 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThegra: Graph-based SLAM for Thermal Imagery
Feb 09, 2026Thermal imaging provides a practical sensing modality for visual SLAM in visually degraded environments such as low illumination, smoke, or adverse weather. However, thermal imagery often exhibits low texture, low contrast, and high noise, complicating feature-based SLAM. In this work, we propose a sparse monocular graph-based SLAM system for thermal imagery that leverages general-purpose learned features -- the SuperPoint detector and LightGlue matcher, trained on large-scale visible-spectrum data to improve cross-domain generalization. To adapt these components to thermal data, we introduce a preprocessing pipeline to enhance input suitability and modify core SLAM modules to handle sparse and outlier-prone feature matches. We further incorporate keypoint confidence scores from SuperPoint into a confidence-weighted factor graph to improve estimation robustness. Evaluations on public thermal datasets demonstrate that the proposed system achieves reliable performance without requiring dataset-specific training or fine-tuning a desired feature detector, given the scarcity of quality thermal data. Code will be made available upon publication.
Visual place recognition for aerial imagery: A survey
Jun 02, 2024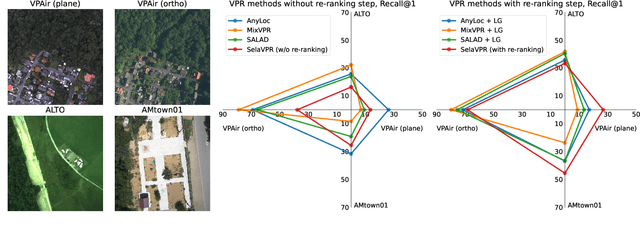
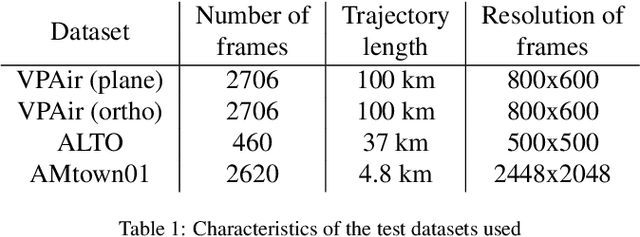
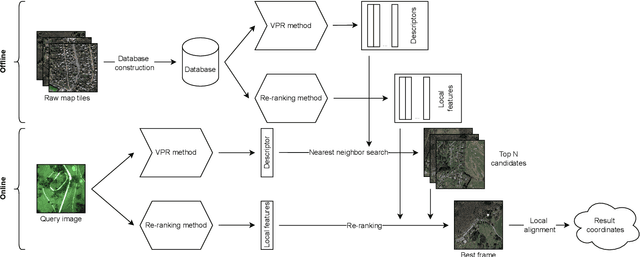
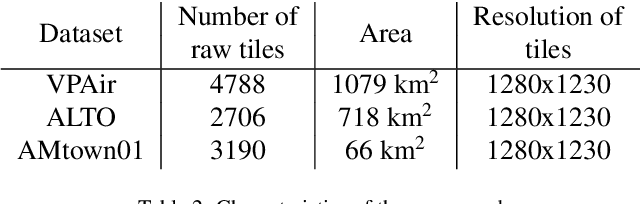
Aerial imagery and its direct application to visual localization is an essential problem for many Robotics and Computer Vision tasks. While Global Navigation Satellite Systems (GNSS) are the standard default solution for solving the aerial localization problem, it is subject to a number of limitations, such as, signal instability or solution unreliability that make this option not so desirable. Consequently, visual geolocalization is emerging as a viable alternative. However, adapting Visual Place Recognition (VPR) task to aerial imagery presents significant challenges, including weather variations and repetitive patterns. Current VPR reviews largely neglect the specific context of aerial data. This paper introduces a methodology tailored for evaluating VPR techniques specifically in the domain of aerial imagery, providing a comprehensive assessment of various methods and their performance. However, we not only compare various VPR methods, but also demonstrate the importance of selecting appropriate zoom and overlap levels when constructing map tiles to achieve maximum efficiency of VPR algorithms in the case of aerial imagery. The code is available on our GitHub repository -- https://github.com/prime-slam/aero-vloc.
DeepMIF: Deep Monotonic Implicit Fields for Large-Scale LiDAR 3D Mapping
Mar 26, 2024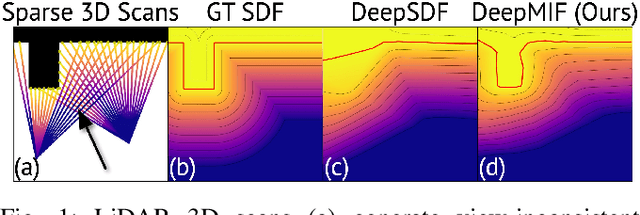
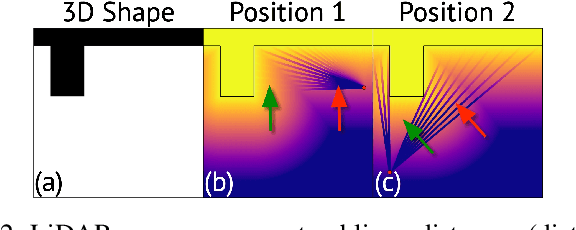
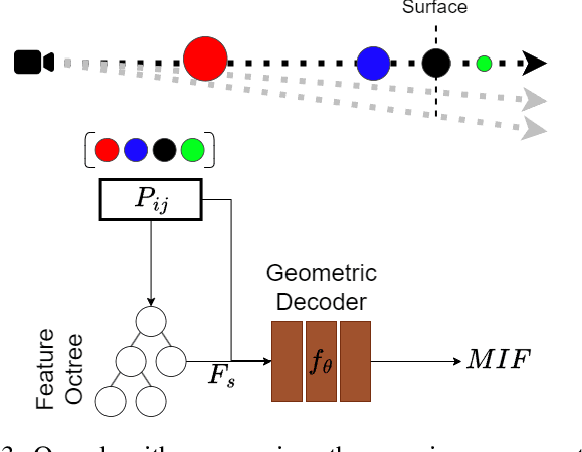

