 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSources of Gain: Decomposing Performance in Conditional Average Dose Response Estimation
Jun 12, 2024



Estimating conditional average dose responses (CADR) is an important but challenging problem. Estimators must correctly model the potentially complex relationships between covariates, interventions, doses, and outcomes. In recent years, the machine learning community has shown great interest in developing tailored CADR estimators that target specific challenges. Their performance is typically evaluated against other methods on (semi-) synthetic benchmark datasets. Our paper analyses this practice and shows that using popular benchmark datasets without further analysis is insufficient to judge model performance. Established benchmarks entail multiple challenges, whose impacts must be disentangled. Therefore, we propose a novel decomposition scheme that allows the evaluation of the impact of five distinct components contributing to CADR estimator performance. We apply this scheme to eight popular CADR estimators on four widely-used benchmark datasets, running nearly 1,500 individual experiments. Our results reveal that most established benchmarks are challenging for reasons different from their creators' claims. Notably, confounding, the key challenge tackled by most estimators, is not an issue in any of the considered datasets. We discuss the major implications of our findings and present directions for future research.
Network Analytics for Anti-Money Laundering -- A Systematic Literature Review and Experimental Evaluation
May 31, 2024Money laundering presents a pervasive challenge, burdening society by financing illegal activities. To more effectively combat and detect money laundering, the use of network information is increasingly being explored, exploiting that money laundering necessarily involves interconnected parties. This has lead to a surge in literature on network analytics (NA) for anti-money laundering (AML). The literature, however, is fragmented and a comprehensive overview of existing work is missing. This results in limited understanding of the methods that may be applied and their comparative detection power. Therefore, this paper presents an extensive and systematic review of the literature. We identify and analyse 97 papers in the Web of Science and Scopus databases, resulting in a taxonomy of approaches following the fraud analytics framework of Bockel-Rickermann et al.. Moreover, this paper presents a comprehensive experimental framework to evaluate and compare the performance of prominent NA methods in a uniform setup. The framework is applied on the publicly available Elliptic data set and implements manual feature engineering, random walk-based methods, and deep learning GNNs. We conclude from the results that network analytics increases the predictive power of the AML model with graph neural networks giving the best results. An open source implementation of the experimental framework is provided to facilitate researchers and practitioners to extend upon these results and experiment on proprietary data. As such, we aim to promote a standardised approach towards the analysis and evaluation of network analytics for AML.
Metalearners for Ranking Treatment Effects
May 03, 2024
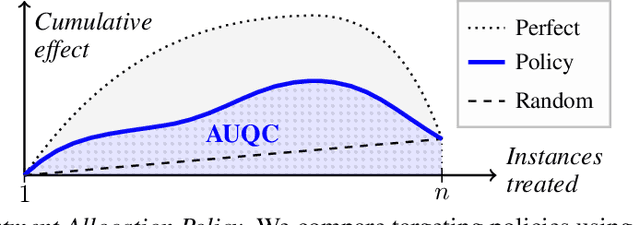

