 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025
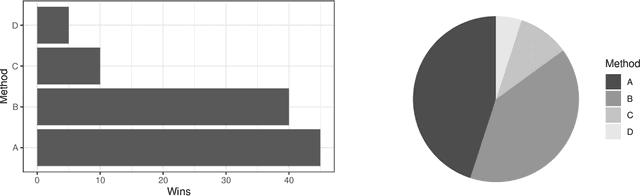
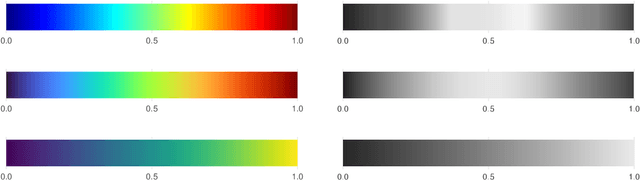
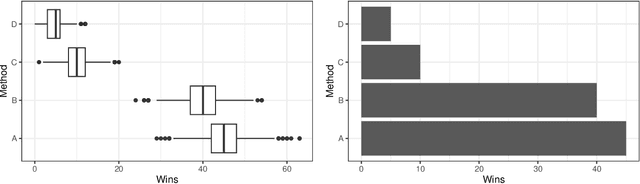
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
Reducing false positives in strong lens detection through effective augmentation and ensemble learning
Feb 20, 2025This research studies the impact of high-quality training datasets on the performance of Convolutional Neural Networks (CNNs) in detecting strong gravitational lenses. We stress the importance of data diversity and representativeness, demonstrating how variations in sample populations influence CNN performance. In addition to the quality of training data, our results highlight the effectiveness of various techniques, such as data augmentation and ensemble learning, in reducing false positives while maintaining model completeness at an acceptable level. This enhances the robustness of gravitational lens detection models and advancing capabilities in this field. Our experiments, employing variations of DenseNet and EfficientNet, achieved a best false positive rate (FP rate) of $10^{-4}$, while successfully identifying over 88 per cent of genuine gravitational lenses in the test dataset. This represents an 11-fold reduction in the FP rate compared to the original training dataset. Notably, this substantial enhancement in the FP rate is accompanied by only a 2.3 per cent decrease in the number of true positive samples. Validated on the KiDS dataset, our findings offer insights applicable to ongoing missions, like Euclid.
Automated classification of pre-defined movement patterns: A comparison between GNSS and UWB technology
Mar 10, 2023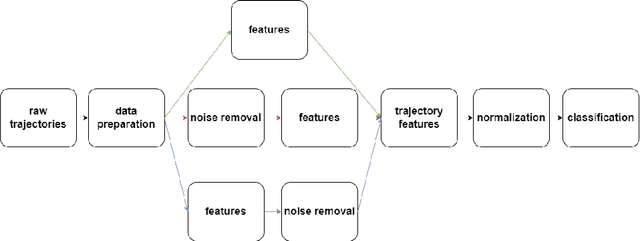



Advanced real-time location systems (RTLS) allow for collecting spatio-temporal data from human movement behaviours. Tracking individuals in small areas such as schoolyards or nursing homes might impose difficulties for RTLS in terms of positioning accuracy. However, to date, few studies have investigated the performance of different localisation systems regarding the classification of human movement patterns in small areas. The current study aims to design and evaluate an automated framework to classify human movement trajectories obtained from two different RTLS: Global Navigation Satellite System (GNSS) and Ultra-wideband (UWB), in areas of approximately 100 square meters. Specifically, we designed a versatile framework which takes GNSS or UWB data as input, extracts features from these data and classifies them according to the annotated spatial patterns. The automated framework contains three choices for applying noise removal: (i) no noise removal, (ii) Savitzky Golay filter on the raw location data or (iii) Savitzky Golay filter on the extracted features, as well as three choices regarding the classification algorithm: Decision Tree (DT), Random Forest (RF) or Support Vector Machine (SVM). We integrated different stages within the framework with the Sequential Model-Based Algorithm Configuration (SMAC) to perform automated hyperparameter optimisation. The best performance is achieved with a pipeline consisting of noise removal applied to the raw location data with an RF model for the GNSS and no noise removal with an SVM model for the UWB. We further demonstrate through statistical analysis that the UWB achieves significantly higher results than the GNSS in classifying movement patterns.
