 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-OptBench: A Solver-Grounded Benchmark for Multimodal Optimization Modeling
May 12, 2026Optimization modeling translates real decision-making problems into mathematical optimization models and solver-executable implementations. Although language models are increasingly used to generate optimization formulations and solver code, existing benchmarks are almost entirely text-only. This omits many optimization-modeling tasks that arise in operational practice, where requirements are described in text but instance information is conveyed through visual artifacts such as tables, graphs, maps, schedules, and dashboards. We introduce multimodal optimization modeling, a benchmark setting in which models must construct both a mathematical formulation and executable solver code from a text-and-visual problem specification. To evaluate this setting, we develop a solver-grounded framework that generates structured optimization instances, verifies each with an exact solver, and builds both the model-facing inputs and hidden reference files from the same verified source. We instantiate the framework as MM-OptBench, a benchmark of 780 solver-verified instances spanning 6 optimization families, 26 subcategories, and 3 structural difficulty levels. We evaluate 9 multimodal large language models (MLLMs), including 6 frontier general-purpose models and 3 math-specialized models, with aggregate, family-level, difficulty-level, and failure-mode analyses. The results show that the task remains far from solved: the best two models reach 52.1% and 51.3% pass@1, while on average across the six general-purpose MLLMs, pass@1 is 43.4% on easy instances and 15.9% on hard instances. All three math-specialized MLLMs solve 0/780 instances. Failure attribution shows that errors arise both when extracting instance data from text and visuals and when turning extracted data into solver-correct formulations and code. MM-OptBench provides a testbed for solver-grounded, decision-oriented multimodal intelligence.
Efficient Flow Matching for Sparse-View CT Reconstruction
Feb 27, 2026Generative models, particularly Diffusion Models (DM), have shown strong potential for Computed Tomography (CT) reconstruction serving as expressive priors for solving ill-posed inverse problems. However, diffusion-based reconstruction relies on Stochastic Differential Equations (SDEs) for forward diffusion and reverse denoising, where such stochasticity can interfere with repeated data consistency corrections in CT reconstruction. Since CT reconstruction is often time-critical in clinical and interventional scenarios, improving reconstruction efficiency is essential. In contrast, Flow Matching (FM) models sampling as a deterministic Ordinary Differential Equation (ODE), yielding smooth trajectories without stochastic noise injection. This deterministic formulation is naturally compatible with repeated data consistency operations. Furthermore, we observe that FM-predicted velocity fields exhibit strong correlations across adjacent steps. Motivated by this, we propose an FM-based CT reconstruction framework (FMCT) and an efficient variant (EFMCT) that reuses previously predicted velocity fields over consecutive steps to substantially reduce the number of Neural network Function Evaluations (NFEs), thereby improving inference efficiency. We provide theoretical analysis showing that the error introduced by velocity reuse is bounded when combined with data consistency operations. Extensive experiments demonstrate that FMCT/EFMCT achieve competitive reconstruction quality while significantly improving computational efficiency compared with diffusion-based methods. The codebase is open-sourced at https://github.com/EFMCT/EFMCT.
Diffusion Models for Tabular Data: Challenges, Current Progress, and Future Directions
Feb 24, 2025In recent years, generative models have achieved remarkable performance across diverse applications, including image generation, text synthesis, audio creation, video generation, and data augmentation. Diffusion models have emerged as superior alternatives to Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) by addressing their limitations, such as training instability, mode collapse, and poor representation of multimodal distributions. This success has spurred widespread research interest. In the domain of tabular data, diffusion models have begun to showcase similar advantages over GANs and VAEs, achieving significant performance breakthroughs and demonstrating their potential for addressing unique challenges in tabular data modeling. However, while domains like images and time series have numerous surveys summarizing advancements in diffusion models, there remains a notable gap in the literature for tabular data. Despite the increasing interest in diffusion models for tabular data, there has been little effort to systematically review and summarize these developments. This lack of a dedicated survey limits a clear understanding of the challenges, progress, and future directions in this critical area. This survey addresses this gap by providing a comprehensive review of diffusion models for tabular data. Covering works from June 2015, when diffusion models emerged, to December 2024, we analyze nearly all relevant studies, with updates maintained in a \href{https://github.com/Diffusion-Model-Leiden/awesome-diffusion-models-for-tabular-data}{GitHub repository}. Assuming readers possess foundational knowledge of statistics and diffusion models, we employ mathematical formulations to deliver a rigorous and detailed review, aiming to promote developments in this emerging and exciting area.
