 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach to SME Credit Scoring Integrating Transaction and Ownership Networks
Oct 10, 2025



Small and Medium-sized Enterprises (SMEs) are known to play a vital role in economic growth, employment, and innovation. However, they tend to face significant challenges in accessing credit due to limited financial histories, collateral constraints, and exposure to macroeconomic shocks. These challenges make an accurate credit risk assessment by lenders crucial, particularly since SMEs frequently operate within interconnected firm networks through which default risk can propagate. This paper presents and tests a novel approach for modelling the risk of SME credit, using a unique large data set of SME loans provided by a prominent financial institution. Specifically, our approach employs Graph Neural Networks to predict SME default using multilayer network data derived from common ownership and financial transactions between firms. We show that combining this information with traditional structured data not only improves application scoring performance, but also explicitly models contagion risk between companies. Further analysis shows how the directionality and intensity of these connections influence financial risk contagion, offering a deeper understanding of the underlying processes. Our findings highlight the predictive power of network data, as well as the role of supply chain networks in exposing SMEs to correlated default risk.
Are causal effect estimations enough for optimal recommendations under multitreatment scenarios?
Oct 07, 2024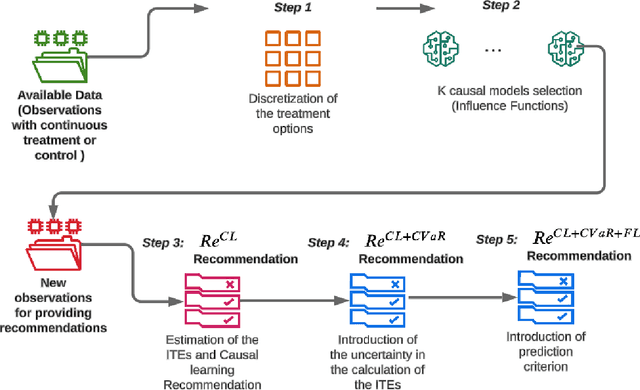
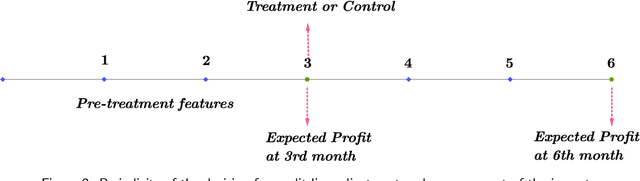

When making treatment selection decisions, it is essential to include a causal effect estimation analysis to compare potential outcomes under different treatments or controls, assisting in optimal selection. However, merely estimating individual treatment effects may not suffice for truly optimal decisions. Our study addressed this issue by incorporating additional criteria, such as the estimations' uncertainty, measured by the conditional value-at-risk, commonly used in portfolio and insurance management. For continuous outcomes observable before and after treatment, we incorporated a specific prediction condition. We prioritized treatments that could yield optimal treatment effect results and lead to post-treatment outcomes more desirable than pretreatment levels, with the latter condition being called the prediction criterion. With these considerations, we propose a comprehensive methodology for multitreatment selection. Our approach ensures satisfaction of the overlap assumption, crucial for comparing outcomes for treated and control groups, by training propensity score models as a preliminary step before employing traditional causal models. To illustrate a practical application of our methodology, we applied it to the credit card limit adjustment problem. Analyzing a fintech company's historical data, we found that relying solely on counterfactual predictions was inadequate for appropriate credit line modifications. Incorporating our proposed additional criteria significantly enhanced policy performance.
Large-scale Time-Varying Portfolio Optimisation using Graph Attention Networks
Jul 22, 2024Apart from assessing individual asset performance, investors in financial markets also need to consider how a set of firms performs collectively as a portfolio. Whereas traditional Markowitz-based mean-variance portfolios are widespread, network-based optimisation techniques have built upon these developments. However, most studies do not contain firms at risk of default and remove any firms that drop off indices over a certain time. This is the first study to incorporate risky firms and use all the firms in portfolio optimisation. We propose and empirically test a novel method that leverages Graph Attention networks (GATs), a subclass of Graph Neural Networks (GNNs). GNNs, as deep learning-based models, can exploit network data to uncover nonlinear relationships. Their ability to handle high-dimensional features and accommodate customised layers for specific purposes makes them particularly appealing for large-scale problems such as mid- and small-cap portfolio optimization. This study utilises 30 years of data on mid-cap firms, creating graphs of firms using distance correlation and the Triangulated Maximally Filtered Graph approach. These graphs are the inputs to a GAT model that we train using custom layers which impose weight and allocation constraints and a loss function derived from the Sharpe ratio, thus directly maximising portfolio risk-adjusted returns. This new model is benchmarked against a network characteristic-based portfolio, a mean variance-based portfolio, and an equal-weighted portfolio. The results show that the portfolio produced by the GAT-based model outperforms all benchmarks and is consistently superior to other strategies over a long period while also being informative of market dynamics.
