 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-KnG: Visual Scene Understanding for Navigation Goal Identification using Spatiotemporal Knowledge Graphs
Oct 01, 2025
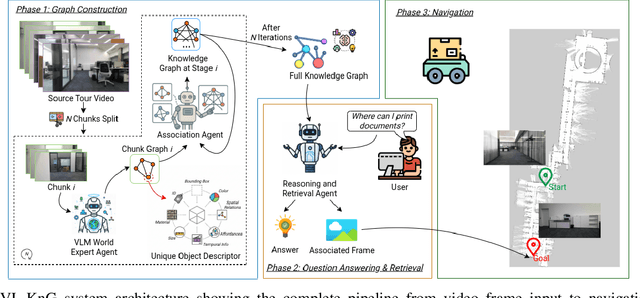
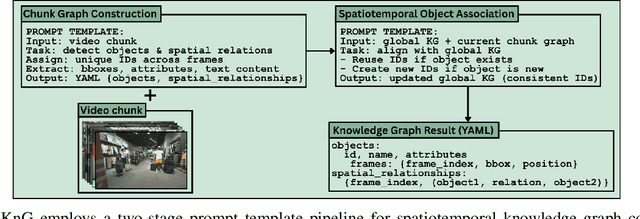
Vision-language models (VLMs) have shown potential for robot navigation but encounter fundamental limitations: they lack persistent scene memory, offer limited spatial reasoning, and do not scale effectively with video duration for real-time application. We present VL-KnG, a Visual Scene Understanding system that tackles these challenges using spatiotemporal knowledge graph construction and computationally efficient query processing for navigation goal identification. Our approach processes video sequences in chunks utilizing modern VLMs, creates persistent knowledge graphs that maintain object identity over time, and enables explainable spatial reasoning through queryable graph structures. We also introduce WalkieKnowledge, a new benchmark with about 200 manually annotated questions across 8 diverse trajectories spanning approximately 100 minutes of video data, enabling fair comparison between structured approaches and general-purpose VLMs. Real-world deployment on a differential drive robot demonstrates practical applicability, with our method achieving 77.27% success rate and 76.92% answer accuracy, matching Gemini 2.5 Pro performance while providing explainable reasoning supported by the knowledge graph, computational efficiency for real-time deployment across different tasks, such as localization, navigation and planning. Code and dataset will be released after acceptance.
PixelNav: Towards Model-based Vision-Only Navigation with Topological Graphs
Jul 28, 2025



This work proposes a novel hybrid approach for vision-only navigation of mobile robots, which combines advances of both deep learning approaches and classical model-based planning algorithms. Today, purely data-driven end-to-end models are dominant solutions to this problem. Despite advantages such as flexibility and adaptability, the requirement of a large amount of training data and limited interpretability are the main bottlenecks for their practical applications. To address these limitations, we propose a hierarchical system that utilizes recent advances in model predictive control, traversability estimation, visual place recognition, and pose estimation, employing topological graphs as a representation of the target environment. Using such a combination, we provide a scalable system with a higher level of interpretability compared to end-to-end approaches. Extensive real-world experiments show the efficiency of the proposed method.
EgoWalk: A Multimodal Dataset for Robot Navigation in the Wild
May 27, 2025Data-driven navigation algorithms are critically dependent on large-scale, high-quality real-world data collection for successful training and robust performance in realistic and uncontrolled conditions. To enhance the growing family of navigation-related real-world datasets, we introduce EgoWalk - a dataset of 50 hours of human navigation in a diverse set of indoor/outdoor, varied seasons, and location environments. Along with the raw and Imitation Learning-ready data, we introduce several pipelines to automatically create subsidiary datasets for other navigation-related tasks, namely natural language goal annotations and traversability segmentation masks. Diversity studies, use cases, and benchmarks for the proposed dataset are provided to demonstrate its practical applicability. We openly release all data processing pipelines and the description of the hardware platform used for data collection to support future research and development in robot navigation systems.
Good Keypoints for the Two-View Geometry Estimation Problem
Mar 24, 2025



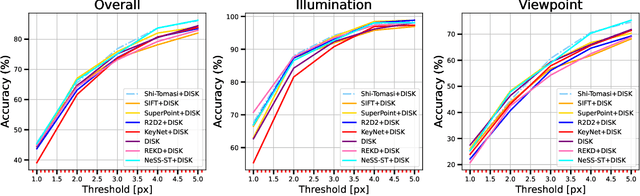
Local features are essential to many modern downstream applications. Therefore, it is of interest to determine the properties of local features that contribute to the downstream performance for a better design of feature detectors and descriptors. In our work, we propose a new theoretical model for scoring feature points (keypoints) in the context of the two-view geometry estimation problem. The model determines two properties that a good keypoint for solving the homography estimation problem should have: be repeatable and have a small expected measurement error. This result provides key insights into why maximizing the number of correspondences doesn't always lead to better homography estimation accuracy. We use the developed model to design a method that detects keypoints that benefit the homography estimation introducing the Bounded NeSS-ST (BoNeSS-ST) keypoint detector. The novelty of BoNeSS-ST comes from strong theoretical foundations, a more accurate keypoint scoring due to subpixel refinement and a cost designed for superior robustness to low saliency keypoints. As a result, BoNeSS-ST outperforms prior self-supervised local feature detectors in both planar homography and epipolar geometry estimation problems.
GSLoc: Visual Localization with 3D Gaussian Splatting
Oct 08, 2024