Conditional Density Estimation with Histogram Trees
Oct 15, 2024Conditional density estimation (CDE) goes beyond regression by modeling the full conditional distribution, providing a richer understanding of the data than just the conditional mean in regression. This makes CDE particularly useful in critical application domains. However, interpretable CDE methods are understudied. Current methods typically employ kernel-based approaches, using kernel functions directly for kernel density estimation or as basis functions in linear models. In contrast, despite their conceptual simplicity and visualization suitability, tree-based methods -- which are arguably more comprehensible -- have been largely overlooked for CDE tasks. Thus, we propose the Conditional Density Tree (CDTree), a fully non-parametric model consisting of a decision tree in which each leaf is formed by a histogram model. Specifically, we formalize the problem of learning a CDTree using the minimum description length (MDL) principle, which eliminates the need for tuning the hyperparameter for regularization. Next, we propose an iterative algorithm that, although greedily, searches the optimal histogram for every possible node split. Our experiments demonstrate that, in comparison to existing interpretable CDE methods, CDTrees are both more accurate (as measured by the log-loss) and more robust against irrelevant features. Further, our approach leads to smaller tree sizes than existing tree-based models, which benefits interpretability.
Probabilistic Truly Unordered Rule Sets
Jan 18, 2024Rule set learning has recently been frequently revisited because of its interpretability. Existing methods have several shortcomings though. First, most existing methods impose orders among rules, either explicitly or implicitly, which makes the models less comprehensible. Second, due to the difficulty of handling conflicts caused by overlaps (i.e., instances covered by multiple rules), existing methods often do not consider probabilistic rules. Third, learning classification rules for multi-class target is understudied, as most existing methods focus on binary classification or multi-class classification via the ``one-versus-rest" approach. To address these shortcomings, we propose TURS, for Truly Unordered Rule Sets. To resolve conflicts caused by overlapping rules, we propose a novel model that exploits the probabilistic properties of our rule sets, with the intuition of only allowing rules to overlap if they have similar probabilistic outputs. We next formalize the problem of learning a TURS model based on the MDL principle and develop a carefully designed heuristic algorithm. We benchmark against a wide range of rule-based methods and demonstrate that our method learns rule sets that have lower model complexity and highly competitive predictive performance. In addition, we empirically show that rules in our model are empirically ``independent" and hence truly unordered.