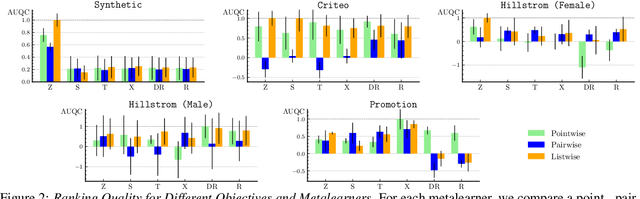
Efficiently allocating treatments with a budget constraint constitutes an important challenge across various domains. In marketing, for example, the use of promotions to target potential customers and boost conversions is limited by the available budget. While much research focuses on estimating causal effects, there is relatively limited work on learning to allocate treatments while considering the operational context. Existing methods for uplift modeling or causal inference primarily estimate treatment effects, without considering how this relates to a profit maximizing allocation policy that respects budget constraints. The potential downside of using these methods is that the resulting predictive model is not aligned with the operational context. Therefore, prediction errors are propagated to the optimization of the budget allocation problem, subsequently leading to a suboptimal allocation policy. We propose an alternative approach based on learning to rank. Our proposed methodology directly learns an allocation policy by prioritizing instances in terms of their incremental profit. We propose an efficient sampling procedure for the optimization of the ranking model to scale our methodology to large-scale data sets. Theoretically, we show how learning to rank can maximize the area under a policy's incremental profit curve. Empirically, we validate our methodology and show its effectiveness in practice through a series of experiments on both synthetic and real-world data.
Learning continuous-valued treatment effects through representation balancing
Sep 07, 2023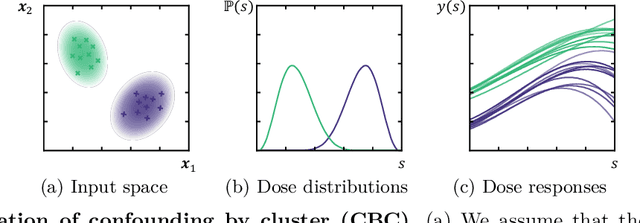
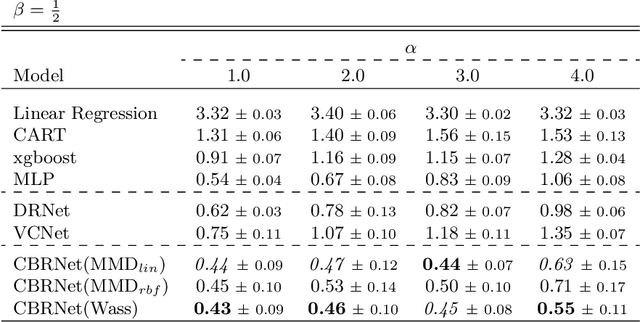
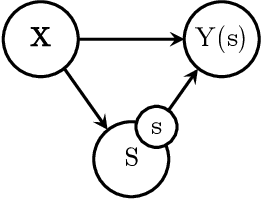
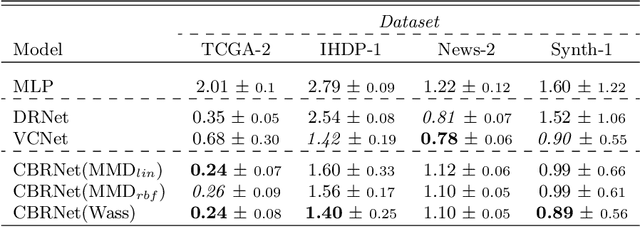
Estimating the effects of treatments with an associated dose on an instance's outcome, the "dose response", is relevant in a variety of domains, from healthcare to business, economics, and beyond. Such effects, also known as continuous-valued treatment effects, are typically estimated from observational data, which may be subject to dose selection bias. This means that the allocation of doses depends on pre-treatment covariates. Previous studies have shown that conventional machine learning approaches fail to learn accurate individual estimates of dose responses under the presence of dose selection bias. In this work, we propose CBRNet, a causal machine learning approach to estimate an individual dose response from observational data. CBRNet adopts the Neyman-Rubin potential outcome framework and extends the concept of balanced representation learning for overcoming selection bias to continuous-valued treatments. Our work is the first to apply representation balancing in a continuous-valued treatment setting. We evaluate our method on a newly proposed benchmark. Our experiments demonstrate CBRNet's ability to accurately learn treatment effects under selection bias and competitive performance with respect to other state-of-the-art methods.
Accounting For Informative Sampling When Learning to Forecast Treatment Outcomes Over Time
Jun 07, 2023
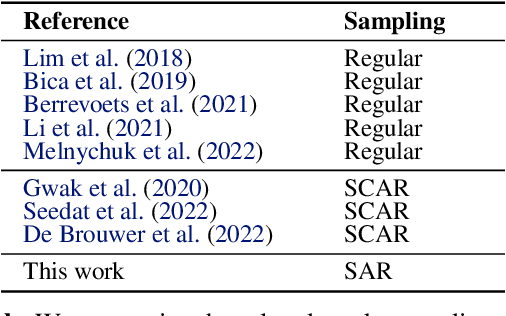
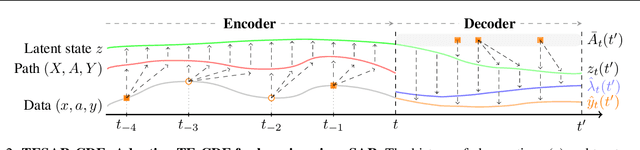