Attention-based Dynamic Multilayer Graph Neural Networks for Loan Default Prediction
Feb 01, 2024



Whereas traditional credit scoring tends to employ only individual borrower- or loan-level predictors, it has been acknowledged for some time that connections between borrowers may result in default risk propagating over a network. In this paper, we present a model for credit risk assessment leveraging a dynamic multilayer network built from a Graph Neural Network and a Recurrent Neural Network, each layer reflecting a different source of network connection. We test our methodology in a behavioural credit scoring context using a dataset provided by U.S. mortgage financier Freddie Mac, in which different types of connections arise from the geographical location of the borrower and their choice of mortgage provider. The proposed model considers both types of connections and the evolution of these connections over time. We enhance the model by using a custom attention mechanism that weights the different time snapshots according to their importance. After testing multiple configurations, a model with GAT, LSTM, and the attention mechanism provides the best results. Empirical results demonstrate that, when it comes to predicting probability of default for the borrowers, our proposed model brings both better results and novel insights for the analysis of the importance of connections and timestamps, compared to traditional methods.
INFLECT-DGNN: Influencer Prediction with Dynamic Graph Neural Networks
Jul 16, 2023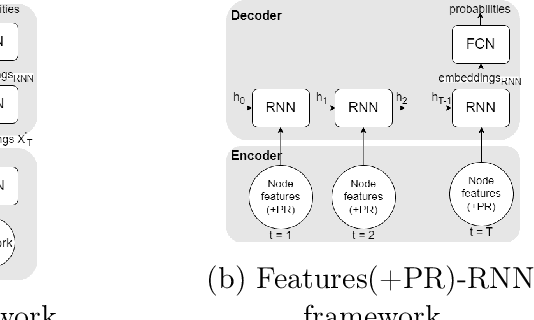

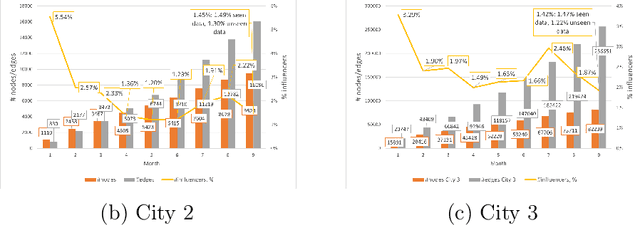
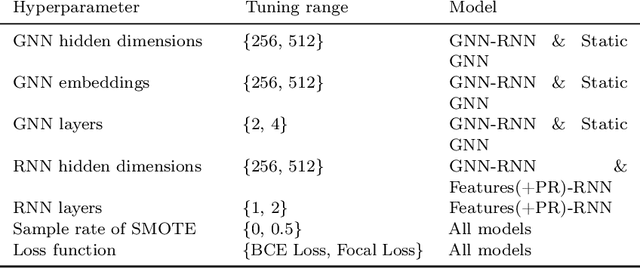
Leveraging network information for predictive modeling has become widespread in many domains. Within the realm of referral and targeted marketing, influencer detection stands out as an area that could greatly benefit from the incorporation of dynamic network representation due to the ongoing development of customer-brand relationships. To elaborate this idea, we introduce INFLECT-DGNN, a new framework for INFLuencer prEdiCTion with Dynamic Graph Neural Networks that combines Graph Neural Networks (GNN) and Recurrent Neural Networks (RNN) with weighted loss functions, the Synthetic Minority Oversampling TEchnique (SMOTE) adapted for graph data, and a carefully crafted rolling-window strategy. To evaluate predictive performance, we utilize a unique corporate data set with networks of three cities and derive a profit-driven evaluation methodology for influencer prediction. Our results show how using RNN to encode temporal attributes alongside GNNs significantly improves predictive performance. We compare the results of various models to demonstrate the importance of capturing graph representation, temporal dependencies, and using a profit-driven methodology for evaluation.