A Systematic Analysis on the Impact of Contextual Information on Point-of-Interest Recommendation
Jan 20, 2022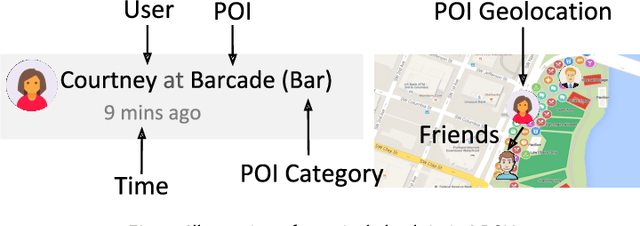
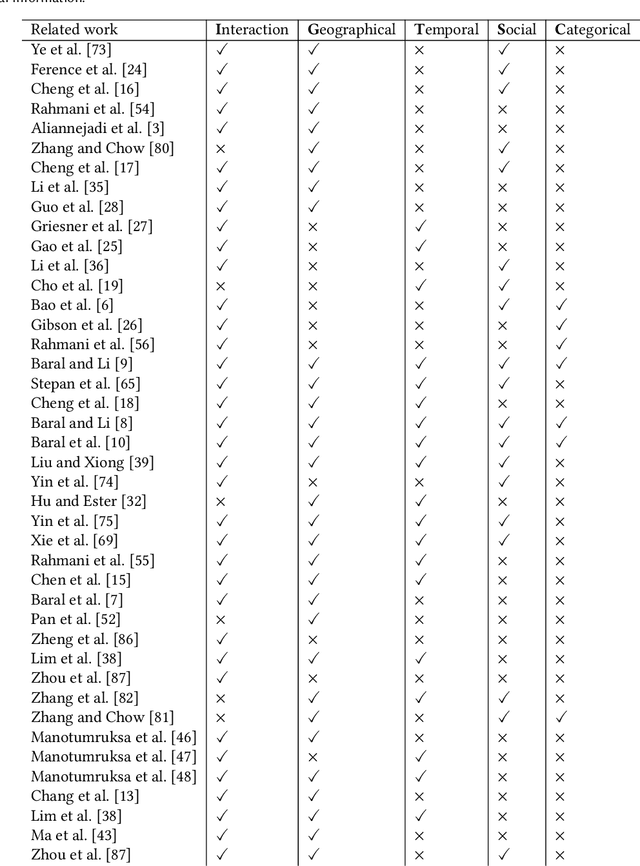
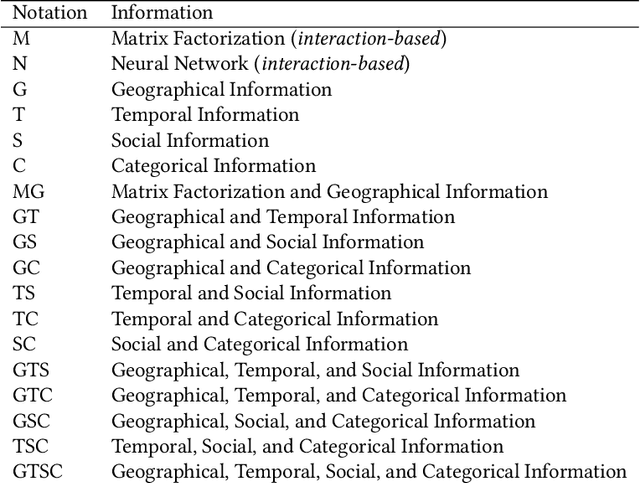
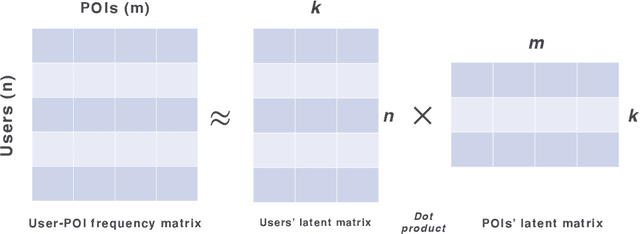
As the popularity of Location-based Social Networks (LBSNs) increases, designing accurate models for Point-of-Interest (POI) recommendation receives more attention. POI recommendation is often performed by incorporating contextual information into previously designed recommendation algorithms. Some of the major contextual information that has been considered in POI recommendation are the location attributes (i.e., exact coordinates of a location, category, and check-in time), the user attributes (i.e., comments, reviews, tips, and check-in made to the locations), and other information, such as the distance of the POI from user's main activity location, and the social tie between users. The right selection of such factors can significantly impact the performance of the POI recommendation. However, previous research does not consider the impact of the combination of these different factors. In this paper, we propose different contextual models and analyze the fusion of different major contextual information in POI recommendation. The major contributions of this paper are: (i) providing an extensive survey of context-aware location recommendation (ii) quantifying and analyzing the impact of different contextual information (e.g., social, temporal, spatial, and categorical) in the POI recommendation on available baselines and two new linear and non-linear models, that can incorporate all the major contextual information into a single recommendation model, and (iii) evaluating the considered models using two well-known real-world datasets. Our results indicate that while modeling geographical and temporal influences can improve recommendation quality, fusing all other contextual information into a recommendation model is not always the best strategy.
