 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-OptBench: A Solver-Grounded Benchmark for Multimodal Optimization Modeling
May 12, 2026Optimization modeling translates real decision-making problems into mathematical optimization models and solver-executable implementations. Although language models are increasingly used to generate optimization formulations and solver code, existing benchmarks are almost entirely text-only. This omits many optimization-modeling tasks that arise in operational practice, where requirements are described in text but instance information is conveyed through visual artifacts such as tables, graphs, maps, schedules, and dashboards. We introduce multimodal optimization modeling, a benchmark setting in which models must construct both a mathematical formulation and executable solver code from a text-and-visual problem specification. To evaluate this setting, we develop a solver-grounded framework that generates structured optimization instances, verifies each with an exact solver, and builds both the model-facing inputs and hidden reference files from the same verified source. We instantiate the framework as MM-OptBench, a benchmark of 780 solver-verified instances spanning 6 optimization families, 26 subcategories, and 3 structural difficulty levels. We evaluate 9 multimodal large language models (MLLMs), including 6 frontier general-purpose models and 3 math-specialized models, with aggregate, family-level, difficulty-level, and failure-mode analyses. The results show that the task remains far from solved: the best two models reach 52.1% and 51.3% pass@1, while on average across the six general-purpose MLLMs, pass@1 is 43.4% on easy instances and 15.9% on hard instances. All three math-specialized MLLMs solve 0/780 instances. Failure attribution shows that errors arise both when extracting instance data from text and visuals and when turning extracted data into solver-correct formulations and code. MM-OptBench provides a testbed for solver-grounded, decision-oriented multimodal intelligence.
Diffusion Models for Tabular Data: Challenges, Current Progress, and Future Directions
Feb 24, 2025In recent years, generative models have achieved remarkable performance across diverse applications, including image generation, text synthesis, audio creation, video generation, and data augmentation. Diffusion models have emerged as superior alternatives to Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) by addressing their limitations, such as training instability, mode collapse, and poor representation of multimodal distributions. This success has spurred widespread research interest. In the domain of tabular data, diffusion models have begun to showcase similar advantages over GANs and VAEs, achieving significant performance breakthroughs and demonstrating their potential for addressing unique challenges in tabular data modeling. However, while domains like images and time series have numerous surveys summarizing advancements in diffusion models, there remains a notable gap in the literature for tabular data. Despite the increasing interest in diffusion models for tabular data, there has been little effort to systematically review and summarize these developments. This lack of a dedicated survey limits a clear understanding of the challenges, progress, and future directions in this critical area. This survey addresses this gap by providing a comprehensive review of diffusion models for tabular data. Covering works from June 2015, when diffusion models emerged, to December 2024, we analyze nearly all relevant studies, with updates maintained in a \href{https://github.com/Diffusion-Model-Leiden/awesome-diffusion-models-for-tabular-data}{GitHub repository}. Assuming readers possess foundational knowledge of statistics and diffusion models, we employ mathematical formulations to deliver a rigorous and detailed review, aiming to promote developments in this emerging and exciting area.
Towards Automated Self-Supervised Learning for Truly Unsupervised Graph Anomaly Detection