Optimizing Credit Limit Adjustments Under Adversarial Goals Using Reinforcement Learning
Jun 27, 2023Reinforcement learning has been explored for many problems, from video games with deterministic environments to portfolio and operations management in which scenarios are stochastic; however, there have been few attempts to test these methods in banking problems. In this study, we sought to find and automatize an optimal credit card limit adjustment policy by employing reinforcement learning techniques. In particular, because of the historical data available, we considered two possible actions per customer, namely increasing or maintaining an individual's current credit limit. To find this policy, we first formulated this decision-making question as an optimization problem in which the expected profit was maximized; therefore, we balanced two adversarial goals: maximizing the portfolio's revenue and minimizing the portfolio's provisions. Second, given the particularities of our problem, we used an offline learning strategy to simulate the impact of the action based on historical data from a super-app (i.e., a mobile application that offers various services from goods deliveries to financial products) in Latin America to train our reinforcement learning agent. Our results show that a Double Q-learning agent with optimized hyperparameters can outperform other strategies and generate a non-trivial optimal policy reflecting the complex nature of this decision. Our research not only establishes a conceptual structure for applying reinforcement learning framework to credit limit adjustment, presenting an objective technique to make these decisions primarily based on data-driven methods rather than relying only on expert-driven systems but also provides insights into the effect of alternative data usage for determining these modifications.
Multi-Modal Deep Learning for Credit Rating Prediction Using Text and Numerical Data Streams
Apr 21, 2023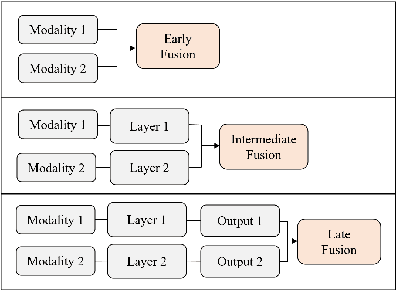



Knowing which factors are significant in credit rating assignment leads to better decision-making. However, the focus of the literature thus far has been mostly on structured data, and fewer studies have addressed unstructured or multi-modal datasets. In this paper, we present an analysis of the most effective architectures for the fusion of deep learning models for the prediction of company credit rating classes, by using structured and unstructured datasets of different types. In these models, we tested different combinations of fusion strategies with different deep learning models, including CNN, LSTM, GRU, and BERT. We studied data fusion strategies in terms of level (including early and intermediate fusion) and techniques (including concatenation and cross-attention). Our results show that a CNN-based multi-modal model with two fusion strategies outperformed other multi-modal techniques. In addition, by comparing simple architectures with more complex ones, we found that more sophisticated deep learning models do not necessarily produce the highest performance; however, if attention-based models are producing the best results, cross-attention is necessary as a fusion strategy. Finally, our comparison of rating agencies on short-, medium-, and long-term performance shows that Moody's credit ratings outperform those of other agencies like Standard & Poor's and Fitch Ratings.
Assessment of creditworthiness models privacy-preserving training with synthetic data
Dec 31, 2022Credit scoring models are the primary instrument used by financial institutions to manage credit risk. The scarcity of research on behavioral scoring is due to the difficult data access. Financial institutions have to maintain the privacy and security of borrowers' information refrain them from collaborating in research initiatives. In this work, we present a methodology that allows us to evaluate the performance of models trained with synthetic data when they are applied to real-world data. Our results show that synthetic data quality is increasingly poor when the number of attributes increases. However, creditworthiness assessment models trained with synthetic data show a reduction of 3\% of AUC and 6\% of KS when compared with models trained with real data. These results have a significant impact since they encourage credit risk investigation from synthetic data, making it possible to maintain borrowers' privacy and to address problems that until now have been hampered by the availability of information.
