 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetalearners for Ranking Treatment Effects
May 03, 2024
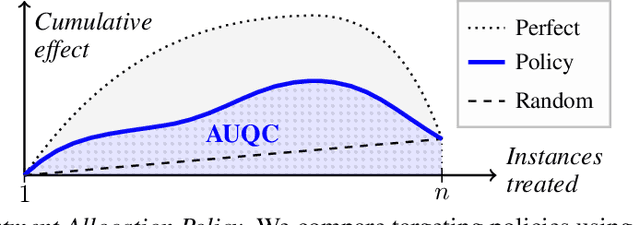

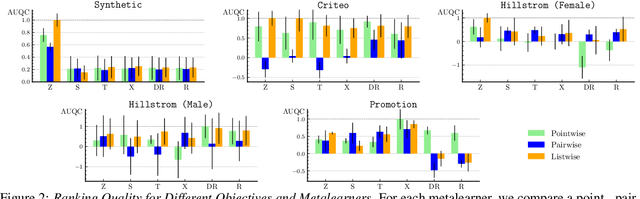
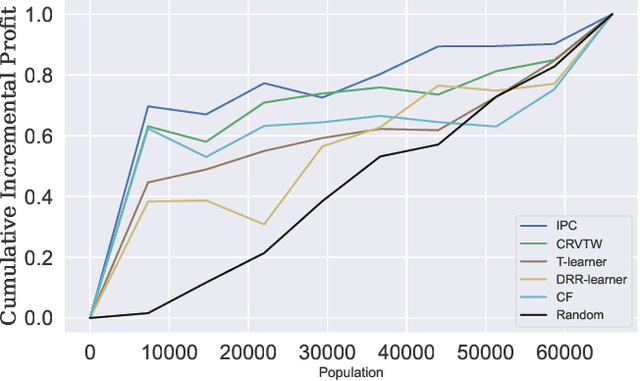
Efficiently allocating treatments with a budget constraint constitutes an important challenge across various domains. In marketing, for example, the use of promotions to target potential customers and boost conversions is limited by the available budget. While much research focuses on estimating causal effects, there is relatively limited work on learning to allocate treatments while considering the operational context. Existing methods for uplift modeling or causal inference primarily estimate treatment effects, without considering how this relates to a profit maximizing allocation policy that respects budget constraints. The potential downside of using these methods is that the resulting predictive model is not aligned with the operational context. Therefore, prediction errors are propagated to the optimization of the budget allocation problem, subsequently leading to a suboptimal allocation policy. We propose an alternative approach based on learning to rank. Our proposed methodology directly learns an allocation policy by prioritizing instances in terms of their incremental profit. We propose an efficient sampling procedure for the optimization of the ranking model to scale our methodology to large-scale data sets. Theoretically, we show how learning to rank can maximize the area under a policy's incremental profit curve. Empirically, we validate our methodology and show its effectiveness in practice through a series of experiments on both synthetic and real-world data.
Uplift Modeling: from Causal Inference to Personalization
Aug 17, 2023Uplift modeling is a collection of machine learning techniques for estimating causal effects of a treatment at the individual or subgroup levels. Over the last years, causality and uplift modeling have become key trends in personalization at online e-commerce platforms, enabling the selection of the best treatment for each user in order to maximize the target business metric. Uplift modeling can be particularly useful for personalized promotional campaigns, where the potential benefit caused by a promotion needs to be weighed against the potential costs. In this tutorial we will cover basic concepts of causality and introduce the audience to state-of-the-art techniques in uplift modeling. We will discuss the advantages and the limitations of different approaches and dive into the unique setup of constrained uplift modeling. Finally, we will present real-life applications and discuss challenges in implementing these models in production.
