 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Performance of LLMs for Real Estate Appraisal
Jun 13, 2025The real estate market is vital to global economies but suffers from significant information asymmetry. This study examines how Large Language Models (LLMs) can democratize access to real estate insights by generating competitive and interpretable house price estimates through optimized In-Context Learning (ICL) strategies. We systematically evaluate leading LLMs on diverse international housing datasets, comparing zero-shot, few-shot, market report-enhanced, and hybrid prompting techniques. Our results show that LLMs effectively leverage hedonic variables, such as property size and amenities, to produce meaningful estimates. While traditional machine learning models remain strong for pure predictive accuracy, LLMs offer a more accessible, interactive and interpretable alternative. Although self-explanations require cautious interpretation, we find that LLMs explain their predictions in agreement with state-of-the-art models, confirming their trustworthiness. Carefully selected in-context examples based on feature similarity and geographic proximity, significantly enhance LLM performance, yet LLMs struggle with overconfidence in price intervals and limited spatial reasoning. We offer practical guidance for structured prediction tasks through prompt optimization. Our findings highlight LLMs' potential to improve transparency in real estate appraisal and provide actionable insights for stakeholders.
GARG-AML against Smurfing: A Scalable and Interpretable Graph-Based Framework for Anti-Money Laundering
Jun 04, 2025Money laundering poses a significant challenge as it is estimated to account for 2%-5% of the global GDP. This has compelled regulators to impose stringent controls on financial institutions. One prominent laundering method for evading these controls, called smurfing, involves breaking up large transactions into smaller amounts. Given the complexity of smurfing schemes, which involve multiple transactions distributed among diverse parties, network analytics has become an important anti-money laundering tool. However, recent advances have focused predominantly on black-box network embedding methods, which has hindered their adoption in businesses. In this paper, we introduce GARG-AML, a novel graph-based method that quantifies smurfing risk through a single interpretable metric derived from the structure of the second-order transaction network of each individual node in the network. Unlike traditional methods, GARG-AML strikes an effective balance among computational efficiency, detection power and transparency, which enables its integration into existing AML workflows. To enhance its capabilities, we combine the GARG-AML score calculation with different tree-based methods and also incorporate the scores of the node's neighbours. An experimental evaluation on large-scale synthetic and open-source networks demonstrate that the GARG-AML outperforms the current state-of-the-art smurfing detection methods. By leveraging only the adjacency matrix of the second-order neighbourhood and basic network features, this work highlights the potential of fundamental network properties towards advancing fraud detection.
Advances in Continual Graph Learning for Anti-Money Laundering Systems: A Comprehensive Review
Mar 31, 2025Financial institutions are required by regulation to report suspicious financial transactions related to money laundering. Therefore, they need to constantly monitor vast amounts of incoming and outgoing transactions. A particular challenge in detecting money laundering is that money launderers continuously adapt their tactics to evade detection. Hence, detection methods need constant fine-tuning. Traditional machine learning models suffer from catastrophic forgetting when fine-tuning the model on new data, thereby limiting their effectiveness in dynamic environments. Continual learning methods may address this issue and enhance current anti-money laundering (AML) practices, by allowing models to incorporate new information while retaining prior knowledge. Research on continual graph learning for AML, however, is still scarce. In this review, we critically evaluate state-of-the-art continual graph learning approaches for AML applications. We categorise methods into replay-based, regularization-based, and architecture-based strategies within the graph neural network (GNN) framework, and we provide in-depth experimental evaluations on both synthetic and real-world AML data sets that showcase the effect of the different hyperparameters. Our analysis demonstrates that continual learning improves model adaptability and robustness in the face of extreme class imbalances and evolving fraud patterns. Finally, we outline key challenges and propose directions for future research.