Unsupervised Discretization by Two-dimensional MDL-based Histogram
Jun 02, 2020

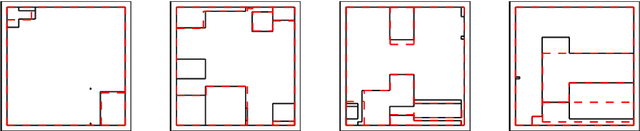
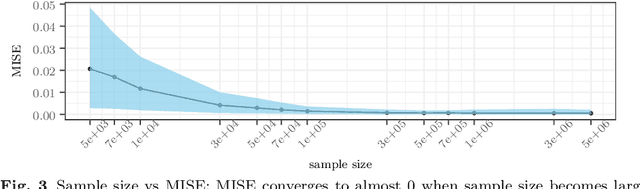
Unsupervised discretization is a crucial step in many knowledge discovery tasks. The state-of-the-art method for one-dimensional data infers locally adaptive histograms using the minimum description length (MDL) principle, but the multi-dimensional case is far less studied: current methods consider the dimensions one at a time (if not independently), which result in discretizations based on rectangular cells of adaptive size. Unfortunately, this approach is unable to adequately characterize dependencies among dimensions and/or results in discretizations consisting of more cells (or bins) than is desirable. To address this problem, we propose an expressive model class that allows for far more flexible partitions of two-dimensional data. We extend the state of the art for the one-dimensional case to obtain a model selection problem based on the normalised maximum likelihood, a form of refined MDL. As the flexibility of our model class comes at the cost of a vast search space, we introduce a heuristic algorithm, named PALM, which partitions each dimension alternately and then merges neighbouring regions, all using the MDL principle. Experiments on synthetic data show that PALM 1) accurately reveals ground truth partitions that are within the model class (i.e., the search space), given a large enough sample size; 2) approximates well a wide range of partitions outside the model class; 3) converges, in contrast to its closest competitor IPD; and 4) is self-adaptive with regard to both sample size and local density structure of the data despite being parameter-free. Finally, we apply our algorithm to two geographic datasets to demonstrate its real-world potential.
Joint Geographical and Temporal Modeling based on Matrix Factorization for Point-of-Interest Recommendation
Jan 24, 2020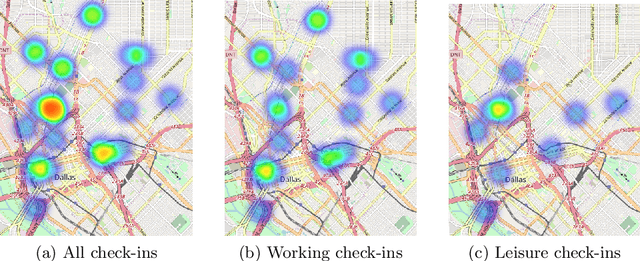
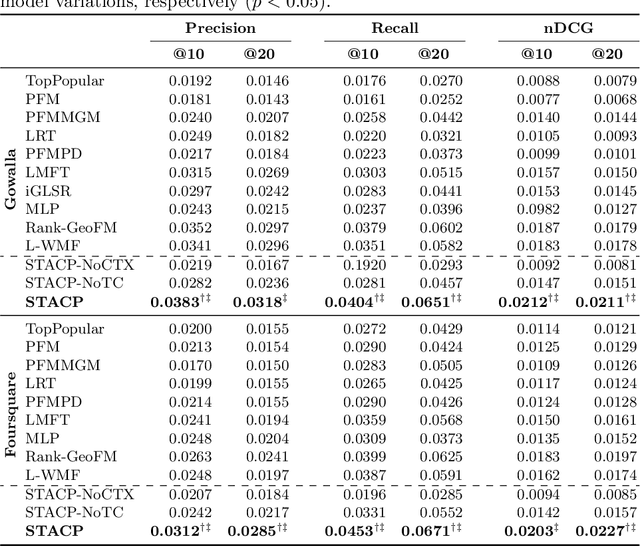
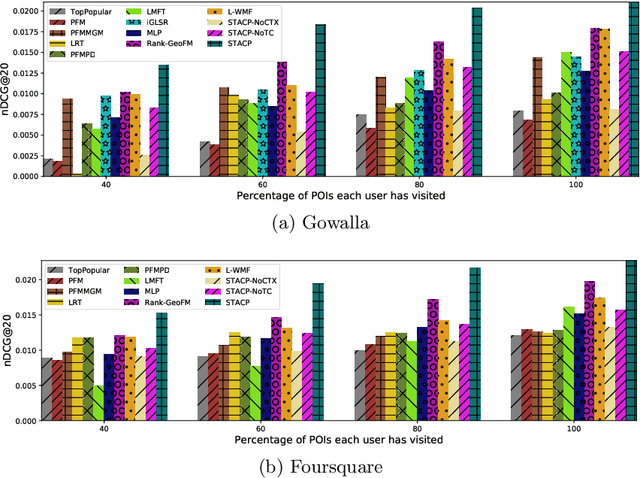
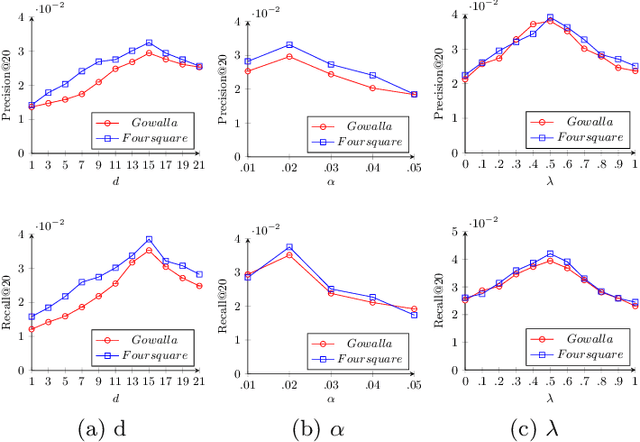