Truly Unordered Probabilistic Rule Sets for Multi-class Classification
Jun 29, 2022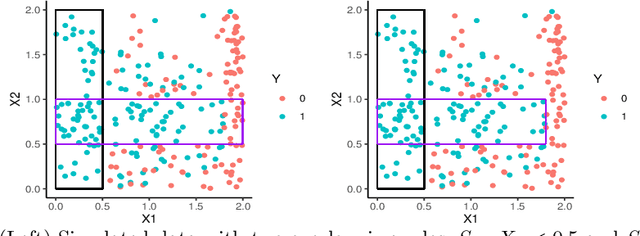

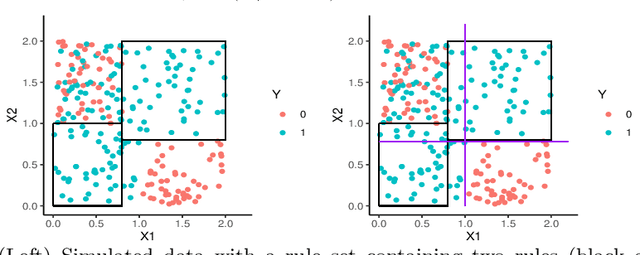
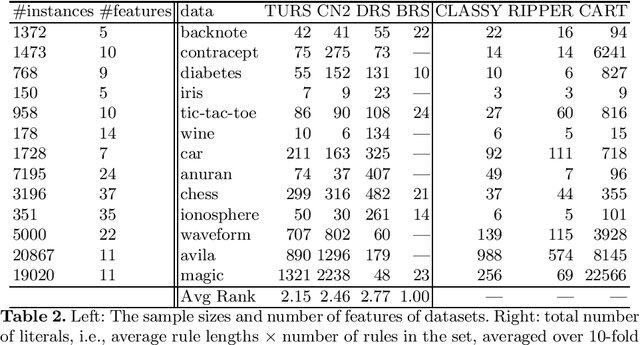
Rule set learning has long been studied and has recently been frequently revisited due to the need for interpretable models. Still, existing methods have several shortcomings: 1) most recent methods require a binary feature matrix as input, learning rules directly from numeric variables is understudied; 2) existing methods impose orders among rules, either explicitly or implicitly, which harms interpretability; and 3) currently no method exists for learning probabilistic rule sets for multi-class target variables (there is only a method for probabilistic rule lists). We propose TURS, for Truly Unordered Rule Sets, which addresses these shortcomings. We first formalise the problem of learning truly unordered rule sets. To resolve conflicts caused by overlapping rules, i.e., instances covered by multiple rules, we propose a novel approach that exploits the probabilistic properties of our rule sets. We next develop a two-phase heuristic algorithm that learns rule sets by carefully growing rules. An important innovation is that we use a surrogate score to take the global potential of the rule set into account when learning a local rule. Finally, we empirically demonstrate that, compared to non-probabilistic and (explicitly or implicitly) ordered state-of-the-art methods, our method learns rule sets that not only have better interpretability (i.e., they are smaller and truly unordered), but also better predictive performance.
Unsupervised Discretization by Two-dimensional MDL-based Histogram
Jun 02, 2020

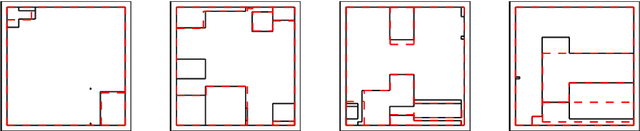
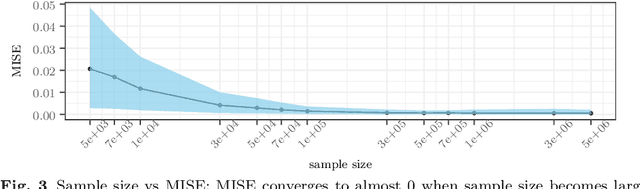
Unsupervised discretization is a crucial step in many knowledge discovery tasks. The state-of-the-art method for one-dimensional data infers locally adaptive histograms using the minimum description length (MDL) principle, but the multi-dimensional case is far less studied: current methods consider the dimensions one at a time (if not independently), which result in discretizations based on rectangular cells of adaptive size. Unfortunately, this approach is unable to adequately characterize dependencies among dimensions and/or results in discretizations consisting of more cells (or bins) than is desirable. To address this problem, we propose an expressive model class that allows for far more flexible partitions of two-dimensional data. We extend the state of the art for the one-dimensional case to obtain a model selection problem based on the normalised maximum likelihood, a form of refined MDL. As the flexibility of our model class comes at the cost of a vast search space, we introduce a heuristic algorithm, named PALM, which partitions each dimension alternately and then merges neighbouring regions, all using the MDL principle. Experiments on synthetic data show that PALM 1) accurately reveals ground truth partitions that are within the model class (i.e., the search space), given a large enough sample size; 2) approximates well a wide range of partitions outside the model class; 3) converges, in contrast to its closest competitor IPD; and 4) is self-adaptive with regard to both sample size and local density structure of the data despite being parameter-free. Finally, we apply our algorithm to two geographic datasets to demonstrate its real-world potential.