Native Design Bias: Studying the Impact of English Nativeness on Language Model Performance
Jun 25, 2024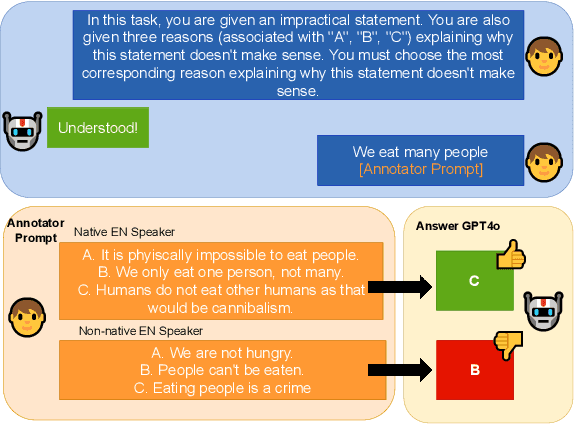
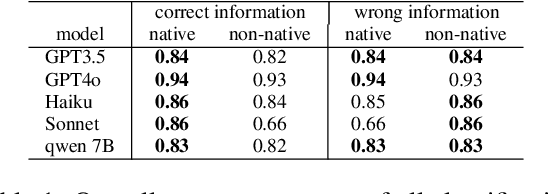
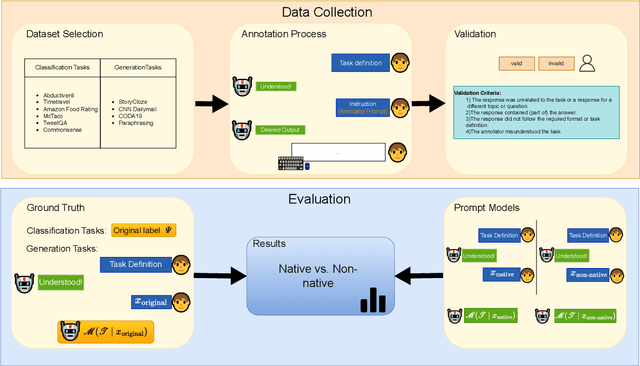
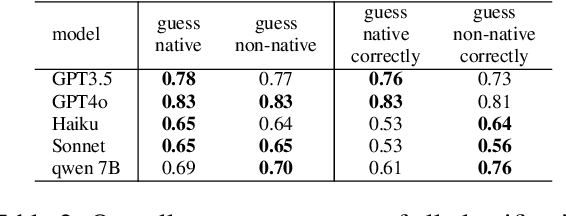
Large Language Models (LLMs) excel at providing information acquired during pretraining on large-scale corpora and following instructions through user prompts. This study investigates whether the quality of LLM responses varies depending on the demographic profile of users. Considering English as the global lingua franca, along with the diversity of its dialects among speakers of different native languages, we explore whether non-native English speakers receive lower-quality or even factually incorrect responses from LLMs more frequently. Our results show that performance discrepancies occur when LLMs are prompted by native versus non-native English speakers and persist when comparing native speakers from Western countries with others. Additionally, we find a strong anchoring effect when the model recognizes or is made aware of the user's nativeness, which further degrades the response quality when interacting with non-native speakers. Our analysis is based on a newly collected dataset with over 12,000 unique annotations from 124 annotators, including information on their native language and English proficiency.
Network Analytics for Anti-Money Laundering -- A Systematic Literature Review and Experimental Evaluation
May 31, 2024Money laundering presents a pervasive challenge, burdening society by financing illegal activities. To more effectively combat and detect money laundering, the use of network information is increasingly being explored, exploiting that money laundering necessarily involves interconnected parties. This has lead to a surge in literature on network analytics (NA) for anti-money laundering (AML). The literature, however, is fragmented and a comprehensive overview of existing work is missing. This results in limited understanding of the methods that may be applied and their comparative detection power. Therefore, this paper presents an extensive and systematic review of the literature. We identify and analyse 97 papers in the Web of Science and Scopus databases, resulting in a taxonomy of approaches following the fraud analytics framework of Bockel-Rickermann et al.. Moreover, this paper presents a comprehensive experimental framework to evaluate and compare the performance of prominent NA methods in a uniform setup. The framework is applied on the publicly available Elliptic data set and implements manual feature engineering, random walk-based methods, and deep learning GNNs. We conclude from the results that network analytics increases the predictive power of the AML model with graph neural networks giving the best results. An open source implementation of the experimental framework is provided to facilitate researchers and practitioners to extend upon these results and experiment on proprietary data. As such, we aim to promote a standardised approach towards the analysis and evaluation of network analytics for AML.