Jan 24, 2025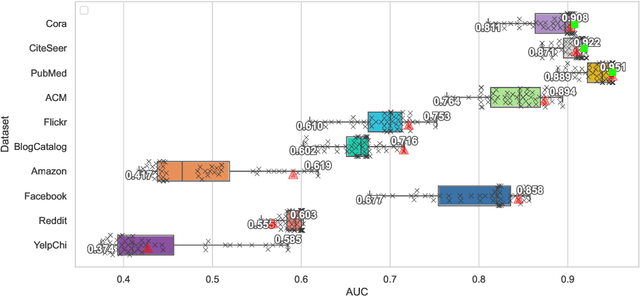
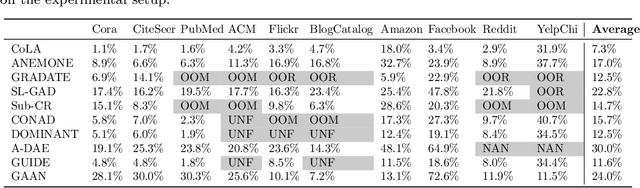
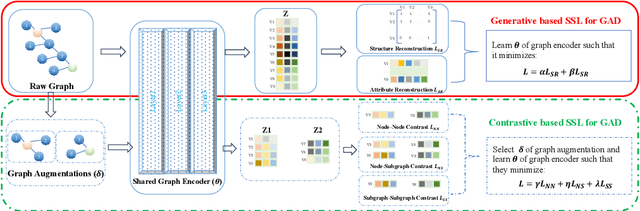
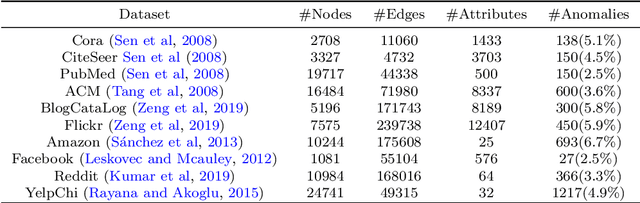
Self-supervised learning (SSL) is an emerging paradigm that exploits supervisory signals generated from the data itself, and many recent studies have leveraged SSL to conduct graph anomaly detection. However, we empirically found that three important factors can substantially impact detection performance across datasets: 1) the specific SSL strategy employed; 2) the tuning of the strategy's hyperparameters; and 3) the allocation of combination weights when using multiple strategies. Most SSL-based graph anomaly detection methods circumvent these issues by arbitrarily or selectively (i.e., guided by label information) choosing SSL strategies, hyperparameter settings, and combination weights. While an arbitrary choice may lead to subpar performance, using label information in an unsupervised setting is label information leakage and leads to severe overestimation of a method's performance. Leakage has been criticized as "one of the top ten data mining mistakes", yet many recent studies on SSL-based graph anomaly detection have been using label information to select hyperparameters. To mitigate this issue, we propose to use an internal evaluation strategy (with theoretical analysis) to select hyperparameters in SSL for unsupervised anomaly detection. We perform extensive experiments using 10 recent SSL-based graph anomaly detection algorithms on various benchmark datasets, demonstrating both the prior issues with hyperparameter selection and the effectiveness of our proposed strategy.
Directional anomaly detection
Oct 30, 2024



Semi-supervised anomaly detection is based on the principle that potential anomalies are those records that look different from normal training data. However, in some cases we are specifically interested in anomalies that correspond to high attribute values (or low, but not both). We present two asymmetrical distance measures that take this directionality into account: ramp distance and signed distance. Through experiments on synthetic and real-life datasets we show that ramp distance performs as well or better than the absolute distance traditionally used in anomaly detection. While signed distance also performs well on synthetic data, it performs substantially poorer on real-life datasets. We argue that this reflects the fact that in practice, good scores on some attributes should not be allowed to compensate for bad scores on others.
Conditional Density Estimation with Histogram Trees
Oct 15, 2024Conditional density estimation (CDE) goes beyond regression by modeling the full conditional distribution, providing a richer understanding of the data than just the conditional mean in regression. This makes CDE particularly useful in critical application domains. However, interpretable CDE methods are understudied. Current methods typically employ kernel-based approaches, using kernel functions directly for kernel density estimation or as basis functions in linear models. In contrast, despite their conceptual simplicity and visualization suitability, tree-based methods -- which are arguably more comprehensible -- have been largely overlooked for CDE tasks. Thus, we propose the Conditional Density Tree (CDTree), a fully non-parametric model consisting of a decision tree in which each leaf is formed by a histogram model. Specifically, we formalize the problem of learning a CDTree using the minimum description length (MDL) principle, which eliminates the need for tuning the hyperparameter for regularization. Next, we propose an iterative algorithm that, although greedily, searches the optimal histogram for every possible node split. Our experiments demonstrate that, in comparison to existing interpretable CDE methods, CDTrees are both more accurate (as measured by the log-loss) and more robust against irrelevant features. Further, our approach leads to smaller tree sizes than existing tree-based models, which benefits interpretability.