Machine learning (ML) holds great potential for accurately forecasting treatment outcomes over time, which could ultimately enable the adoption of more individualized treatment strategies in many practical applications. However, a significant challenge that has been largely overlooked by the ML literature on this topic is the presence of informative sampling in observational data. When instances are observed irregularly over time, sampling times are typically not random, but rather informative -- depending on the instance's characteristics, past outcomes, and administered treatments. In this work, we formalize informative sampling as a covariate shift problem and show that it can prohibit accurate estimation of treatment outcomes if not properly accounted for. To overcome this challenge, we present a general framework for learning treatment outcomes in the presence of informative sampling using inverse intensity-weighting, and propose a novel method, TESAR-CDE, that instantiates this framework using Neural CDEs. Using a simulation environment based on a clinical use case, we demonstrate the effectiveness of our approach in learning under informative sampling.
Prescriptive maintenance with causal machine learning
Jun 03, 2022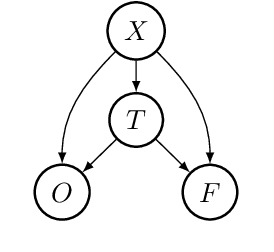
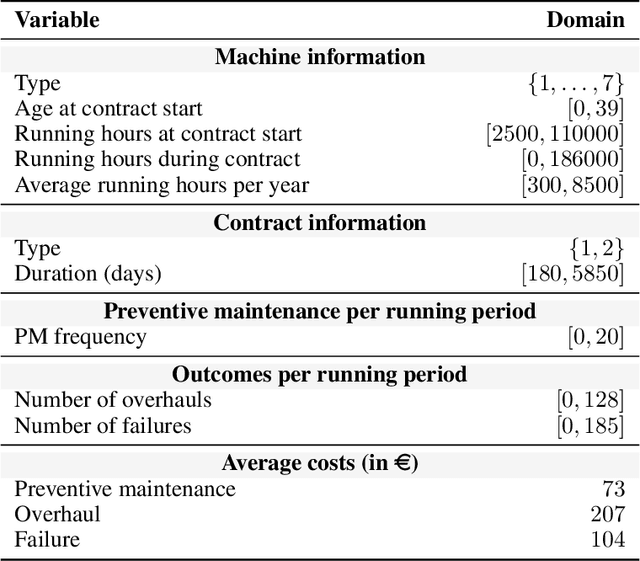


Machine maintenance is a challenging operational problem, where the goal is to plan sufficient preventive maintenance to avoid machine failures and overhauls. Maintenance is often imperfect in reality and does not make the asset as good as new. Although a variety of imperfect maintenance policies have been proposed in the literature, these rely on strong assumptions regarding the effect of maintenance on the machine's condition, assuming the effect is (1) deterministic or governed by a known probability distribution, and (2) machine-independent. This work proposes to relax both assumptions by learning the effect of maintenance conditional on a machine's characteristics from observational data on similar machines using existing methodologies for causal inference. By predicting the maintenance effect, we can estimate the number of overhauls and failures for different levels of maintenance and, consequently, optimize the preventive maintenance frequency to minimize the total estimated cost. We validate our proposed approach using real-life data on more than 4,000 maintenance contracts from an industrial partner. Empirical results show that our novel, causal approach accurately predicts the maintenance effect and results in individualized maintenance schedules that are more accurate and cost-effective than supervised or non-individualized approaches.
A new perspective on classification: optimally allocating limited resources to uncertain tasks
Feb 09, 2022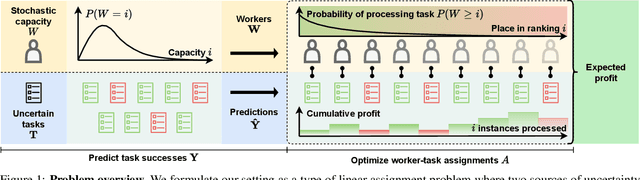

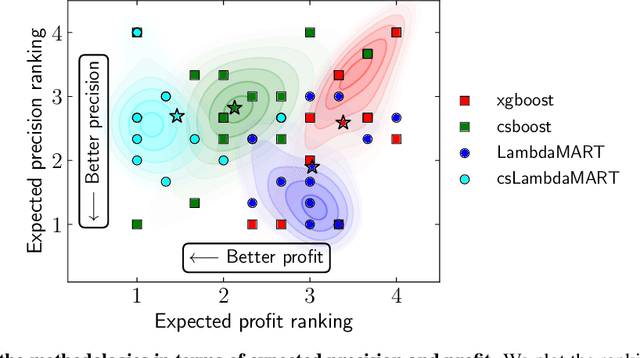
A central problem in business concerns the optimal allocation of limited resources to a set of available tasks, where the payoff of these tasks is inherently uncertain. In credit card fraud detection, for instance, a bank can only assign a small subset of transactions to their fraud investigations team. Typically, such problems are solved using a classification framework, where the focus is on predicting task outcomes given a set of characteristics. Resources are then allocated to the tasks that are predicted to be the most likely to succeed. However, we argue that using classification to address task uncertainty is inherently suboptimal as it does not take into account the available capacity. Therefore, we first frame the problem as a type of assignment problem. Then, we present a novel solution using learning to rank by directly optimizing the assignment's expected profit given limited, stochastic capacity. This is achieved by optimizing a specific instance of the net discounted cumulative gain, a commonly used class of metrics in learning to rank. Empirically, we demonstrate that our new method achieves higher expected profit and expected precision compared to a classification approach for a wide variety of application areas and data sets. This illustrates the benefit of an integrated approach and of explicitly considering the available resources when learning a predictive model.