Leveraging Time-Series Foundation Models in Smart Agriculture for Soil Moisture Forecasting
May 29, 2024

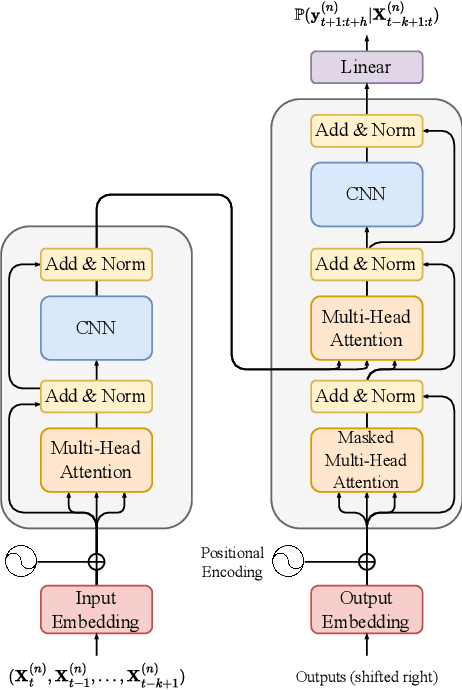

The recent surge in foundation models for natural language processing and computer vision has fueled innovation across various domains. Inspired by this progress, we explore the potential of foundation models for time-series forecasting in smart agriculture, a field often plagued by limited data availability. Specifically, this work presents a novel application of $\texttt{TimeGPT}$, a state-of-the-art (SOTA) time-series foundation model, to predict soil water potential ($\psi_\mathrm{soil}$), a key indicator of field water status that is typically used for irrigation advice. Traditionally, this task relies on a wide array of input variables. We explore $\psi_\mathrm{soil}$'s ability to forecast $\psi_\mathrm{soil}$ in: ($i$) a zero-shot setting, ($ii$) a fine-tuned setting relying solely on historic $\psi_\mathrm{soil}$ measurements, and ($iii$) a fine-tuned setting where we also add exogenous variables to the model. We compare $\texttt{TimeGPT}$'s performance to established SOTA baseline models for forecasting $\psi_\mathrm{soil}$. Our results demonstrate that $\texttt{TimeGPT}$ achieves competitive forecasting accuracy using only historical $\psi_\mathrm{soil}$ data, highlighting its remarkable potential for agricultural applications. This research paves the way for foundation time-series models for sustainable development in agriculture by enabling forecasting tasks that were traditionally reliant on extensive data collection and domain expertise.
End-To-End Self-tuning Self-supervised Time Series Anomaly Detection
Apr 03, 2024



Time series anomaly detection (TSAD) finds many applications such as monitoring environmental sensors, industry KPIs, patient biomarkers, etc. A two-fold challenge for TSAD is a versatile and unsupervised model that can detect various different types of time series anomalies (spikes, discontinuities, trend shifts, etc.) without any labeled data. Modern neural networks have outstanding ability in modeling complex time series. Self-supervised models in particular tackle unsupervised TSAD by transforming the input via various augmentations to create pseudo anomalies for training. However, their performance is sensitive to the choice of augmentation, which is hard to choose in practice, while there exists no effort in the literature on data augmentation tuning for TSAD without labels. Our work aims to fill this gap. We introduce TSAP for TSA "on autoPilot", which can (self-)tune augmentation hyperparameters end-to-end. It stands on two key components: a differentiable augmentation architecture and an unsupervised validation loss to effectively assess the alignment between augmentation type and anomaly type. Case studies show TSAP's ability to effectively select the (discrete) augmentation type and associated (continuous) hyperparameters. In turn, it outperforms established baselines, including SOTA self-supervised models, on diverse TSAD tasks exhibiting different anomaly types.
SEER : A Knapsack approach to Exemplar Selection for In-Context HybridQA
Oct 20, 2023



Question answering over hybrid contexts is a complex task, which requires the combination of information extracted from unstructured texts and structured tables in various ways. Recently, In-Context Learning demonstrated significant performance advances for reasoning tasks. In this paradigm, a large language model performs predictions based on a small set of supporting exemplars. The performance of In-Context Learning depends heavily on the selection procedure of the supporting exemplars, particularly in the case of HybridQA, where considering the diversity of reasoning chains and the large size of the hybrid contexts becomes crucial. In this work, we present Selection of ExEmplars for hybrid Reasoning (SEER), a novel method for selecting a set of exemplars that is both representative and diverse. The key novelty of SEER is that it formulates exemplar selection as a Knapsack Integer Linear Program. The Knapsack framework provides the flexibility to incorporate diversity constraints that prioritize exemplars with desirable attributes, and capacity constraints that ensure that the prompt size respects the provided capacity budgets. The effectiveness of SEER is demonstrated on FinQA and TAT-QA, two real-world benchmarks for HybridQA, where it outperforms previous exemplar selection methods.