Explainable Graph Neural Networks Under Fire
Jun 10, 2024
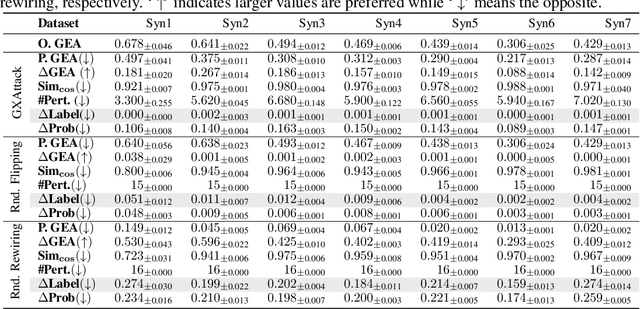
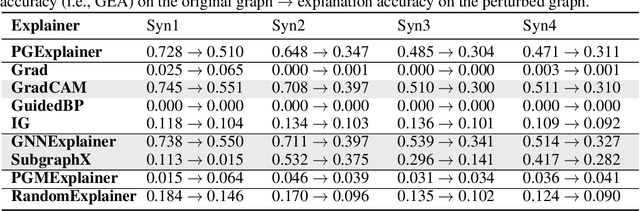
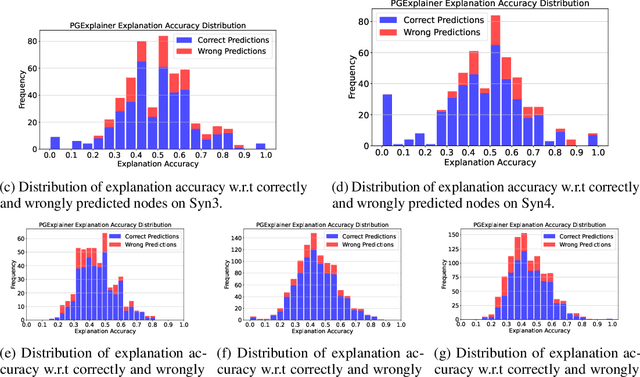
Predictions made by graph neural networks (GNNs) usually lack interpretability due to their complex computational behavior and the abstract nature of graphs. In an attempt to tackle this, many GNN explanation methods have emerged. Their goal is to explain a model's predictions and thereby obtain trust when GNN models are deployed in decision critical applications. Most GNN explanation methods work in a post-hoc manner and provide explanations in the form of a small subset of important edges and/or nodes. In this paper we demonstrate that these explanations can unfortunately not be trusted, as common GNN explanation methods turn out to be highly susceptible to adversarial perturbations. That is, even small perturbations of the original graph structure that preserve the model's predictions may yield drastically different explanations. This calls into question the trustworthiness and practical utility of post-hoc explanation methods for GNNs. To be able to attack GNN explanation models, we devise a novel attack method dubbed \textit{GXAttack}, the first \textit{optimization-based} adversarial attack method for post-hoc GNN explanations under such settings. Due to the devastating effectiveness of our attack, we call for an adversarial evaluation of future GNN explainers to demonstrate their robustness.
Probabilistic Truly Unordered Rule Sets
Jan 18, 2024Rule set learning has recently been frequently revisited because of its interpretability. Existing methods have several shortcomings though. First, most existing methods impose orders among rules, either explicitly or implicitly, which makes the models less comprehensible. Second, due to the difficulty of handling conflicts caused by overlaps (i.e., instances covered by multiple rules), existing methods often do not consider probabilistic rules. Third, learning classification rules for multi-class target is understudied, as most existing methods focus on binary classification or multi-class classification via the ``one-versus-rest" approach. To address these shortcomings, we propose TURS, for Truly Unordered Rule Sets. To resolve conflicts caused by overlapping rules, we propose a novel model that exploits the probabilistic properties of our rule sets, with the intuition of only allowing rules to overlap if they have similar probabilistic outputs. We next formalize the problem of learning a TURS model based on the MDL principle and develop a carefully designed heuristic algorithm. We benchmark against a wide range of rule-based methods and demonstrate that our method learns rule sets that have lower model complexity and highly competitive predictive performance. In addition, we empirically show that rules in our model are empirically ``independent" and hence truly unordered.
Graph Neural Network based Log Anomaly Detection and Explanation
Jul 02, 2023



Event logs are widely used to record the status of high-tech systems, making log anomaly detection important for monitoring those systems. Most existing log anomaly detection methods take a log event count matrix or log event sequences as input, exploiting quantitative and/or sequential relationships between log events to detect anomalies. Unfortunately, only considering quantitative or sequential relationships may result in many false positives and/or false negatives. To alleviate this problem, we propose a graph-based method for unsupervised log anomaly detection, dubbed Logs2Graphs, which first converts event logs into attributed, directed, and weighted graphs, and then leverages graph neural networks to perform graph-level anomaly detection. Specifically, we introduce One-Class Digraph Inception Convolutional Networks, abbreviated as OCDiGCN, a novel graph neural network model for detecting graph-level anomalies in a collection of attributed, directed, and weighted graphs. By coupling the graph representation and anomaly detection steps, OCDiGCN can learn a representation that is especially suited for anomaly detection, resulting in a high detection accuracy. Importantly, for each identified anomaly, we additionally provide a small subset of nodes that play a crucial role in OCDiGCN's prediction as explanations, which can offer valuable cues for subsequent root cause diagnosis. Experiments on five benchmark datasets show that Logs2Graphs performs at least on par state-of-the-art log anomaly detection methods on simple datasets while largely outperforming state-of-the-art log anomaly detection methods on complicated datasets.