Recently, significant progress has been achieved in sensing real large-scale outdoor 3D environments, particularly by using modern acquisition equipment such as LiDAR sensors. Unfortunately, they are fundamentally limited in their ability to produce dense, complete 3D scenes. To address this issue, recent learning-based methods integrate neural implicit representations and optimizable feature grids to approximate surfaces of 3D scenes. However, naively fitting samples along raw LiDAR rays leads to noisy 3D mapping results due to the nature of sparse, conflicting LiDAR measurements. Instead, in this work we depart from fitting LiDAR data exactly, instead letting the network optimize a non-metric monotonic implicit field defined in 3D space. To fit our field, we design a learning system integrating a monotonicity loss that enables optimizing neural monotonic fields and leverages recent progress in large-scale 3D mapping. Our algorithm achieves high-quality dense 3D mapping performance as captured by multiple quantitative and perceptual measures and visual results obtained for Mai City, Newer College, and KITTI benchmarks. The code of our approach will be made publicly available.
AutoInst: Automatic Instance-Based Segmentation of LiDAR 3D Scans
Mar 24, 2024



Recently, progress in acquisition equipment such as LiDAR sensors has enabled sensing increasingly spacious outdoor 3D environments. Making sense of such 3D acquisitions requires fine-grained scene understanding, such as constructing instance-based 3D scene segmentations. Commonly, a neural network is trained for this task; however, this requires access to a large, densely annotated dataset, which is widely known to be challenging to obtain. To address this issue, in this work we propose to predict instance segmentations for 3D scenes in an unsupervised way, without relying on ground-truth annotations. To this end, we construct a learning framework consisting of two components: (1) a pseudo-annotation scheme for generating initial unsupervised pseudo-labels; and (2) a self-training algorithm for instance segmentation to fit robust, accurate instances from initial noisy proposals. To enable generating 3D instance mask proposals, we construct a weighted proxy-graph by connecting 3D points with edges integrating multi-modal image- and point-based self-supervised features, and perform graph-cuts to isolate individual pseudo-instances. We then build on a state-of-the-art point-based architecture and train a 3D instance segmentation model, resulting in significant refinement of initial proposals. To scale to arbitrary complexity 3D scenes, we design our algorithm to operate on local 3D point chunks and construct a merging step to generate scene-level instance segmentations. Experiments on the challenging SemanticKITTI benchmark demonstrate the potential of our approach, where it attains 13.3% higher Average Precision and 9.1% higher F1 score compared to the best-performing baseline. The code will be made publicly available at https://github.com/artonson/autoinst.
Uplift Modeling: from Causal Inference to Personalization
Aug 17, 2023Uplift modeling is a collection of machine learning techniques for estimating causal effects of a treatment at the individual or subgroup levels. Over the last years, causality and uplift modeling have become key trends in personalization at online e-commerce platforms, enabling the selection of the best treatment for each user in order to maximize the target business metric. Uplift modeling can be particularly useful for personalized promotional campaigns, where the potential benefit caused by a promotion needs to be weighed against the potential costs. In this tutorial we will cover basic concepts of causality and introduce the audience to state-of-the-art techniques in uplift modeling. We will discuss the advantages and the limitations of different approaches and dive into the unique setup of constrained uplift modeling. Finally, we will present real-life applications and discuss challenges in implementing these models in production.
TT-SDF2PC: Registration of Point Cloud and Compressed SDF Directly in the Memory-Efficient Tensor Train Domain
Apr 11, 2023