With the popularity of Location-based Social Networks, Point-of-Interest (POI) recommendation has become an important task, which learns the users' preferences and mobility patterns to recommend POIs. Previous studies show that incorporating contextual information such as geographical and temporal influences is necessary to improve POI recommendation by addressing the data sparsity problem. However, existing methods model the geographical influence based on the physical distance between POIs and users, while ignoring the temporal characteristics of such geographical influences. In this paper, we perform a study on the user mobility patterns where we find out that users' check-ins happen around several centers depending on their current temporal state. Next, we propose a spatio-temporal activity-centers algorithm to model users' behavior more accurately. Finally, we demonstrate the effectiveness of our proposed contextual model by incorporating it into the matrix factorization model under two different settings: i) static and ii) temporal. To show the effectiveness of our proposed method, which we refer to as STACP, we conduct experiments on two well-known real-world datasets acquired from Gowalla and Foursquare LBSNs. Experimental results show that the STACP model achieves a statistically significant performance improvement, compared to the state-of-the-art techniques. Also, we demonstrate the effectiveness of capturing geographical and temporal information for modeling users' activity centers and the importance of modeling them jointly.
Spaceprint: a Mobility-based Fingerprinting Scheme for Public Spaces
Mar 29, 2017
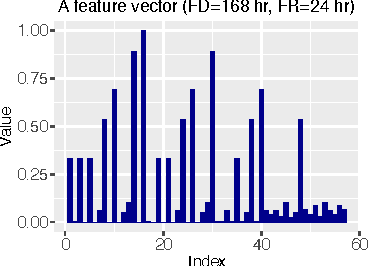


In this paper, we address the problem of how automated situation-awareness can be achieved by learning real-world situations from ubiquitously generated mobility data. Without semantic input about the time and space where situations take place, this turns out to be a fundamental challenging problem. Uncertainties also introduce technical challenges when data is generated in irregular time intervals, being mixed with noise, and errors. Purely relying on temporal patterns observable in mobility data, in this paper, we propose Spaceprint, a fully automated algorithm for finding the repetitive pattern of similar situations in spaces. We evaluate this technique by showing how the latent variables describing the category, and the actual identity of a space can be discovered from the extracted situation patterns. Doing so, we use different real-world mobility datasets with data about the presence of mobile entities in a variety of spaces. We also evaluate the performance of this technique by showing its robustness against uncertainties.