Robust and Explainable Contextual Anomaly Detection using Quantile Regression Forests
Feb 22, 2023Traditional anomaly detection methods aim to identify objects that deviate from most other objects by treating all features equally. In contrast, contextual anomaly detection methods aim to detect objects that deviate from other objects within a context of similar objects by dividing the features into contextual features and behavioral features. In this paper, we develop connections between dependency-based traditional anomaly detection methods and contextual anomaly detection methods. Based on resulting insights, we propose a novel approach to robust and inherently interpretable contextual anomaly detection that uses Quantile Regression Forests to model dependencies between features. Extensive experiments on various synthetic and real-world datasets demonstrate that our method outperforms state-of-the-art anomaly detection methods in identifying contextual anomalies in terms of accuracy and robustness.
A Survey on Explainable Anomaly Detection
Oct 13, 2022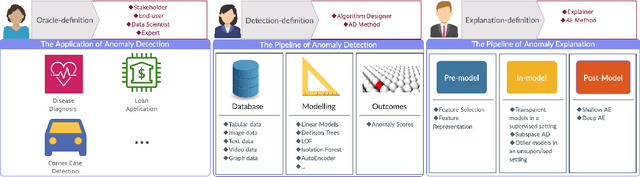
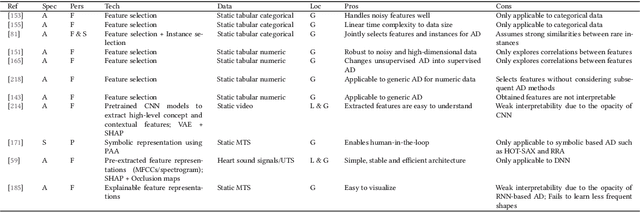
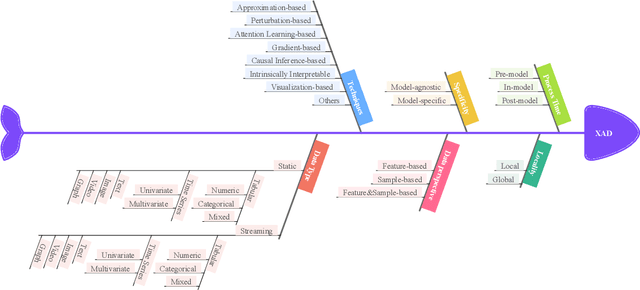
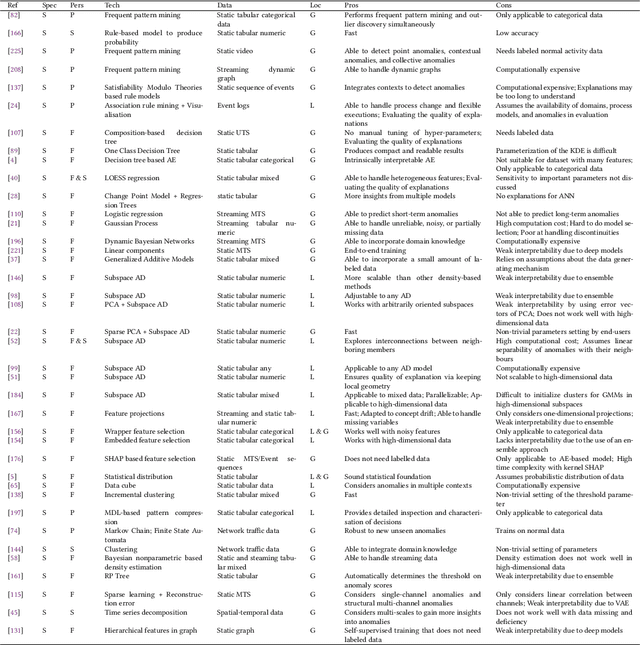
In the past two decades, most research on anomaly detection has focused on improving the accuracy of the detection, while largely ignoring the explainability of the corresponding methods and thus leaving the explanation of outcomes to practitioners. As anomaly detection algorithms are increasingly used in safety-critical domains, providing explanations for the high-stakes decisions made in those domains has become an ethical and regulatory requirement. Therefore, this work provides a comprehensive and structured survey on state-of-the-art explainable anomaly detection techniques. We propose a taxonomy based on the main aspects that characterize each explainable anomaly detection technique, aiming to help practitioners and researchers find the explainable anomaly detection method that best suits their needs.