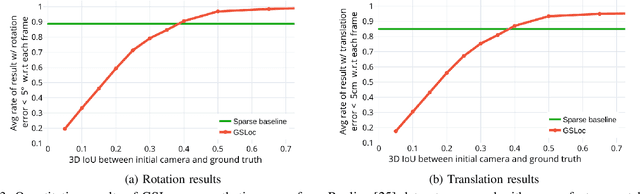
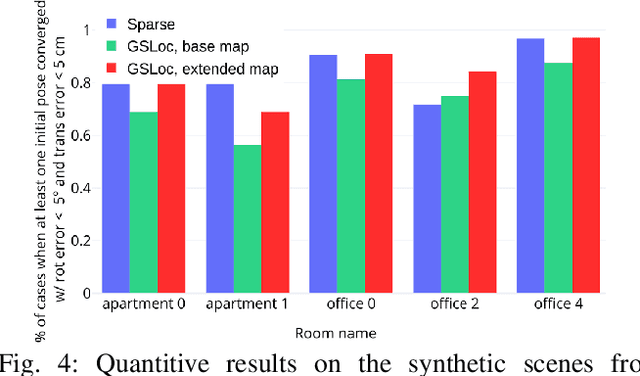
We present GSLoc: a new visual localization method that performs dense camera alignment using 3D Gaussian Splatting as a map representation of the scene. GSLoc backpropagates pose gradients over the rendering pipeline to align the rendered and target images, while it adopts a coarse-to-fine strategy by utilizing blurring kernels to mitigate the non-convexity of the problem and improve the convergence. The results show that our approach succeeds at visual localization in challenging conditions of relatively small overlap between initial and target frames inside textureless environments when state-of-the-art neural sparse methods provide inferior results. Using the byproduct of realistic rendering from the 3DGS map representation, we show how to enhance localization results by mixing a set of observed and virtual reference keyframes when solving the image retrieval problem. We evaluate our method both on synthetic and real-world data, discussing its advantages and application potential.
Visual place recognition for aerial imagery: A survey
Jun 02, 2024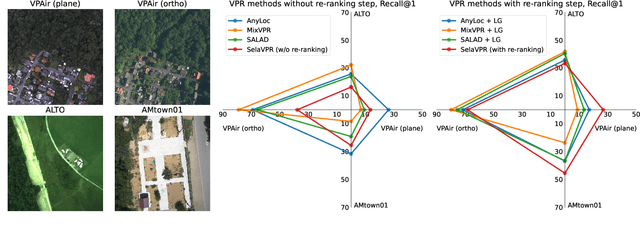
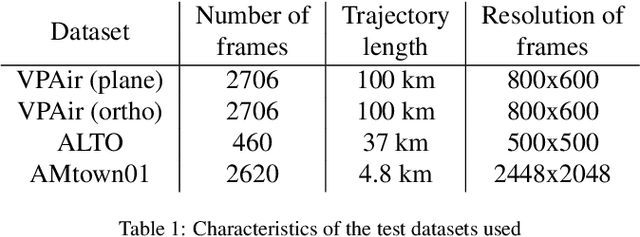
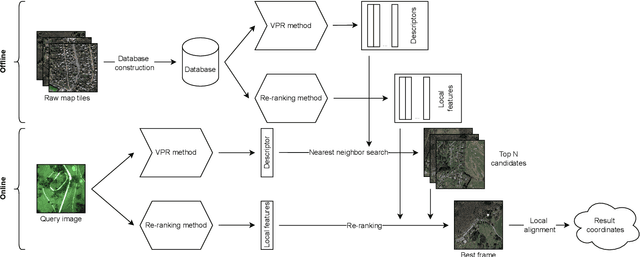
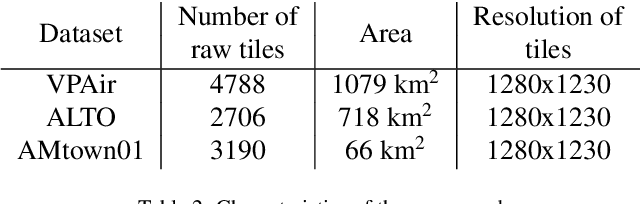
Aerial imagery and its direct application to visual localization is an essential problem for many Robotics and Computer Vision tasks. While Global Navigation Satellite Systems (GNSS) are the standard default solution for solving the aerial localization problem, it is subject to a number of limitations, such as, signal instability or solution unreliability that make this option not so desirable. Consequently, visual geolocalization is emerging as a viable alternative. However, adapting Visual Place Recognition (VPR) task to aerial imagery presents significant challenges, including weather variations and repetitive patterns. Current VPR reviews largely neglect the specific context of aerial data. This paper introduces a methodology tailored for evaluating VPR techniques specifically in the domain of aerial imagery, providing a comprehensive assessment of various methods and their performance. However, we not only compare various VPR methods, but also demonstrate the importance of selecting appropriate zoom and overlap levels when constructing map tiles to achieve maximum efficiency of VPR algorithms in the case of aerial imagery. The code is available on our GitHub repository -- https://github.com/prime-slam/aero-vloc.
Mapping the Unseen: Unified Promptable Panoptic Mapping with Dynamic Labeling using Foundation Models
May 03, 2024In the field of robotics and computer vision, efficient and accurate semantic mapping remains a significant challenge due to the growing demand for intelligent machines that can comprehend and interact with complex environments. Conventional panoptic mapping methods, however, are limited by predefined semantic classes, thus making them ineffective for handling novel or unforeseen objects. In response to this limitation, we introduce the Unified Promptable Panoptic Mapping (UPPM) method. UPPM utilizes recent advances in foundation models to enable real-time, on-demand label generation using natural language prompts. By incorporating a dynamic labeling strategy into traditional panoptic mapping techniques, UPPM provides significant improvements in adaptability and versatility while maintaining high performance levels in map reconstruction. We demonstrate our approach on real-world and simulated datasets. Results show that UPPM can accurately reconstruct scenes and segment objects while generating rich semantic labels through natural language interactions. A series of ablation experiments validated the advantages of foundation model-based labeling over fixed label sets.
Shi-NeSS: Detecting Good and Stable Keypoints with a Neural Stability Score
Jul 03, 2023
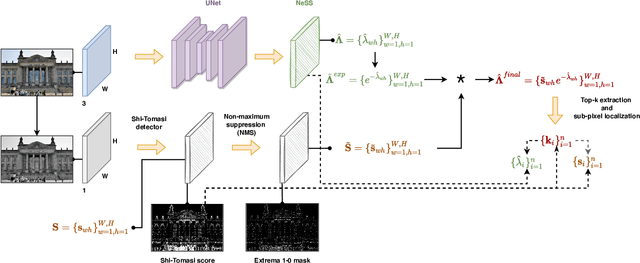

