSS-ST outperforms prior self-supervised local feature detectors in both planar homography and epipolar geometry estimation problems.
Shi-NeSS: Detecting Good and Stable Keypoints with a Neural Stability Score
Jul 03, 2023
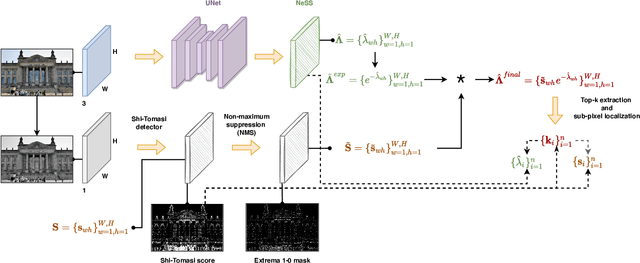

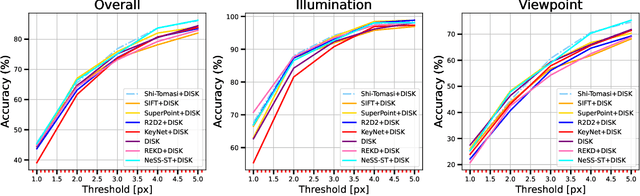
Learning a feature point detector presents a challenge both due to the ambiguity of the definition of a keypoint and correspondingly the need for a specially prepared ground truth labels for such points. In our work, we address both of these issues by utilizing a combination of a hand-crafted Shi detector and a neural network. We build on the principled and localized keypoints provided by the Shi detector and perform their selection using the keypoint stability score regressed by the neural network - Neural Stability Score (NeSS). Therefore, our method is named Shi-NeSS since it combines the Shi detector and the properties of the keypoint stability score, and it only requires for training sets of images without dataset pre-labeling or the need for reconstructed correspondence labels. We evaluate Shi-NeSS on HPatches, ScanNet, MegaDepth and IMC-PT, demonstrating state-of-the-art performance and good generalization on downstream tasks.
SmartPortraits: Depth Powered Handheld Smartphone Dataset of Human Portraits for State Estimation, Reconstruction and Synthesis
Apr 21, 2022


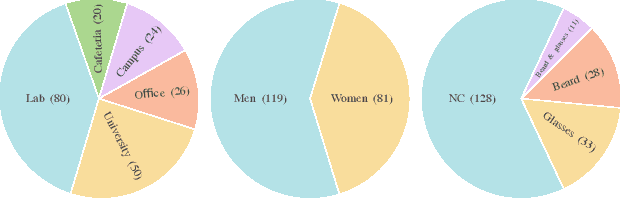
We present a dataset of 1000 video sequences of human portraits recorded in real and uncontrolled conditions by using a handheld smartphone accompanied by an external high-quality depth camera. The collected dataset contains 200 people captured in different poses and locations and its main purpose is to bridge the gap between raw measurements obtained from a smartphone and downstream applications, such as state estimation, 3D reconstruction, view synthesis, etc. The sensors employed in data collection are the smartphone's camera and Inertial Measurement Unit (IMU), and an external Azure Kinect DK depth camera software synchronized with sub-millisecond precision to the smartphone system. During the recording, the smartphone flash is used to provide a periodic secondary source of lightning. Accurate mask of the foremost person is provided as well as its impact on the camera alignment accuracy. For evaluation purposes, we compare multiple state-of-the-art camera alignment methods by using a Motion Capture system. We provide a smartphone visual-inertial benchmark for portrait capturing, where we report results for multiple methods and motivate further use of the provided trajectories, available in the dataset, in view synthesis and 3D reconstruction tasks.
Synchronized Smartphone Video Recording System of Depth and RGB Image Frames with Sub-millisecond Precision
Nov 05, 2021

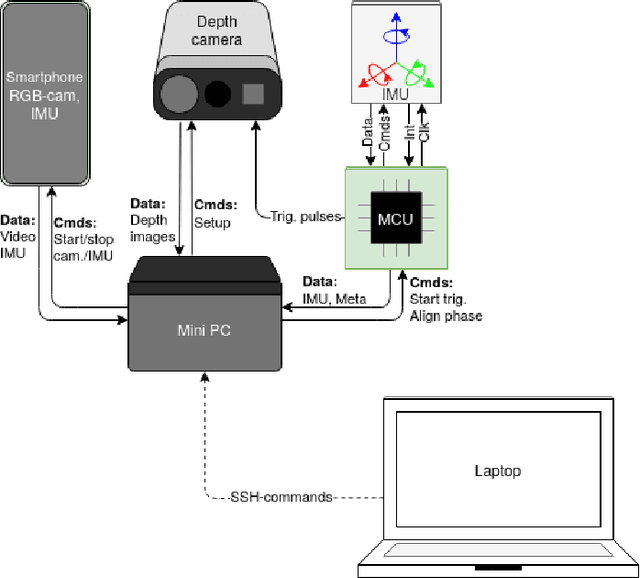
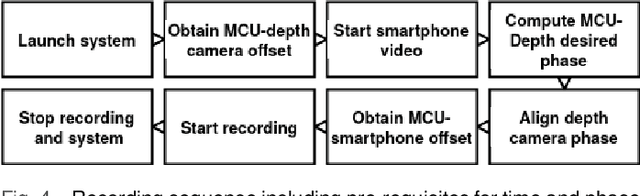
In this paper, we propose a recording system with high time synchronization (sync) precision which consists of heterogeneous sensors such as smartphone, depth camera, IMU, etc. Due to the general interest and mass adoption of smartphones, we include at least one of such devices into our system. This heterogeneous system requires a hybrid synchronization for the two different time authorities: smartphone and MCU, where we combine a hardware wired-based trigger sync with software sync. We evaluate our sync results on a custom and novel system mixing active infra-red depth with RGB camera. Our system achieves sub-millisecond precision of time sync. Moreover, our system exposes every RGB-depth image pair at the same time with this precision. We showcase a configuration in particular but the general principles behind our system could be replicated by other projects.