This paper addresses the following research question: ``can one compress a detailed 3D representation and use it directly for point cloud registration?''. Map compression of the scene can be achieved by the tensor train (TT) decomposition of the signed distance function (SDF) representation. It regulates the amount of data reduced by the so-called TT-ranks. Using this representation we have proposed an algorithm, the TT-SDF2PC, that is capable of directly registering a PC to the compressed SDF by making use of efficient calculations of its derivatives in the TT domain, saving computations and memory. We compare TT-SDF2PC with SOTA local and global registration methods in a synthetic dataset and a real dataset and show on par performance while requiring significantly less resources.
Eigen-Factors an Alternating Optimization for Back-end Plane SLAM of 3D Point Clouds
Apr 03, 2023Modern depth sensors can generate a huge number of 3D points in few seconds to be latter processed by Localization and Mapping algorithms. Ideally, these algorithms should handle efficiently large sizes of Point Clouds under the assumption that using more points implies more information available. The Eigen Factors (EF) is a new algorithm that solves SLAM by using planes as the main geometric primitive. To do so, EF exhaustively calculates the error of all points at complexity $O(1)$, thanks to the {\em Summation matrix} $S$ of homogeneous points. The solution of EF is highly efficient: i) the state variables are only the sensor poses -- trajectory, while the plane parameters are estimated previously in closed from and ii) EF alternating optimization uses a Newton-Raphson method by a direct analytical calculation of the gradient and the Hessian, which turns out to be a block diagonal matrix. Since we require to differentiate over eigenvalues and matrix elements, we have developed an intuitive methodology to calculate partial derivatives in the manifold of rigid body transformations $SE(3)$, which could be applied to unrelated problems that require analytical derivatives of certain complexity. We evaluate EF and other state-of-the-art plane SLAM back-end algorithms in a synthetic environment. The evaluation is extended to ICL dataset (RGBD) and LiDAR KITTI dataset. Code is publicly available at https://github.com/prime-slam/EF-plane-SLAM.
EVOLIN Benchmark: Evaluation of Line Detection and Association
Mar 09, 2023



Lines are interesting geometrical features commonly seen in indoor and urban environments. There is missing a complete benchmark where one can evaluate lines from a sequential stream of images in all its stages: Line detection, Line Association and Pose error. To do so, we present a complete and exhaustive benchmark for visual lines in a SLAM front-end, both for RGB and RGBD, by providing a plethora of complementary metrics. We have also labelled data from well-known SLAM datasets in order to have all in one poses and accurately annotated lines. In particular, we have evaluated 17 line detection algorithms, 5 line associations methods and the resultant pose error for aligning a pair of frames with several combinations of detector-association. We have packaged all methods and evaluations metrics and made them publicly available on web-page https://prime-slam.github.io/evolin/.
Dominating Set Database Selection for Visual Place Recognition
Mar 09, 2023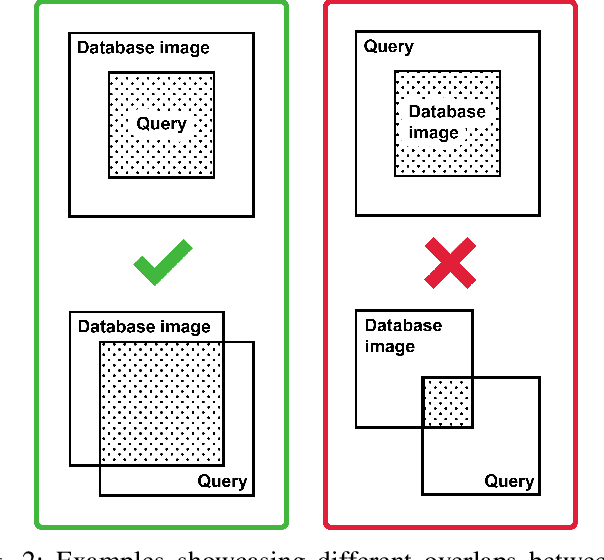