Influencer Detection with Dynamic Graph Neural Networks
Nov 15, 2022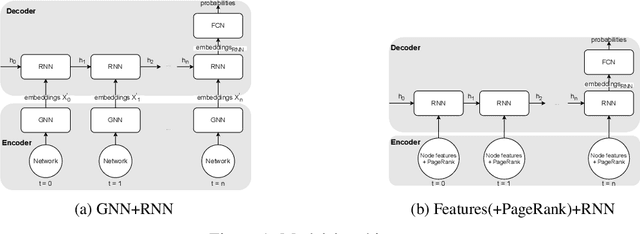
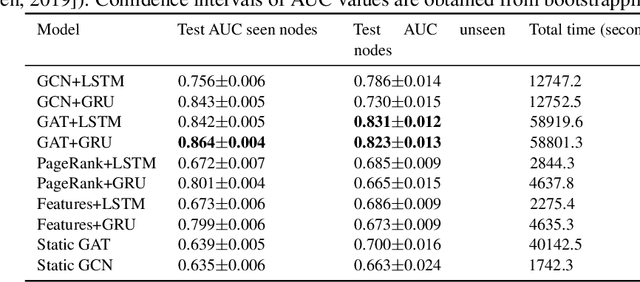
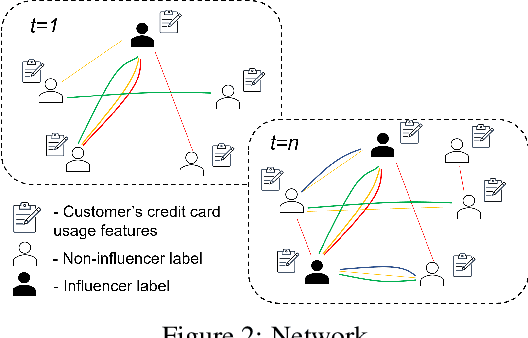
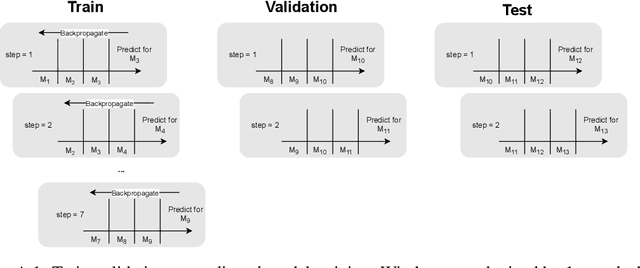
Leveraging network information for prediction tasks has become a common practice in many domains. Being an important part of targeted marketing, influencer detection can potentially benefit from incorporating dynamic network representation. In this work, we investigate different dynamic Graph Neural Networks (GNNs) configurations for influencer detection and evaluate their prediction performance using a unique corporate data set. We show that using deep multi-head attention in GNN and encoding temporal attributes significantly improves performance. Furthermore, our empirical evaluation illustrates that capturing neighborhood representation is more beneficial that using network centrality measures.
On the dynamics of credit history and social interaction features, and their impact on creditworthiness assessment performance
Apr 13, 2022
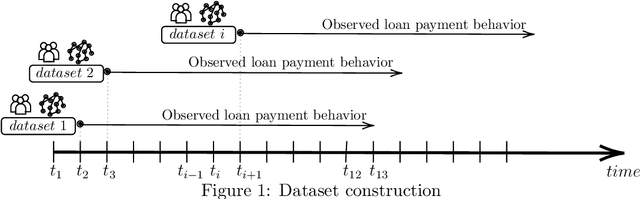
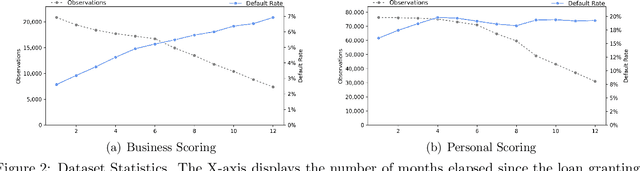
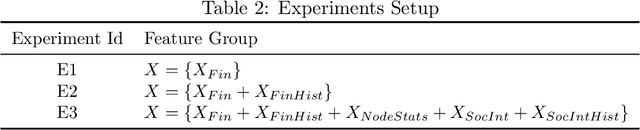
For more than a half-century, credit risk management has used credit scoring models in each of its well-defined stages to manage credit risk. Application scoring is used to decide whether to grant a credit or not, while behavioral scoring is used mainly for portfolio management and to take preventive actions in case of default signals. In both cases, network data has recently been shown to be valuable to increase the predictive power of these models, especially when the borrower's historical data is scarce or not available. This study aims to understand the creditworthiness assessment performance dynamics and how it is influenced by the credit history, repayment behavior, and social network features. To accomplish this, we introduced a machine learning classification framework to analyze 97.000 individuals and companies from the moment they obtained their first loan to 12 months afterward. Our novel and massive dataset allow us to characterize each borrower according to their credit behavior, and social and economic relationships. Our research shows that borrowers' history increases performance at a decreasing rate during the first six months and then stabilizes. The most notable effect on perfomance of social networks features occurs at loan application; in personal scoring, this effect prevails a few months, while in business scoring adds value throughout the study period. These findings are of great value to improve credit risk management and optimize the use of traditional information and alternative data sources.