Learning a feature point detector presents a challenge both due to the ambiguity of the definition of a keypoint and correspondingly the need for a specially prepared ground truth labels for such points. In our work, we address both of these issues by utilizing a combination of a hand-crafted Shi detector and a neural network. We build on the principled and localized keypoints provided by the Shi detector and perform their selection using the keypoint stability score regressed by the neural network - Neural Stability Score (NeSS). Therefore, our method is named Shi-NeSS since it combines the Shi detector and the properties of the keypoint stability score, and it only requires for training sets of images without dataset pre-labeling or the need for reconstructed correspondence labels. We evaluate Shi-NeSS on HPatches, ScanNet, MegaDepth and IMC-PT, demonstrating state-of-the-art performance and good generalization on downstream tasks.
Social Robot Navigation through Constrained Optimization: a Comparative Study of Uncertainty-based Objectives and Constraints
May 04, 2023This work is dedicated to the study of how uncertainty estimation of the human motion prediction can be embedded into constrained optimization techniques, such as Model Predictive Control (MPC) for the social robot navigation. We propose several cost objectives and constraint functions obtained from the uncertainty of predicting pedestrian positions and related to the probability of the collision that can be applied to the MPC, and all the different variants are compared in challenging scenes with multiple agents. The main question this paper tries to answer is: what are the most important uncertainty-based criteria for social MPC? For that, we evaluate the proposed approaches with several social navigation metrics in an extensive set of scenarios of different complexity in reproducible synthetic environments. The main outcome of our study is a foundation for a practical guide on when and how to use uncertainty-aware approaches for social robot navigation in practice and what are the most effective criteria.
TT-SDF2PC: Registration of Point Cloud and Compressed SDF Directly in the Memory-Efficient Tensor Train Domain
Apr 11, 2023



This paper addresses the following research question: ``can one compress a detailed 3D representation and use it directly for point cloud registration?''. Map compression of the scene can be achieved by the tensor train (TT) decomposition of the signed distance function (SDF) representation. It regulates the amount of data reduced by the so-called TT-ranks. Using this representation we have proposed an algorithm, the TT-SDF2PC, that is capable of directly registering a PC to the compressed SDF by making use of efficient calculations of its derivatives in the TT domain, saving computations and memory. We compare TT-SDF2PC with SOTA local and global registration methods in a synthetic dataset and a real dataset and show on par performance while requiring significantly less resources.