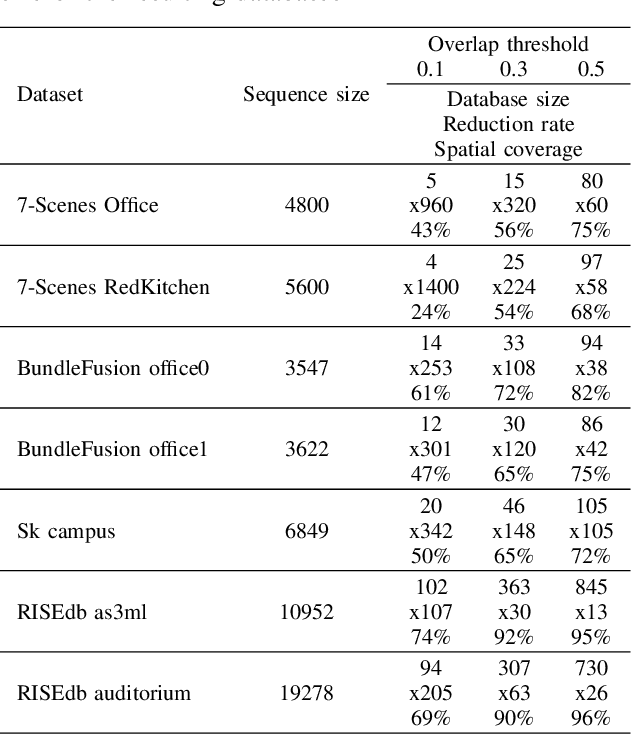

This paper presents an approach for creating a visual place recognition (VPR) database for localization in indoor environments from RGBD scanning sequences. The proposed approach is formulated as a minimization problem in terms of dominating set algorithm for graph, constructed from spatial information, and referred as DominatingSet. Our algorithm shows better scene coverage in comparison to other methodologies that are used for database creation. Also, we demonstrate that using DominatingSet, a database size could be up to 250-1400 times smaller than the original scanning sequence while maintaining a recall rate of more than 80% on testing sequences. We evaluated our algorithm on 7-scenes and BundleFusion datasets and an additionally recorded sequence in a highly repetitive office setting. In addition, the database selection can produce weakly-supervised labels for fine-tuning neural place recognition algorithms to particular settings, improving even more their accuracy. The paper also presents a fully automated pipeline for VPR database creation from RGBD scanning sequences, as well as a set of metrics for VPR database evaluation. The code and released data are available on our web-page~ -- https://prime-slam.github.io/place-recognition-db/
SmartPortraits: Depth Powered Handheld Smartphone Dataset of Human Portraits for State Estimation, Reconstruction and Synthesis
Apr 21, 2022


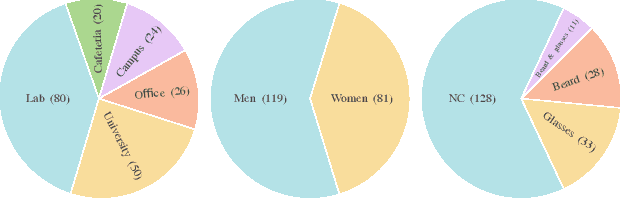
We present a dataset of 1000 video sequences of human portraits recorded in real and uncontrolled conditions by using a handheld smartphone accompanied by an external high-quality depth camera. The collected dataset contains 200 people captured in different poses and locations and its main purpose is to bridge the gap between raw measurements obtained from a smartphone and downstream applications, such as state estimation, 3D reconstruction, view synthesis, etc. The sensors employed in data collection are the smartphone's camera and Inertial Measurement Unit (IMU), and an external Azure Kinect DK depth camera software synchronized with sub-millisecond precision to the smartphone system. During the recording, the smartphone flash is used to provide a periodic secondary source of lightning. Accurate mask of the foremost person is provided as well as its impact on the camera alignment accuracy. For evaluation purposes, we compare multiple state-of-the-art camera alignment methods by using a Motion Capture system. We provide a smartphone visual-inertial benchmark for portrait capturing, where we report results for multiple methods and motivate further use of the provided trajectories, available in the dataset, in view synthesis and 3D reconstruction tasks.