Incremental Profit per Conversion: a Response Transformation for Uplift Modeling in E-Commerce Promotions
Jun 23, 2023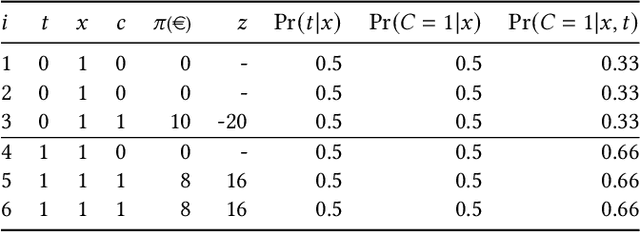
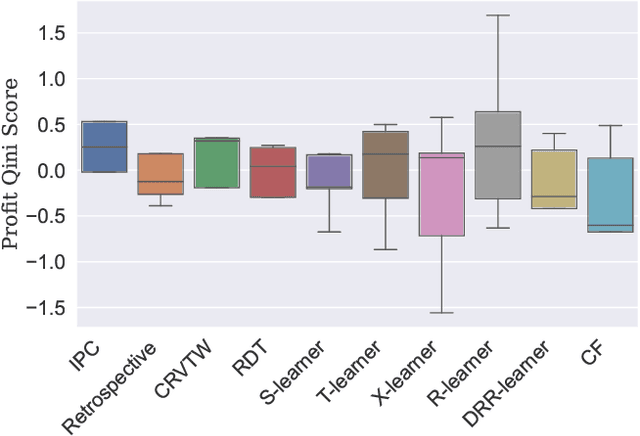
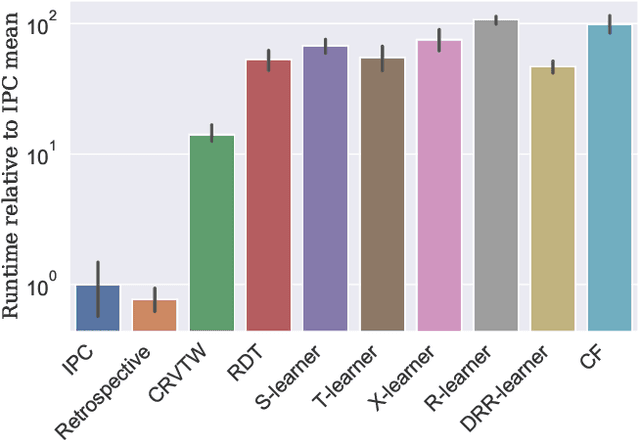
Promotions play a crucial role in e-commerce platforms, and various cost structures are employed to drive user engagement. This paper focuses on promotions with response-dependent costs, where expenses are incurred only when a purchase is made. Such promotions include discounts and coupons. While existing uplift model approaches aim to address this challenge, these approaches often necessitate training multiple models, like meta-learners, or encounter complications when estimating profit due to zero-inflated values stemming from non-converted individuals with zero cost and profit. To address these challenges, we introduce Incremental Profit per Conversion (IPC), a novel uplift measure of promotional campaigns' efficiency in unit economics. Through a proposed response transformation, we demonstrate that IPC requires only converted data, its propensity, and a single model to be estimated. As a result, IPC resolves the issues mentioned above while mitigating the noise typically associated with the class imbalance in conversion datasets and biases arising from the many-to-one mapping between search and purchase data. Lastly, we validate the efficacy of our approach by presenting results obtained from a synthetic simulation of a discount coupon campaign.
Robust subgroup discovery
Mar 25, 2021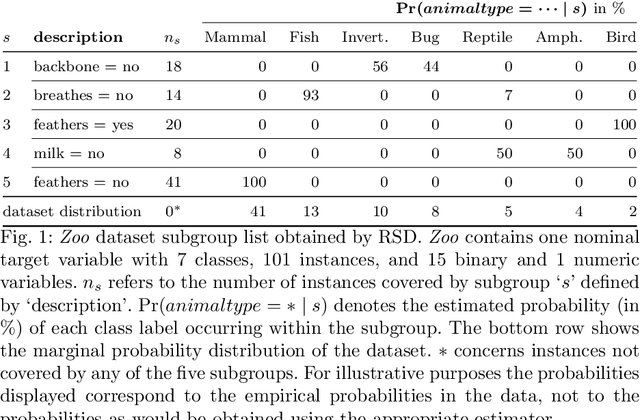
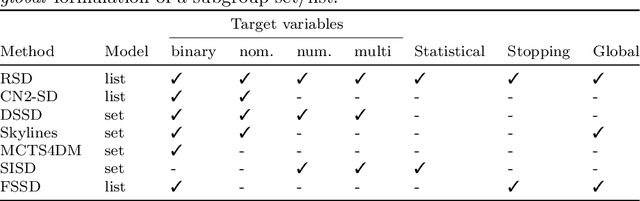


We introduce the problem of robust subgroup discovery, i.e., finding a set of interpretable descriptions of subsets that 1) stand out with respect to one or more target attributes, 2) are statistically robust, and 3) non-redundant. Many attempts have been made to mine either locally robust subgroups or to tackle the pattern explosion, but we are the first to address both challenges at the same time from a global perspective. First, we formulate a broad model class of subgroup lists, i.e., ordered sets of subgroups, for univariate and multivariate targets that can consist of nominal or numeric variables. This novel model class allows us to formalize the problem of optimal robust subgroup discovery using the Minimum Description Length (MDL) principle, where we resort to optimal Normalized Maximum Likelihood and Bayesian encodings for nominal and numeric targets, respectively. Notably, we show that our problem definition is equal to mining the top-1 subgroup with an information-theoretic quality measure plus a penalty for complexity. Second, as finding optimal subgroup lists is NP-hard, we propose RSD, a greedy heuristic that finds good subgroup lists and guarantees that the most significant subgroup found according to the MDL criterion is added in each iteration, which is shown to be equivalent to a Bayesian one-sample proportions, multinomial, or t-test between the subgroup and dataset marginal target distributions plus a multiple hypothesis testing penalty. We empirically show on 54 datasets that RSD outperforms previous subgroup set discovery methods in terms of quality and subgroup list size.