Investigating Bias in Multilingual Language Models: Cross-Lingual Transfer of Debiasing Techniques
Oct 16, 2023



This paper investigates the transferability of debiasing techniques across different languages within multilingual models. We examine the applicability of these techniques in English, French, German, and Dutch. Using multilingual BERT (mBERT), we demonstrate that cross-lingual transfer of debiasing techniques is not only feasible but also yields promising results. Surprisingly, our findings reveal no performance disadvantages when applying these techniques to non-English languages. Using translations of the CrowS-Pairs dataset, our analysis identifies SentenceDebias as the best technique across different languages, reducing bias in mBERT by an average of 13%. We also find that debiasing techniques with additional pretraining exhibit enhanced cross-lingual effectiveness for the languages included in the analyses, particularly in lower-resource languages. These novel insights contribute to a deeper understanding of bias mitigation in multilingual language models and provide practical guidance for debiasing techniques in different language contexts.
INFLECT-DGNN: Influencer Prediction with Dynamic Graph Neural Networks
Jul 16, 2023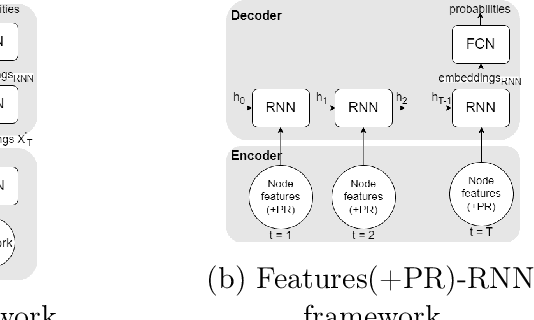

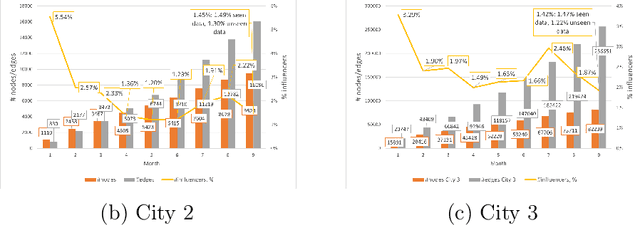
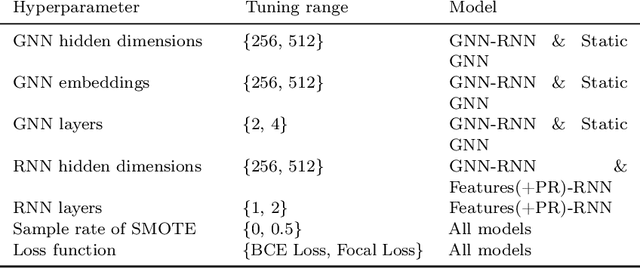
Leveraging network information for predictive modeling has become widespread in many domains. Within the realm of referral and targeted marketing, influencer detection stands out as an area that could greatly benefit from the incorporation of dynamic network representation due to the ongoing development of customer-brand relationships. To elaborate this idea, we introduce INFLECT-DGNN, a new framework for INFLuencer prEdiCTion with Dynamic Graph Neural Networks that combines Graph Neural Networks (GNN) and Recurrent Neural Networks (RNN) with weighted loss functions, the Synthetic Minority Oversampling TEchnique (SMOTE) adapted for graph data, and a carefully crafted rolling-window strategy. To evaluate predictive performance, we utilize a unique corporate data set with networks of three cities and derive a profit-driven evaluation methodology for influencer prediction. Our results show how using RNN to encode temporal attributes alongside GNNs significantly improves predictive performance. We compare the results of various models to demonstrate the importance of capturing graph representation, temporal dependencies, and using a profit-driven methodology for evaluation.